从零开始安装Hadoop
目录
一 新建虚拟机
二 设置固定IP
三 检验
3.1 查看虚拟机能否Ping通我们设置的IP地址
3.2 查看虚拟机能否连通外网
3.3 查看主机能否Ping通我们的虚拟机
四 SSH无密登陆、远程连接、关闭防火墙
五 安装JDK
六 本地模式
6.1 参数配置
6.2 验证
七 伪分布式模式
八 完全分布式模式
8.1 /etc/hadoop/hadoop-env.sh
8.2 /etc/hadoop/yarn-env.sh
8.3 /etc/hadoop/slaves
8.4 /etc/hadoop/core-site.xml
8.5 /etc/hadoop/hdfs-site.xml
8.6 /etc/hadoop/mapred-site.xml
8.7 /etc/hadoop/yarn-site.xml
8.8 克隆虚拟机
8.9 配置SSH免密登录
8.10 配置时间同步
所需工具:
-
VMware 15 pro
-
Linux操作系统 CentOS 7
-
Hadoop 2.10.1
-
JDK-18
一 新建虚拟机
Hadoop是基于分布式集群进行数据存储(HDFS)和运算(MapReduce)的,也就是我们需要多台机器,可以选择真正用多台电脑构建一个集群,如果手中没有多台电脑,则可以利用虚拟机构建出多台电脑,虚拟机就是可以利用一台真实机器假装出多台机器的一个工具。 打开VMware,创建新的虚拟机

选择典型安装就可以
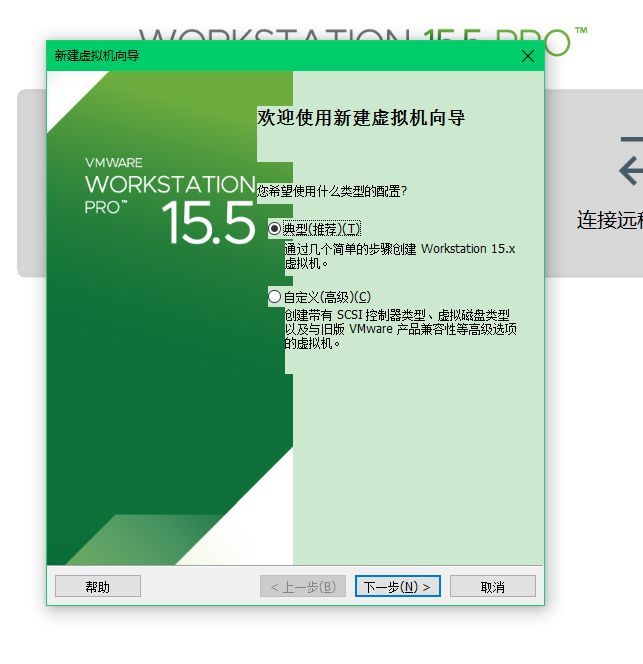
到http://mirrors.bupt.edu.cn/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso上下载Linux操作系统,然后映像文件选择你刚才下载到的文件路径
点击自定义硬件,重新配置我们新建虚拟机的硬件属性(尽量分配较大的内存)
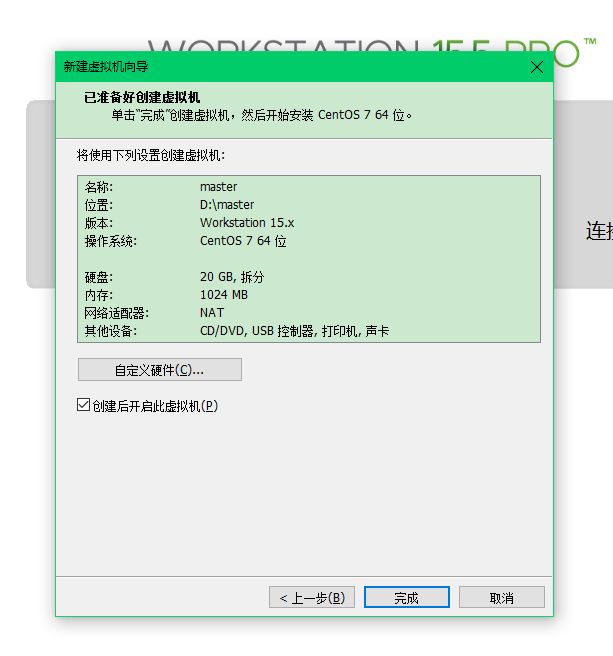

