EasyRL 强化学习笔记 1、2章节(强化学习概述,MDP)
目录
- 第一章 强化学习概述
-
- Reinforcement Learning
-
- 和监督学习对比:
- trajectory与episode
- Sequential Decision Making
-
- state和observation;MDP与POMDP
- Action Spaces
- Major Components of an RL Agent
-
- Policy
- Value Function
- Model
- Policy-based 与 Value-based
- Types of RL Agents
-
- value-based & policy-based
- model-based & model-free
- Exploration and Exploitation
-
- K-armed Bandit
- 总结:
- 第二章 MDP
-
- Markov Process
-
- Markov Property
- Markov Process/Markov Chain
- Markov Reward Process(MRP)
-
- Return and Value function
- Bellman Equation
- Computing Value of a MRP
-
- Monte Carlo
- DP
- Markov Decision Process
-
- Policy
- MP/MRP VS MDP
- Value function
- Bellman Expectation Equation
- Backup Diagram
- Policy Evaluation(Prediction)
- Prediction and Control
- Dynamic Programming
- Policy Evaluation on MDP
- MDP Control
- Policy Iteration
-
- Value Iteration
- 总结:
- 一些思考:
主要参考资料:EasyRL,写的超级仔细!我这里只是摘抄了其中的内容,强烈建议看原文档!
第一章 强化学习概述
Reinforcement Learning
和监督学习对比:
- 输入是序列数据,并不满足独立同分布。
- agent需要不断试错 trial-and-error exploration。
- 没有label标签告诉模型哪个action是正确的,只有reward,并且是延迟的。
- 监督学习的数据是人工标注的,相当于有了一个上限。但RL有更大的潜力,有可超越人类、
trajectory与episode
- trajectory:agent和环境交互,得到的一堆观测数据。即状态和动作的一个序列。 τ = ( s 0 , a 0 , s 1 , a 1 , . . . ) \tau = (s_0,a_0,s_1,a_1,...) τ=(s0,a0,s1,a1,...)
- 一场游戏:episode(回合)或trial(试验)
Sequential Decision Making
- 在一个强化学习环境里面,agent 的目的就是选取一系列的动作来极大化它的奖励,所以这些采取的动作必须有长期影响。但在这个过程里面,它的奖励其实是被延迟了,就是说你现在采取的某一步决策可能要等到时间很久过后才知道这一步到底产生了什么样的影响。
state和observation;MDP与POMDP
状态(state)s 是对世界的完整描述,不会隐藏世界的信息。观测(observation)o 是对状态的部分描述,可能会遗漏一些信息。 H t = O 1 , R 1 , A 1 , . . . , A t − 1 , O t , R t H_t = O_1,R_1,A_1,...,A_{t-1},O_t,R_t Ht=O1,R1,A1,...,At−1,Ot,Rt S t = f ( H t ) S_t = f(H_t) St=f(Ht)- 当 agent 的状态跟环境的状态等价的时候,我们就说这个环境是
full observability,就是全部可以观测。换句话说,当 agent 能够观察到环境的所有状态时,我们称这个环境是完全可观测的(fully observed)。在这种情况下面,强化学习通常被建模成一个Markov decision process(MDP)的问题: O t = S t e = S t a O_t = S_t^e = S_t^a Ot=Ste=Sta 。(观测=环境状态=agent状态) - 当agent只能看到部分的观测,称为部分可观测的(partially observed)。在这种情况下面,强化学习通常被建模成一个
