【论文笔记】Are We Ready for Vision-Centric Driving Streaming Perception? The ASAP Benchmark
原文链接:https://arxiv.org/abs/2212.08914
3. ASAP基准
3.1 自动驾驶流感知(ASAP)
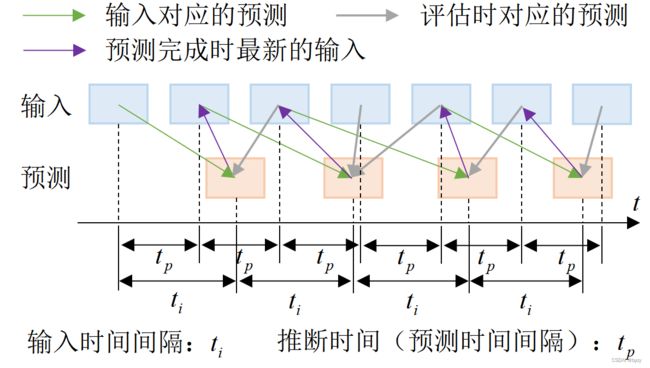
ASAP以在线方式进行评估:即使当前帧样本的处理还未完成,也进行评估。
给出流式输入 { X i } i = 1 T \{X_i\}_{i=1}^T {Xi}i=1T,其中 X i X_i Xi是 t i t_i ti时刻的环视图像。感知算法需要对输入进行在线响应,生成预测 { Y ^ j } j = 1 M \{\hat{Y}_j\}_{j=1}^M {Y^j}j=1M。其中 Y ^ j \hat{Y}_j Y^j是 t j t_j tj时刻的预测。一般来说预测时刻与输入时刻并不同步,且往往模型推断速率会小于输入速率。
真实结果 Y i Y_i Yi期望与最近的预测相匹配,即 ( Y i , Y ^ θ ( i ) ) (Y_i,\hat{Y}_{\theta(i)}) (Yi,Y^θ(i)),其中 θ ( i ) = arg max j : t j < t i t j \theta(i)=\arg\max_{j:t_j
下图为ASAP基准流式评估的例子:
3.2 nuScenes-H
由于nuScenes数据集的标注帧率(关键帧帧率)是2Hz,慢于多数基于相机的3D检测器,不适合区分不同延迟的模型,因此本文将12Hz的原始图像数据作为流式输入,但需要将关键帧的标注扩展到非关键帧上。给定 t s t_s ts和 t e t_e te时刻的相邻关键帧标注,则 t t t时刻( t s < t < t e t_s
T r ( t ) = t e − t t e − t s T r ( t s ) + t − t s t e − t s T r ( t e ) R ( t ) = F s ( R ( t s ) , R ( t e ) , t e − t t e − t s ) \begin{aligned}Tr(t)&=\frac{t_e-t}{t_e-t_s}Tr(t_s)+\frac{t-t_s}{t_e-t_s}Tr(t_e)\\R(t)&=F_s(R(t_s),R(t_e),\frac{t_e-t}{t_e-t_s})\end{aligned} Tr(t)R(t)=te−tste−tTr(ts)+te−tst−tsTr(te)=Fs(R(ts),R(te),te−tste−t)其中 T r ( t ) Tr(t) Tr(t)和 R ( t ) R(t) R(t)分别是物体在 t t t时刻的的位置和旋转角。并且为避免欧拉角表达中可能出现的“万向锁”(Gimbal Lock),使用四元数表达旋转角 R ( t ) R(t) R(t),且 F s F_s Fs表示球面线性插值。nuScenes中提供的跟踪ID可以用于匹配相邻关键帧中的物体。
当某物体不在两个相邻关键帧中同时可见时,中间的非关键帧会忽略其标注。为减轻这一问题,本文通过在验证集的关键帧(2Hz)上使用激光雷达训练CenterPoint网络,在训练集的所有帧(20Hz)上预测边界框来建立一个时间数据库 { ( t i , Y i L ) } i = 1 n \{(t_i,Y_i^L)\}_{i=1}^n {(ti,YiL)}i=1n,保存时间 { t i } i = 1 n \{t_i\}_{i=1}^n {ti}i=1n上的预测边界框 { Y i L } i = 1 n \{Y_i^L\}_{i=1}^n {YiL}i=1n。可以按下式查询时间数据库中 t t t时刻的预测:
Y query = Y j L ( j = arg min i ∣ t i − t ∣ ) Y_{\textup{query}}=Y_j^L(j=\arg\min_i|t_i-t|) Yquery=YjL(j=argimin∣ti−t∣)然后,进行插值标注和 Y query Y_{\textup{query}} Yquery之间的IoU匹配,过滤掉 Y query Y_{\textup{query}} Yquery中的冗余预测,剩余的预测会作为 t t t时刻的标注。
3.3 SPUR评估指标
由于nuScenes的离线评估指标不能之间用于流式系统,因此本文设计了受限计算下的流式感知(SPUR)评估指标,全面地评估3D检测器的流式性能。