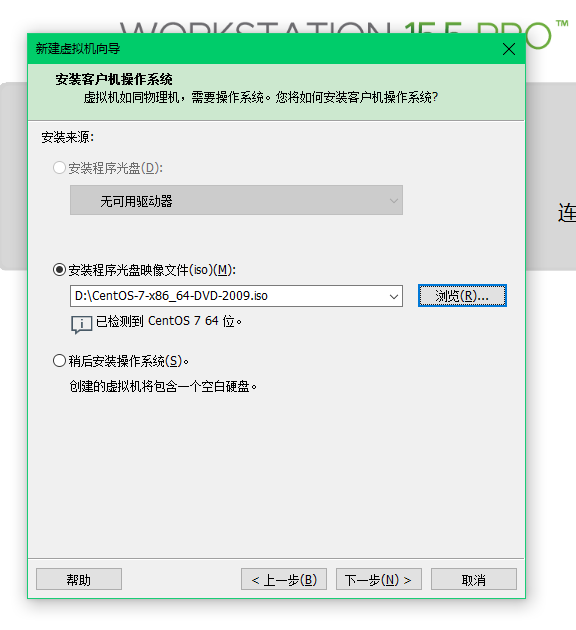
网络这里选择NAT模式或者自定义下面下拉框中的VMnet8都可以,就是一种网络连接方式,不用细究,后面会讲。 然后点击完成,等待安装就可以了。
二 设置固定IP
参考了centOS7虚拟机设置固定IP - 正怒月神 - 博客园 这步操作是什么意思呢,我们建立完了一个虚拟机,多个虚拟机之间是通过IP地址互相通信的,我们希望自己设置我们虚拟机的IP地址,而不是由系统自动分配。(这步很关键一定不要弄错) 假设我们现在想将我们新建立的这台虚拟机的IP地址设置为192.168.2.2 安装完系统点击重启之后,应该是来到这个界面

这是Linux的命令行界面,咱们平时用的Windows那个界面叫图形化界面,如果只是在Linux中进行一些工作,不上网娱乐什么的,这个命令行界面足够了。 localhost login那里输入你想登录的用户名,这里用root账号登录,然后系统会让你输入对应的密码,注意这里用主键盘上的数字输入密码,不要用小键盘上的数字输入(注意,输入的密码是不会在屏幕上显示的) 正确输入后,我们就进入系统了

“root@localhost ~”的意思是当前用户是root,主机名是localhost,~是当前工作目录,也就是根目录 输入指令
cd /etc/sysconfig/network-scripts/这里cd表示目录跳转,/etc这个目录是关于系统配置的目录,因为我们要改IP地址,那就是修改网络配置,所以跳到/etc/sysconfig/network-scripts/这个目录下 输入指令
ls列出这个目录下都有哪些文件

