torch.optim 之如何调整学习率lr_scheduler
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。学习率的调整应该是在优化器更新之后。常见的学习率调整策略有几种:
1、LambdaLR
将每个参数组的学习率设置为初始lr与给定函数的乘积,计算公式是
new_lr = base_lr * lmbda(self.last_epoch)
#函数原型
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
#使用方法
optimizer = optim.SGD([{'params': net.features.parameters()}, # 默认lr是1e-5
{'params': net.classifiter.parameters(), 'lr': 1e-2, "momentum" :0.9,
"weight_decay" :1e-4}],
lr=1e-3)
lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
下图曲线是分别是features和classifiter模块学习率变化曲线

2、MultiplicativeLR
将每个参数组的学习率乘以指定函数中给定的系数,计算公式是:
group[‘lr’] * lmbda(self.last_epoch)
#函数原型
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
#使用方法
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)
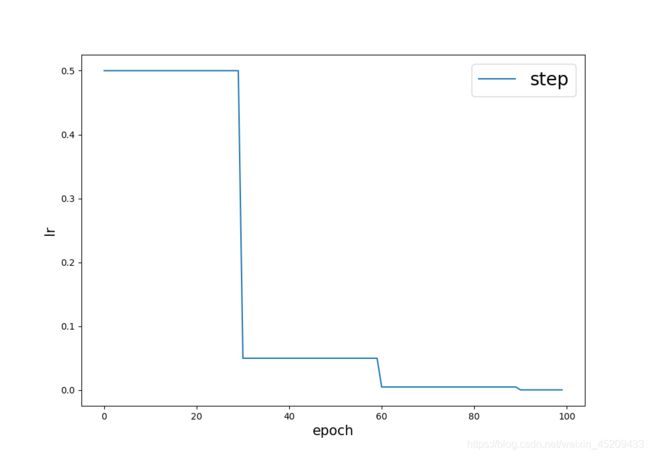
3、StepLR
#函数原型
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
#使用方法
# Assuming optimizer uses lr = 0.5 for all groups
# lr = 0.5 if epoch < 30
# lr = 0.05 if 30 <= epoch < 60
# lr = 0.005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
学习率衰减图:
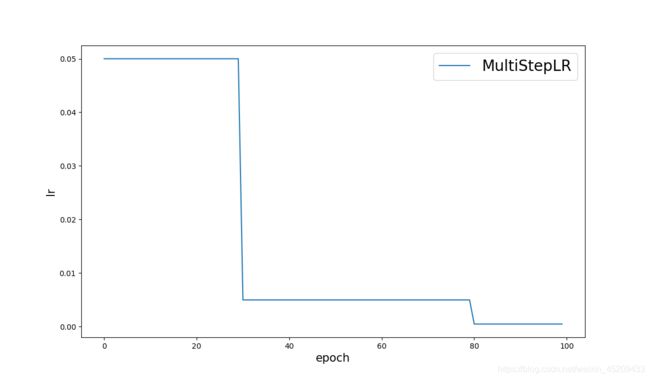
4、MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
5、ExponentialLR
每个参数组的学习率按照gamma曲线每个epoch衰减一次
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
6、ReduceLROnPlateau
该策略能够读取模型的性能指标,当该指标停止改善时,持续关系几个epochs之后,自动减小学习率。
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
# mode(min or max):min指示指标不再减小时降低学习率,max指示指标不再增加时,降低学习率
#factor: new_lr = lr * factor Default: 0.1.
#patience: 观察几个epoch之后降低学习率 Default: 10.
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
7、CosineAnnealingLR(比赛)
让学习率随epoch的变化图类似于cos,更新策略:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max,eta_min=0,last_epoch=-1)
其中,余弦退火学习率中LR的变化是周期性的,T_max是周期的1/2;eta_min(float)表示学习率的最小值,默认为0;last_epoch(int)代表上一个epoch数,该变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设为初始值。
mport torch
from torchvision.models import AlexNet
from torch.optim.lr_scheduler import CosineAnnealingLR
import matplotlib.pyplot as plt
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
scheduler = CosineAnnealingLR(optimizer,T_max=20)
plt.figure()
x = list(range(100))
y = []
for epoch in range(1,101):
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch的学习率:%f" % (epoch,optimizer.param_groups[0]['lr']))
scheduler.step()
y.append(scheduler.get_lr()[0])
# 画出lr的变化
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()

8、CosineAnnealingWarmRestarts(比赛)
和CosineAnnealingLR名字类似,有两个参数,T_0就是初始restart的epoch数目,T_mult就是重启之后因子,默认是1。我觉得可以这样理解,每个restart后,T_0 = T_0 * T_mult。
optimizer = optim.Adam(model.parameters(), lr = 0.1)
lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0 = 20, T_mult=2)