POMDP的问题。(如棋牌游戏,只能看到牌面上的牌) 部分可观测马尔可夫决策过程(Partially Observable Markov Decision Processes, POMDP)是一个马尔可夫决策过程的泛化。POMDP 依然具有马尔可夫性质,但是假设智能体无法感知环境的状态 s,只能知道部分观测值 o。比如在自动驾驶中,智能体只能感知传感器采集的有限的环境信息。通常用七元组表示 ( S , A , T , R , Ω , O , γ ) (S,A,T,R,\Omega,O,\gamma) (S,A,T,R,Ω,O,γ)
Action Spaces
- 离散动作空间(discrete action spaces):agent的数量是有限的。如:走迷宫机器人只能走东南西北四个方向。
- 连续动作空间(continuous action spaces) :在连续空间中,动作是实值的向量。如:机器人可以360°移动。
Major Components of an RL Agent
-
策略函数(policy function),agent 会用这个函数来选取下一步的动作。
-
价值函数(value function),我们用价值函数来对当前状态进行估价,它就是说你进入现在这个状态,可以对你后面的收益带来多大的影响。当这个价值函数大的时候,说明你进入这个状态越有利。
-
模型(model),模型表示了 agent 对这个环境的状态进行了理解,它决定了这个世界是如何进行的。
Policy
- 输入为状态,输出为采取的action。分为
stochastic policy(随机性策略)和deterministic policy(确定性策略)。 - stochastic policy(随机性策略):输出的是动作的概率,然后对概率分布进行采样获取action。
- deterministic policy(确定性策略):直接取概率最大的动作。
- 通常情况下,强化学习一般使用随机性策略。① 在学习时可以通过引入一定随机性来更好地探索环境;② 随机性策略的动作具有多样性。采用确定性策略的智能体总是对同样的环境做出相同的动作,会导致它的策略很容易被对手预测。
Value Function
价值函数是未来奖励的一个预测,用来评估状态的好坏。
- 价值函数表示,在我们已知某一个策略函数时,可以得到多少奖励。
v π ( s ) ≐ E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] \mathrm{v}_{\pi}(\mathrm{s}) \doteq \mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}\right]=\mathbb{E}_{\pi}\left[\sum_{\mathrm{k}=0}^{\infty} \gamma^{\mathrm{k}} \mathrm{R}_{\mathrm{t}+\mathrm{k}+1} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}\right] vπ(s)≐Eπ[Gt∣St=s]=Eπ[∑k=0∞γkRt+k+1∣St=s], for all s ∈ S \mathrm{s} \in \mathcal{S} s∈S - Q函数(未来可以获得多少奖励取决于当前的状态和当前的行为):
q π ( s , a ) ≐ E π [ G t ∣ S t = s , A t = a ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] \mathrm{q}_{\pi}(\mathrm{s}, \mathrm{a}) \doteq \mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right]=\mathbb{E}_{\pi}\left[\sum_{\mathrm{k}=0}^{\infty} \gamma^{\mathrm{k}} \mathrm{R}_{\mathrm{t}+\mathrm{k}+1} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right] qπ(s,a)≐Eπ[Gt∣St=s,At=a]=Eπ[∑k=0∞γkRt+k+1∣St=s,At=a]