用vim编辑ifcfg-ens33这个文件,这个文件是关于网卡的配置文件,输入指令
vi ifcfg-ens33这样我们就打开这个文件了,因为我们是用root账号登录的,所以我们可以对其进行更改
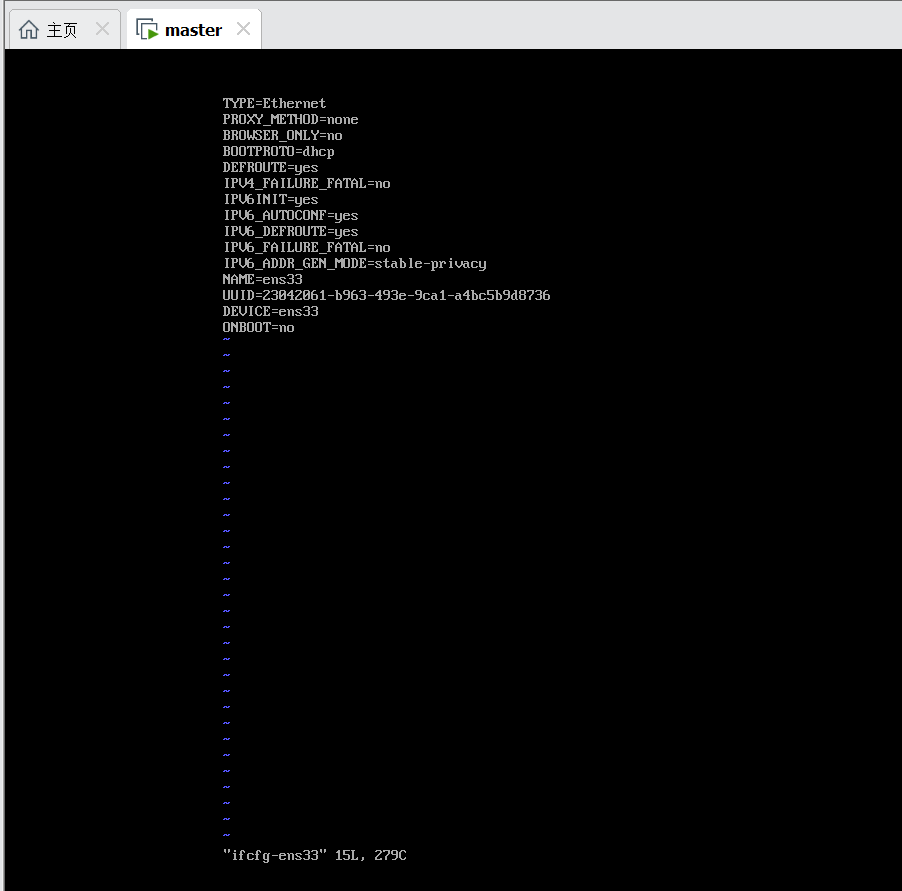
按下'i’进入文本编辑模式,改成下面这样

重点更改几个属性的值 BOOTPROTO这个属性改成static,取消原先的dhcp设置 onboot这个属性改成yes,设置为开机读取我们这个配置 添加IPADDR属性,这里写想要改成的固定IP地址 添加NETMASK属性,这里是子网掩码,照着填就行 添加GATEWAY(注意拼写),这里是网关的地址,前3个字段应该与你要设置的IP地址的前三个字段一致,最后一个建议设为1,省的忘记,然后你的IP地址从2开始 添加DNS1属性,这里是DNS的地址 更改完之后按ESC,然后输入
::wq!这样就把我们的配置信息写入进去了 输入
service network restart重启网络。 点击虚拟机上方菜单中的'编辑->虚拟网络编辑器'选项

选择VMnet8那个选项,这是虚拟机虚拟出来的网卡,点击'更改设置'

取消'使用本地DHCP...'那个勾选,然后子网IP设置为与你自己要设置的IP地址的前三个字段相同,最后一个是0,子网掩码是255.255.255.0,然后点击'NAT设置'

把刚才设置的网关地址填上,然后点击确定一路返回就可以 回到Windows主机,打开设置中的WLAN->更改适配器选项

右键第二个那个VMnet8,点击属性

点击Internet 协议版本4的属性选项,填入具体地址,这里的IP地址不要跟你设置的虚拟机IP地址相同

然后一路确定返回就可以
三 检验
到这里需要检验一下IP设置是否成功
3.1 查看虚拟机能否Ping通我们设置的IP地址
如果出现下面这样的结果证明可以Ping通

按Ctrl+z停止ping
3.2 查看虚拟机能否连通外网
Ping一下百度,如果出现下面这样的结果证明能Ping通

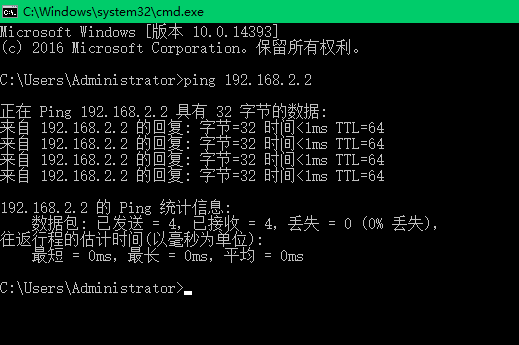
3.3 查看主机能否Ping通我们的虚拟机
回到Windows主机,win+r然后输入cmd打开命令行窗口,ping我们设置的虚拟机IP地址,如果出现下面结果证明能够Ping通,如果不成功关闭Windows防火墙再试试
四 SSH无密登陆、远程连接、关闭防火墙
首先配置SSH无密码登录 输入
ssh-keygen -t rsa然后连着按三次Enter确认