流式指标:ATE、ASE、AOE、AAE、AVE、NDS和mAP是官方评估指标。除了AVE以外,所有指标均很容易延伸为流式指标。由于流式评估存在延迟,预测与真值之间存在移位,导致TP多为低速或静止物体;而AVE仅测量TP物体,会导致流式速度误差低于离线速度误差。因此本文使用原始的离线AVE评估速度,其余各项使用3.1节所述的流式评估衡量(指标名称分别加上“-S”后缀)。NDS-S指标的计算与原来类似,即 NDS-S = 1 10 [ 5 mAP-S + ∑ mTP ∈ T P ( 1 − min ( 1 , mTP ) ) ] , T P = { ATE-S , ASE-S , AOE-S , AAE-S , AVE } \textup{NDS-S}=\frac{1}{10}[5\textup{mAP-S}+\sum_{\textup{mTP}\in\mathbb{TP}}(1-\min(1,\textup{mTP}))],\mathbb{TP}=\{\textup{ATE-S},\textup{ASE-S},\textup{AOE-S},\textup{AAE-S},\textup{AVE}\} NDS-S=101[5mAP-S+mTP∈TP∑(1−min(1,mTP))],TP={ATE-S,ASE-S,AOE-S,AAE-S,AVE}
受限计算下的评估:不同的计算资源会影响流式性能,本文考虑两种计算受限:
- 使用不同性能的GPU评估3D检测器,已比较在不同平台下的流式性能;
- 在GPU同时进行其他感知任务时评估3D检测器,以分析在计算资源共享情况下的流式性能波动。
3.4 ASAP基本方案
由于模型延迟,预测结果会相对真值存在移位。为了减轻这一问题,可以进行未来状态的预测,来补偿延迟。针对未来状态预测,本文提出基于速度的基本方案(通过估计的物体运动来预测未来状态;如下左图所示)和基于学习的基本方案(直接估计物体的未来位置;如下右图所示)。
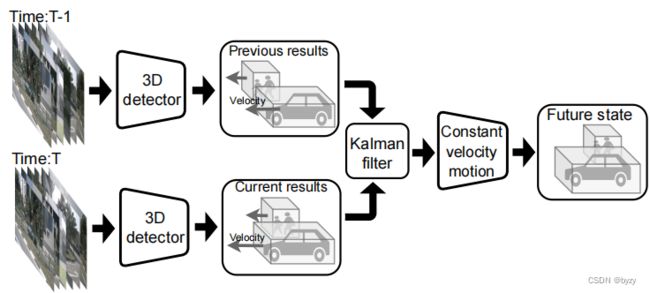

基于速度的更新:使用恒定速度运动模型预测: T r ( t i + 1 ) = T r ( t i ) + ( t i + 1 − t i ) V ( t i ) Tr(t_{i+1})=Tr(t_i)+(t_{i+1}-t_i)V(t_i) Tr(ti+1)=Tr(ti)+(ti+1−ti)V(ti)其中 T r ( ⋅ ) Tr(\cdot) Tr(⋅)和 V ( ⋅ ) V(\cdot) V(⋅)分别表示物体的位置和速度, t i + 1 t_{i+1} ti+1和 t i t_i ti分别表示当前帧和前一帧对应的输入时刻。但速度估计在各帧之间是独立的,而非一致且平滑变化的。为减轻这一问题,本文使用基于IoU的贪心匹配关联连续帧的预测,并使用一阶卡尔曼滤波器修正预测,状态表示为 { x , y , z , x ˙ , y ˙ } \{x,y,z,\dot{x},\dot{y}\} {x,y,z,x˙,y˙}(预测边界框中心位置与BEV下的预测速度)。对于连续帧内无对应预测的物体,直接使用恒定速度运动模型更新位置。
基于学习的预测:本文基于BEVDepth建立一个3D未来检测器(称为BEVDepth-Sf),使用过去帧作为输入,并预测下一帧的检测结果。该模型除了损失函数使用后续帧的标注来计算以外,基本与BEVDepth相同。在训练阶段会丢弃没有未来标注的物体。
4. ASAP基准上的流式评估
4.2 计算受限下的评估
在不同计算平台下的实验表明:
- 与离线评估相比,现有的多数方法在ASAP基准下都有性能下降,且模型延迟越大的,性能下降越明显。
- 算力受到的限制时越大,流式性能的下降越严重。
- 模型排名在不同算力下波动。
- 未来状态预测能补偿推断延迟,从而提高流式性能:对于基于速度的更新方案而言,原始模型速度估计越准确,性能提升越大;且高速物体的检测性能有大的提升。对于基于学习的预测方案而言,计算受限越大,与基于速度的更新方案相比,性能的提升差距越大。这是因为网络低算力情况下的延迟增大,导致需要补偿的时间差增大,而仅进行一帧的预测是不够的。这可能可以通过增加预测帧数减轻;但这样又会导致模型推断时间增加,因此端到端的流式3D检测仍然存在挑战。
在计算资源共享下的实验(GPU同时进行 N N N个分类任务)表明:当 N N N增大时,模型的流式性能均有下降。基于速度的更新方案能够带来性能提升。
上述实验表明计算资源影响流式性能。离线高性能模型在流式评估中会受到算力的更大影响,而高效模型在不同算力下的性能更为一致。应该将模型延迟和计算负担作为设计考虑以便实际应用。
4.3 输入尺寸和主干选择的分析
在流式输入下,主干网络增大会带来一定的性能提升,但若进一步增大输入图像尺寸会导致性能下降。若使用基于速度的更新方案,使用大主干网络和大输入尺寸能够提高性能,但相比于离线评估时的提升非常小。上述实验结果表明,使用大主干网络和大输入尺寸可能会对流式评估带来不利影响,应该选择合适的主干和输出图像尺寸。
8. 基本方案的额外结果
对基于速度的更新方案而言,仅使用恒定速度运动模型能提高性能,再通过多帧匹配和卡尔曼滤波器进行状态修正能进一步提高性能。