这个 Q 函数是强化学习算法里面要学习的一个函数。因为当我们得到这个 Q 函数后,进入某一种状态,它最优的行为就可以通过这个 Q 函数来得到。
Model
模型决定了下一个状态会是什么样的,就是说下一步的状态取决于你当前的状态以及你当前采取的行为。它由两个部分组成:
- 概率:转移状态之间是怎么转移的 P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{\mathrm{ss}^{\prime}}^{\mathrm{a}}=\mathbb{P}\left[\mathrm{S}_{\mathrm{t}+1}=\mathrm{s}^{\prime} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right] Pss′a=P[St+1=s′∣St=s,At=a]
- 奖励函数:当采取了某个行为,可以获得多大的奖励
R s a = E [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}_{\mathrm{s}}^{\mathrm{a}}=\mathbb{E}\left[\mathrm{R}_{\mathrm{t}+1} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right] Rsa=E[Rt+1∣St=s,At=a]
Policy-based 与 Value-based
- 基于策略的(policy-based)RL:每一个状态得到一个最佳的行为(action)。
- 基于价值的(value-based)RL:每一个状态对应的value。
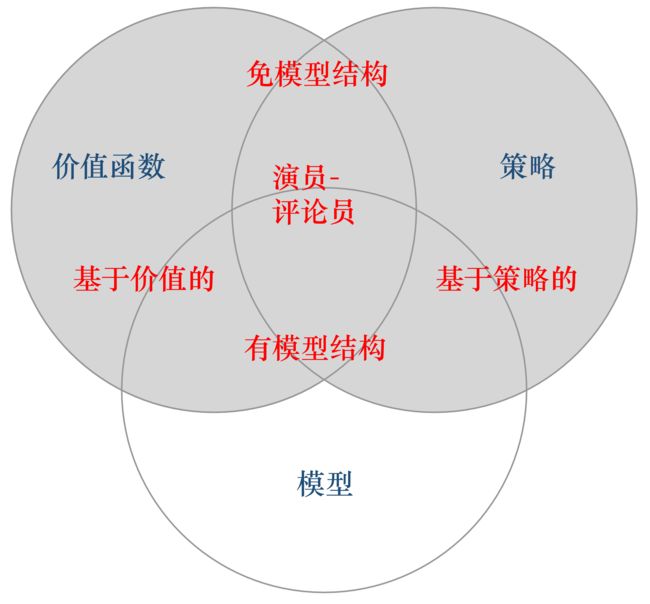
Types of RL Agents
value-based & policy-based
1.基于价值的 agent(value-based agent)。
- 这一类 agent 显式地学习的是价值函数,
- 隐式地学习了它的策略。策略是从我们学到的价值函数里面推算出来的。
2.基于策略的 agent(policy-based agent)。
- 这一类 agent 直接去学习 policy,就是说你直接给它一个状态,它就会输出这个动作的概率。
- 在基于策略的 agent 里面并没有去学习它的价值函数。
3.二者结合:Actor-Critic agent。这一类 agent 把它的策略函数和价值函数都学习了,然后通过两者的交互得到一个最佳的行为。
Q: 基于策略迭代和基于价值迭代的强化学习方法有什么区别?
-
在基于策略迭代的强化学习方法中,智能体会制定一套
动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。 -
而在基于价值迭代的强化学习方法中,智能体不需要制定显式的策略,它维护一个
价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于行为集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。 -
基于
价值迭代的强化学习算法有 Q-learning、 Sarsa 等,而基于策略迭代的强化学习算法有策略梯度算法等。此外,Actor-Critic算法同时使用策略和价值评估来做出决策,其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。
model-based & model-free
model-based(有模型) RL agent,它通过学习这个状态的转移来采取动作。model-free(免模型) RL agent,它没有去直接估计这个状态的转移,也没有得到环境的具体转移变量。它通过学习价值函数和策略函数进行决策。Model-free 的模型里面没有一个环境转移的模型。
具体来说,当智能体知道状态转移函数 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at)和奖励函数 R ( s t , a t ) R(s_t,a_t) R(st,at)后,它就能知道在某一状态下执行某一动作后能带来的奖励和环境的下一状态,这样智能体就不需要在真实环境中采取动作,直接在虚拟世界中学习和规划策略即可。这种学习方法称为有模型学习。