设置IP和域名的映射,输入
vi /etc/hosts按'i’在 文件里填入我们虚拟机的IP地址和域名映射

master就是我们上面新建的那个虚拟机,后面的slave.x是后面要通过克隆机制新建的其它虚拟机,先不用管 复制公钥到master认证文件,输入
ssh-copy-id -i /root/.ssh/id_rsa.pub master按照提示输入'yes’和密码就可以 其它虚拟机(可以先跳过)同样进行复制
ssh-copy-ip -i /root/.ssh/id_rsa.pub slave1
ssh-copy-ip -i /root/.ssh/id_rsa.pub slave2
ssh-copy-ip -i /root/.ssh/id_rsa.pub slave3然后输入
ssh master查看我们是否设置成功,如果出现下面的结果证明设置成功

利用WinScp等工具远程连接到我们的虚拟机,为什么要远程连接呢,比如我们下面需要下载JDK和Hadoop,如果直接在虚拟机上下载会很慢,我们可以在Windows主机上下载,然后通过远程连接上传到虚拟机中

主机名那里写你前面设置的虚拟机IP地址就可以,然后输入用户名和密码进行远程连接,默认会来到相应用户的根目录下。 接下来关闭主机的防火墙 切换到root,输入
firewall-cmd --state可以查看当前防火墙状态 输入
systemctl stop firewalld.service关闭防火墙 输入
systemctl disable firewalld.service禁止防火墙服务开机自启
五 安装JDK
Hadoop依赖Java,需要安装JDK,去官网下载JDK,然后通过远程连接上传到虚拟机中
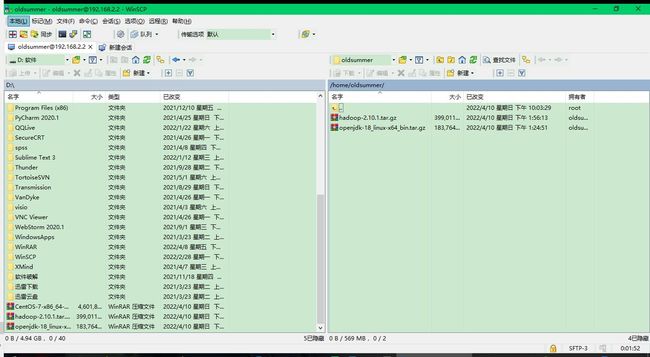
然后用你远程连接登录的号,再次登录虚拟机,输入ls,检验文件是否上传成功
然后输入
tar zxvf openjdk_18_linux-x64_bin.tar.gz将JDK包解压到当前文件夹,然后输入
cd jdk-18/bin进入解压之后JDK的bin文件夹 然后输入
./java -version检验JDK是否安装成功,如果是下面这样表明成功

接下来配置环境变量PATH,这样可以直接在命令行中使用Java的相关命令 首先跳转到jdk的解压目录下,输入
pwd记录一下它输出的这个变量信息
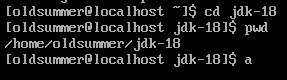
输入
su -输入密码切换到root 输入
vi /etc/profile进行环境变量配置,在文件末尾添加
export JAVA_HOME=刚才你记录的输出
export PATH=$PATH:$JAVA_HOME/bin然后输入
source /etc/profile java -version如果出现以下输出证明配置成功