然而在实际应用中,智能体并不是那么容易就能知晓 MDP 中的所有元素的。通常情况下,状态转移函数和奖励函数很难估计,甚至连环境中的状态都可能是未知的,这时就需要采用model-free学习。免模型学习没有对真实环境进行建模,智能体只能在真实环境中通过一定的策略来执行动作,等待奖励和状态迁移,然后根据这些反馈信息来更新行为策略,这样反复迭代直到学习到最优策略。
总结:
有模型学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习。① 具有想象能力:在免模型学习中,智能体只能一步一步地采取策略,等待真实环境的反馈;而model-based可以在虚拟世界中预测出所有将要发生的事,并采取对自己最有利的策略。免模型学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。① 通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。② 泛化性要优于有模型学习,原因是有模型学习算需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。(DQN,DDPG,A3C,PPO)
自己的理解:
- model-free:相当于在线学习,能获取用户真实反馈。
- model-based:可以看作是建立了environment simulator。不过并不局限于此,关键是对环境转移概率建模。
- 例子:①
model-free,比如Q-learning的思想,我只能估计在状态S的预估值V(S)是多少,但不知道我给了一个动作a后,环境会怎么变动。我们给一个动作a后,我们要等,要等!环境给出一个真实的S’后,我们才能估计下一步V(S’)。②model-based,建模了环境,特指:我们想象,在环境S下,当我们做出动作a后,它会(以多大概率)转移到状态S1,S2, S3,我们在S1,2,3处都有V(S1),V(S2),V(S3)。于是这可以帮助我们更好的决策要不要做动作a。
目前,大部分深度强化学习方法都采用了model-free学习,这是因为:
- 免模型学习更为简单直观且有丰富的开源资料,像 DQN、AlphaGo 系列等都采用免模型学习;
- 在目前的强化学习研究中,大部分情况下环境都是静态的、可描述的,智能体的状态是离散的、可观察的(如 Atari 游戏平台),这种相对简单确定的问题并不需要评估状态转移函数和奖励函数,直接采用免模型学习,使用大量的样本进行训练就能获得较好的效果。
不过IRS中,通常使用的是model-based方法,模拟出用户、生成用户的,都能叫model-based。主要是因为线上模拟太耗时了,也没有合适的数据集。
Exploration and Exploitation
- 探索是说我们怎么去探索这个环境,通过尝试不同的行为来得到一个最佳的策略,得到最大奖励的策略。
- 利用是说我们不去尝试新的东西,就采取已知的可以得到很大奖励的行为。
比如外出吃饭,exploitation就是选择之前吃过的感觉还不错的店;exploration就是选择一家新的没有吃过的餐厅。
K-armed Bandit
单步强化学习模型:K-臂赌博机(K-armed bandit),也称多臂赌博机(Multi-armed bandit)
总结:
- 深度强化学习(Deep Reinforcement Learning):不需要手工设计特征,仅需要输入State让系统直接输出Action的一个end-to-end training的强化学习方法。通常使用神经网络来拟合 value function 或者 policy network。
- 强化学习的通俗理解?
答:environment跟reward function不是我们可以控制的,environment 跟 reward function 是在开始学习之前,就已经事先给定的。我们唯一能做的事情是调整 actor 里面的 policy,使得 actor 可以得到最大的 reward。Actor 里面会有一个 policy, 这个 policy 决定了actor 的行为。Policy 就是给一个外界的输入,然后它会输出 actor 现在应该要执行的行为。 - 高冷的面试官: 根据你上面介绍的内容,你认为强化学习的使用场景有哪些呢?
答: 七个字的话就是多序列决策问题。或者说是对应的模型未知,需要通过学习逐渐逼近真实模型的问题并且当前的动作会影响环境的状态,即服从马尔可夫性的问题。同时应满足所有状态是可重复到达的(满足可学习型的)。 - Model-free: 不需要知道状态之间的转移概率(transition probability);Model-based: 需要知道状态之间的转移概率
第二章 MDP
在马尔可夫决策过程中,它的环境是全部可以观测的(fully observable)。但是很多时候环境里面有些量是不可观测的,但是这个部分观测的问题也可以转换成一个 MDP 的问题。
Markov Process
Markov Property
- 如果一个状态转移是符合马尔可夫的,那就是说一个状态的下一个状态只取决于它当前状态,而跟它当前状态之前的状态都没有关系。
- 马尔可夫性质是所有马尔可夫过程的基础。
Markov Process/Markov Chain
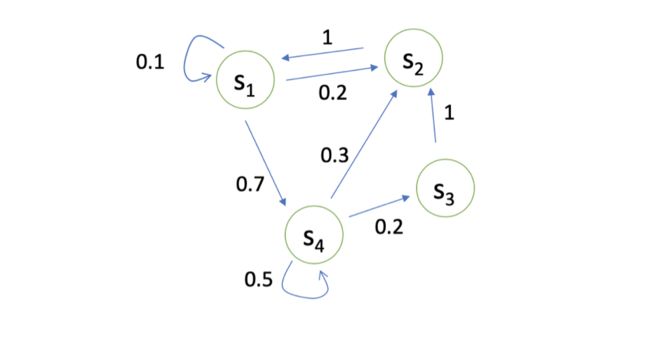
图中每个状态都可以互相转移,我们可以用一个状态转移矩阵(State Transition Matrix)P来描述状态转移。

Markov Reward Process(MRP)
马尔可夫奖励过程(Markov Reward Process, MRP)是马尔可夫链再加上了一个奖励函数。- 奖励函数 R R R 是一个期望,就是说当你到达某一个状态的时候,可以获得多大的奖励。
Return and Value function
Return(回报)说的是把奖励进行折扣后所获得的收益。Return 可以定义为奖励的逐步叠加,如下式所示:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + … + γ T − t − 1 R T \mathrm{G}_{\mathrm{t}}=\mathrm{R}_{\mathrm{t}+1}+\gamma \mathrm{R}_{\mathrm{t}+2}+\gamma^{2} \mathrm{R}_{\mathrm{t}+3}+\gamma^{3} \mathrm{R}_{\mathrm{t}+4}+\ldots+\gamma^{\mathrm{T}-\mathrm{t}-1} \mathrm{R}_{\mathrm{T}} Gt=Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+…+γT−t−1RT- 当我们有了 return 过后,就可以定义一个状态的价值了,就是
state value function。对于 MRP,state value function 被定义成是 return 的期望,如下式所示:
V t ( s ) = E [ G t ∣ s t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … + γ T − t − 1 R T ∣ s t = s ] \begin{aligned} \mathrm{V}_{\mathrm{t}}(\mathrm{s}) &=\mathbb{E}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{s}_{\mathrm{t}}=\mathrm{s}\right] \\ &=\mathbb{E}\left[\mathrm{R}_{\mathrm{t}+1}+\gamma \mathrm{R}_{\mathrm{t}+2}+\gamma^{2} \mathrm{R}_{\mathrm{t}+3}+\ldots+\gamma^{\mathrm{T}-\mathrm{t}-1} \mathrm{R}_{\mathrm{T}} \mid \mathrm{s}_{\mathrm{t}}=\mathrm{s}\right] \end{aligned} Vt(s)=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+…+γT−t−1RT∣st=s]
期望就是说从这个状态开始,你有可能获得多大的价值。
Bellman Equation
Bellman Equation 定义了当前状态跟未来状态之间的这个关系。
V ( s ) = R ( s ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s ) V ( s ′ ) \mathrm{V}(\mathrm{s})=\mathrm{R}(\mathrm{s})+\gamma \sum_{\mathrm{s}^{\prime} \in \mathrm{S}} \mathrm{P}\left(\mathrm{s}^{\prime} \mid \mathrm{s}\right) \mathrm{V}\left(\mathrm{s}^{\prime}\right) V(s)=R(s)+γ∑s′∈SP(s′∣s)V(s′)