Hadoop具有三种安装模式:
-
本地模式:无须任何守护进程,所有程序在同一个JVM上执行,如果只是想玩玩Hadoop写几个MapReduce程序,这个模式足够了。
-
伪分布式模式:当前机器既是主节点也是从节点,所有的守护进程运行在同一个机器上,模拟集群
-
完全分布式模式:当前机器是主节点,然后其它机器是从节点,节点之间通过网络进行通信,真正的集群
下面分别对这三种不同的安装模式进行说明
六 本地模式
本地模式安装步骤如下:
-
安装虚拟机
-
设置固定IP
-
安装JDK
-
配置SSH无密登陆
-
Hadoop环境参数配置
-
验证
1~4前面都说了下面说参数配置
6.1 参数配置
修改hadoop-env.sh文件,设置正确的JAVA_HOME位置即可
跳转到你的hadoop解压目录下,所有的配置文件都在 你的hadoop解压目录/etc/hadoop这个目录中,用cd跳转到这个目录下
cd user/hadoop-2.10.1/etc/hadoop 获取当前系统Java的配置位置
which java 记录下这个输出
输入
vi hadoop-en.sh 在其中加入
exprot 你的Java配置位置 这样就配置完毕了。
PATH中加入Hadoop root下输入
vi /etc/profile 添加Hadoop环境变量
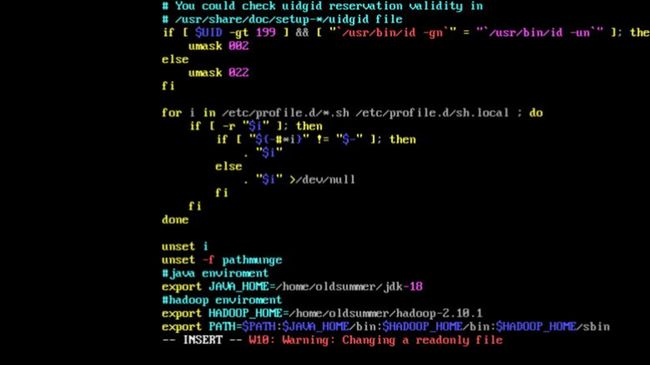
然后输入
source /etc/profile 这样可以直接在命令行中利用Hadoop命令
6.2 验证
输入
hadoop fs -ls 这是查看HDFS系统,列出其下的文件,因为我们是本地模式,所以输出就是本机的目录,如果输出下面这样证明本地模式安装成功,可以运行MapReduce任务了

七 伪分布式模式
伪分布式就是本机即当主节点(master)也当从节点(slaves) 安装步骤如下:
-
安装虚拟机
-
配置固定IP
-
配置无密登陆SSH,关闭防火墙
-
安装JDK
-
安装Hadoop
-
Hadoop参数配置
-
验证
1~5按照前面所说的进行即可 6和7可参考https://www.cnblogs.com/thousfeet/p/8618696.html 修改主机IP地址映射表 vi /etc/hosts 添加你虚拟机和域名的映射

master是当前主机,IP地址时192.168.128.130,后面那三个是从节点,后面完全分布式模式的时候用。 然后输入 ping master 如果能ping通证明配置成功
八 完全分布式模式
完全分布式模式下存在多台机器,这些机器构成一个集群,其中一台是主节点(master)其余是从节点(slaves)。主节点协调多个从节点对外提供服务,这样虽然集群是由多个节点组成,但是对于客户来说感觉上就像是一台普通的机器。 安装步骤如下:
-
安装虚拟机
-
设置固定IP
-
安装JDK
-
安装Hadoop
-
配置Hadoop
-
克隆虚拟机
-
配置SSH免密码登录
-
配置时间同步服务
1~4按照前面说的就行 Hadoop的配置涉及到以下7个文件
-
/etc/hadoop/hadoop-env.sh:Hadoop运行基本环境配置
-
/etc/hadoop/yarn-env.sh:YARN框架运行环境配置
-
/etc/hadoop/slaves:slave节点信息配置
-
/etc/hadoop/core-site.xml:核心属性配置文件
-
/etc/hadoop/hdfs-site.xml:HDFS属性配置文件
-
/etc/hadoop/mapred-site.xml:MapReduce属性配置文件
-
/etc/hadoop/yarn-site.xml:YARN属性配置文件
下面按照顺序介绍相应文件的配置 首先进入Hadoop的解压目录下的/etc/hadoop,这里根据你hadoop的解压情况自己进行跳转,比如我这里是
cd hadoop-2.10.1/etc/hadoop 8.1 /etc/hadoop/hadoop-env.sh
这里要配置我们JDK的安装位置 老样子vi命令进入对应文件进行更改,将export那行改成你JDK 的安装路径