- 未来打了折扣的奖励加上当前立刻可以得到的奖励,就组成了这个 Bellman Equation。
可以写成矩阵的形式:

Bellman Equation 就是当前状态与未来状态的迭代关系,表示当前状态的值函数可以通过下个状态的值函数来计算。Bellman Equation 因其提出者、动态规划创始人 Richard Bellman 而得名 ,也叫作“动态规划方程”。
Computing Value of a MRP
我们可以通过迭代的方法来解这种状态非常多的 MRP(large MRPs),比如说:
- 动态规划的方法,
- 蒙特卡罗的办法(通过采样的办法去计算它),
- 时序差分学习(Temporal-Difference Learning)的办法。 Temporal-Difference Learning· 叫 TD Leanring,它是动态规划和蒙特卡罗的一个结合。
Monte Carlo

就是从当前状态开始,重复很多次,记录下return,最后算平均。
DP

通过 bootstrapping(自举)的办法,然后去不停地迭代这个 Bellman Equation。当这个最后更新的状态跟你上一个状态变化并不大的时候,更新就可以停止。
动态规划的方法基于后继状态值的估计来更新状态值的估计(算法二中的第 3 行用 V’ 来更新 V )。也就是说,它们根据其他估算值来更新估算值。我们称这种基本思想为 bootstrapping。
Bootstrap 本意是“解靴带”;这里是在使用徳国文学作品《吹牛大王历险记》中解靴带自助(拔靴自助)的典故,因此将其译为“自举”。
Markov Decision Process
相对于 MRP,马尔可夫决策过程(Markov Decision Process)多了一个 decision,其它的定义跟 MRP 都是类似的。
- 多了一个决策,相当于多了一个动作action
- 状态转移也多了一个条件;价值函数也多了一个条件。(action)
Policy
- policy定义了在某一个状态应该采取什么样的动作。
- 知道当前状态过后,我们可以把当前状态带入 policy function,然后就会得到一个概率。
MP/MRP VS MDP
- 马尔可夫过程的转移是直接就决定。比如当前状态是 s,那么就直接通过这个转移概率决定了下一个状态是什么。
- 但对于 MDP,它的中间多了一层动作 a。即这个当前状态跟未来状态转移过程中这里多了一层决策性,这是 MDP 跟之前的马尔可夫过程很不同的一个地方。在马尔可夫决策过程中,动作是由 agent 决定,所以多了一个 component,agent 会采取动作来决定未来的状态转移。
Value function
状态-价值函数(state-value function): v π ( s ) = E π [ G t ∣ s t = s ] \mathrm{v}^{\pi}(\mathrm{s})=\mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{s}_{\mathrm{t}}=\mathrm{s}\right] vπ(s)=Eπ[Gt∣st=s]
Q函数action-value function: q π ( s , a ) = E π [ G t ∣ s t = s , A t = a ] \mathrm{q}^{\pi}(\mathrm{s}, \mathrm{a})=\mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{s}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right] qπ(s,a)=Eπ[Gt∣st=s,At=a]
定义的是在某一个状态采取某一个动作,它有可能得到的这个 return 的一个期望。
(二者的区别就是,价值函数未考虑action,Q函数考虑到了。把在状态s时能采取的动作action的概率 乘上 在状态s时采取的动作action获得的Q值,就得到了价值函数啦)
对 Q 函数中的动作函数进行加和,就可以得到价值函数: v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) \mathrm{v}^{\pi}(\mathrm{s})=\sum_{\mathrm{a} \in \mathrm{A}} \pi(\mathrm{a} \mid \mathrm{s}) \mathrm{q}^{\pi}(\mathrm{s}, \mathrm{a}) vπ(s)=∑a∈Aπ(a∣s)qπ(s,a)
Bellman Expectation Equation
我们可以把状态-价值函数和 Q 函数拆解成两个部分:即时奖励(immediate reward) 和后续状态的折扣价值(discounted value of successor state)。
Bellman Expectation Equation:
- 把以下两个式子互相代入:
- v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) \mathrm{v}^{\pi}(\mathrm{s})=\sum_{\mathrm{a} \in \mathrm{A}} \pi(\mathrm{a} \mid \mathrm{s}) \mathrm{q}^{\pi}(\mathrm{s}, \mathrm{a}) vπ(s)=∑a∈Aπ(a∣s)qπ(s,a)
- q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) \mathrm{q}^{\pi}(\mathrm{s}, \mathrm{a})=\mathrm{R}_{\mathrm{s}}^{\mathrm{a}}+\gamma \sum_{\mathrm{s}^{\prime} \in \mathrm{S}} \mathrm{P}\left(\mathrm{s}^{\prime} \mid \mathrm{s}, \mathrm{a}\right) \mathrm{v}^{\pi}\left(\mathrm{s}^{\prime}\right) qπ(s,a)=Rsa+γ∑s′∈SP(s′∣s,a)vπ(s′)
把(2)代入(1):
- v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) ) \mathrm{v}^{\pi}(\mathrm{s})=\sum_{\mathrm{a} \in \mathrm{A}} \pi(\mathrm{a} \mid \mathrm{s})\left(\mathrm{R}(\mathrm{s}, \mathrm{a})+\gamma \sum_{\mathrm{s}^{\prime} \in \mathrm{S}} \mathrm{P}\left(\mathrm{s}^{\prime} \mid \mathrm{s}, \mathrm{a}\right) \mathrm{v}^{\pi}\left(\mathrm{s}^{\prime}\right)\right) vπ(s)=∑a∈Aπ(a∣s)(R(s,a)+γ∑s′∈SP(s′∣s,a)vπ(s′))
(右边表示,在s下采取a时获得的Q值)
把(1)代入(2):
- q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) \mathrm{q}^{\pi}(\mathrm{s}, \mathrm{a})=\mathrm{R}(\mathrm{s}, \mathrm{a})+\gamma \sum_{\mathrm{s}^{\prime} \in \mathrm{S}} \mathrm{P}\left(\mathrm{s}^{\prime} \mid \mathrm{s}, \mathrm{a}\right) \sum_{\mathrm{a}^{\prime} \in \mathrm{A}} \pi\left(\mathrm{a}^{\prime} \mid \mathrm{s}^{\prime}\right) \mathrm{q}^{\pi}\left(\mathrm{s}^{\prime}, \mathrm{a}^{\prime}\right) qπ(s,a)=R(s,a)+γ∑s′∈SP(s′∣s,a)∑a′∈Aπ(a′∣s′)qπ(s′,a′)
Backup Diagram
感觉这部分和贝尔曼方程很类似呀。

Policy Evaluation(Prediction)
预测当前采取的策略最终会产生多少价值。

Prediction and Control
- 预测问题是给定一个 policy,我们要确定它的 value function 是多少。
- 而控制问题是在没有 policy 的前提下,我们要确定最优的 value function 以及对应的决策方案。
Dynamic Programming
动态规划(Dynamic Programming,DP)适合解决满足如下两个性质的问题:
最优子结构(optimal substructure)。最优子结构意味着,我们的问题可以拆分成一个个的小问题,通过解决这个小问题,最后,我们能够通过组合小问题的答案,得到大问题的答案,即最优的解。重叠子问题(Overlapping subproblems)。重叠子问题意味着,子问题出现多次,并且子问题的解决方案能够被重复使用。
MDP 是满足动态规划的要求的:
- 在 Bellman equation 里面,我们可以把它分解成一个递归的结构。当我们把它分解成一个递归的结构的时候,如果我们的子问题子状态能得到一个值,那么它的未来状态因为跟子状态是直接相连的,那我们也可以继续推算出来。
- 价值函数就可以储存并重用它的最佳的解。
动态规划应用于 MDP 的规划问题(planning)而不是学习问题(learning),我们必须对环境是完全已知的(Model-Based),才能做动态规划,直观的说,就是要知道状态转移概率和对应的奖励才行。
Policy Evaluation on MDP
- Policy evaluation 就是给定一个 MDP 和一个 policy,我们可以获得多少的价值。
- 核心思想:把 Bellman expectation backup 拿出来反复迭代,然后就会得到一个收敛的价值函数的值
MDP Control
如果我们只有一个 MDP,如何去寻找一个最佳的策略,然后可以得到一个最佳价值函数(Optimal Value Function)。
π ∗ ( s ) = arg max π v π ( s ) \pi^{*}(\mathrm{s})=\underset{\pi}{\arg \max } \mathrm{v}^{\pi}(\mathrm{s}) π∗(s)=πargmaxvπ(s)
策略搜索方法:
- 最简单的:穷举
- policy iteration
- value iteration
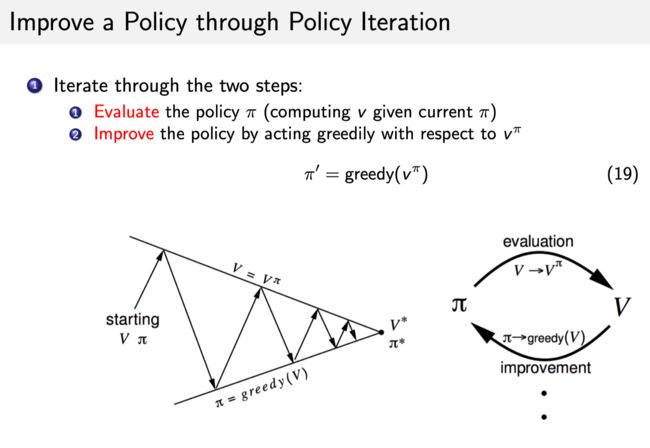
Policy Iteration
Policy iteration 由两个步骤组成:policy evaluation 和 policy improvement。
Value Iteration
我们从另一个角度思考问题,动态规划的方法将优化问题分成两个部分:
- 第一步执行的是最优的 action;
- 之后后继的状态每一步都按照最优的 policy 去做,那么我最后的结果就是最优的。

对比: - Policy Iteration 分两步,首先进行 policy evaluation,即对当前已经搜索到的策略函数进行一个估值。得到估值过后,进行 policy improvement,即把 Q 函数算出来,我们进一步进行改进。不断重复这两步,直到策略收敛。
- Value iteration 直接把 Bellman Optimality Equation 拿进来,然后去寻找最佳的 value function,没有 policy function 在这里面。当算出 optimal value function 过后,我们再来提取最佳策略。
总结:
- 一个状态的价值 V t ( s ) {V}_{\mathrm{t}}(\mathrm{s}) Vt(s),就是 G t G_t Gt。贝尔曼方程也是描述当前状态价值和未来状态价值的公式。(分为:基于价值函数的贝尔曼方程和基于动作值的贝尔曼方程)
- 求贝尔曼等式方法:① 蒙特卡洛方法:用于计算价值函数的值。取平均。② 动态规划法:一直迭代贝尔曼方程直到收敛。③ 二者结合:TD
- MDP中的prediction问题:给定MDP和policy,计算价值函数。
- MDP中的control问题:给定MDP,输出最佳价值函数和最佳策略。
- 马尔科夫过程是一个二元组 < S , P >
- 马尔科夫决策过程是一个五元组KaTeX parse error: Undefined control sequence: \gmma at position 10:
- 求解马尔科夫决策过程=求解贝尔曼等式
一些思考:
- 强化学习和MDP的关系:MDP是用于形式化序列决策问题的一个框架,而强化学习可以理解为是用于求解MDP或者它的扩展形式的一类方法,所以强化学习针对的是序列决策问题的求解。
- 序列决策问题可以理解为是当前的action不仅仅影响当前的rewards,同时也会影响到后续的state和rewards的情况下,通过执行action最大化rewards。
- 在
model-free方法中,① policy-based的方法直接maximize expected cumulative reward,例如policy-gradient通过计算expected cumulative reward对parameter的gradient,然后进行gradient ascent。② 而value-based的方法直接评估state好坏,或者某个state下做action的好坏,也就是直观地从序列决策任务的定义下手,找到最优的action。 - 在
model-based方法中,可以通过估计transition matrix或者reward,基于它们进行planning,或者进行value function/policy的学习。