8.2 /etc/hadoop/yarn-env.sh
这里也是改JDK的安装路径,添加一行
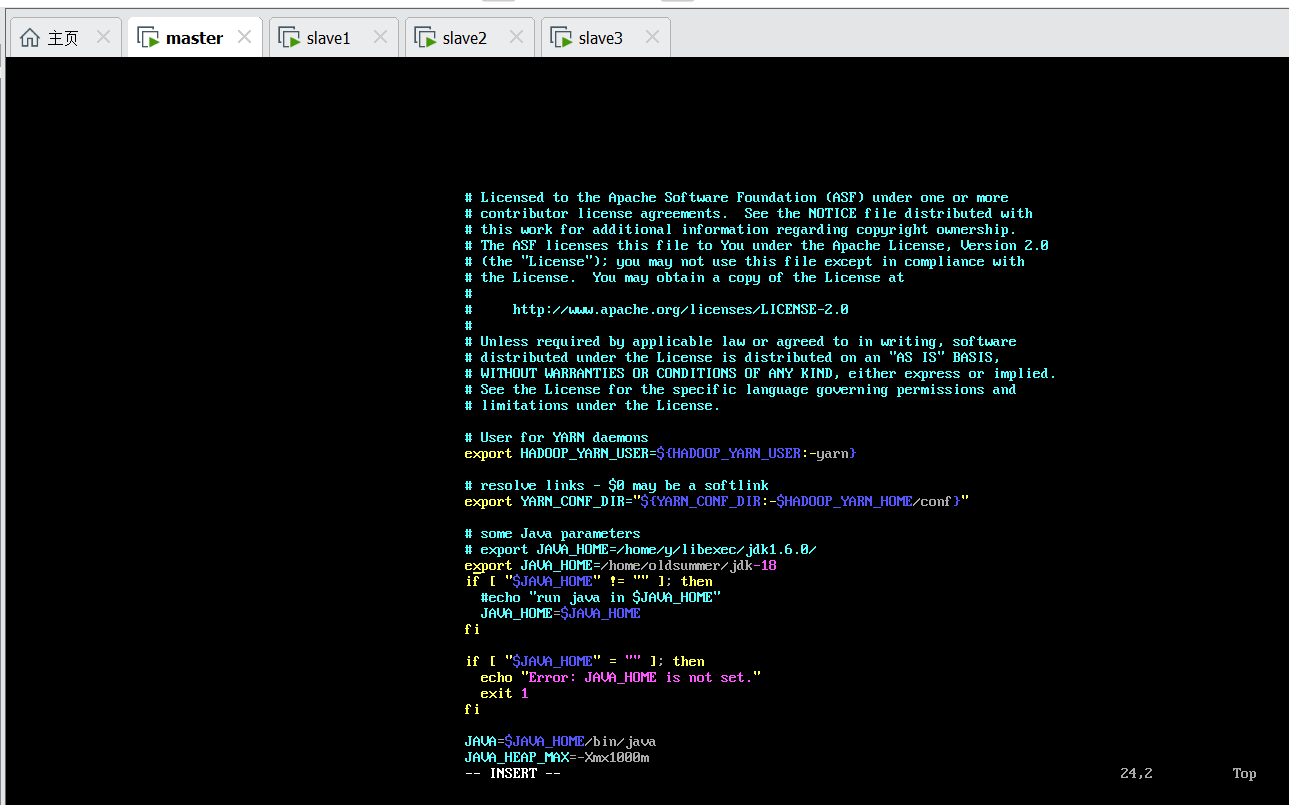
8.3 /etc/hadoop/slaves
设置节点的信息,添加我们克隆的三个虚拟机节点

8.4 /etc/hadoop/core-site.xml
所谓的xml文件不要想的多么复杂,它就是一个键值对映射,改成下面这样

在
8.5 /etc/hadoop/hdfs-site.xml
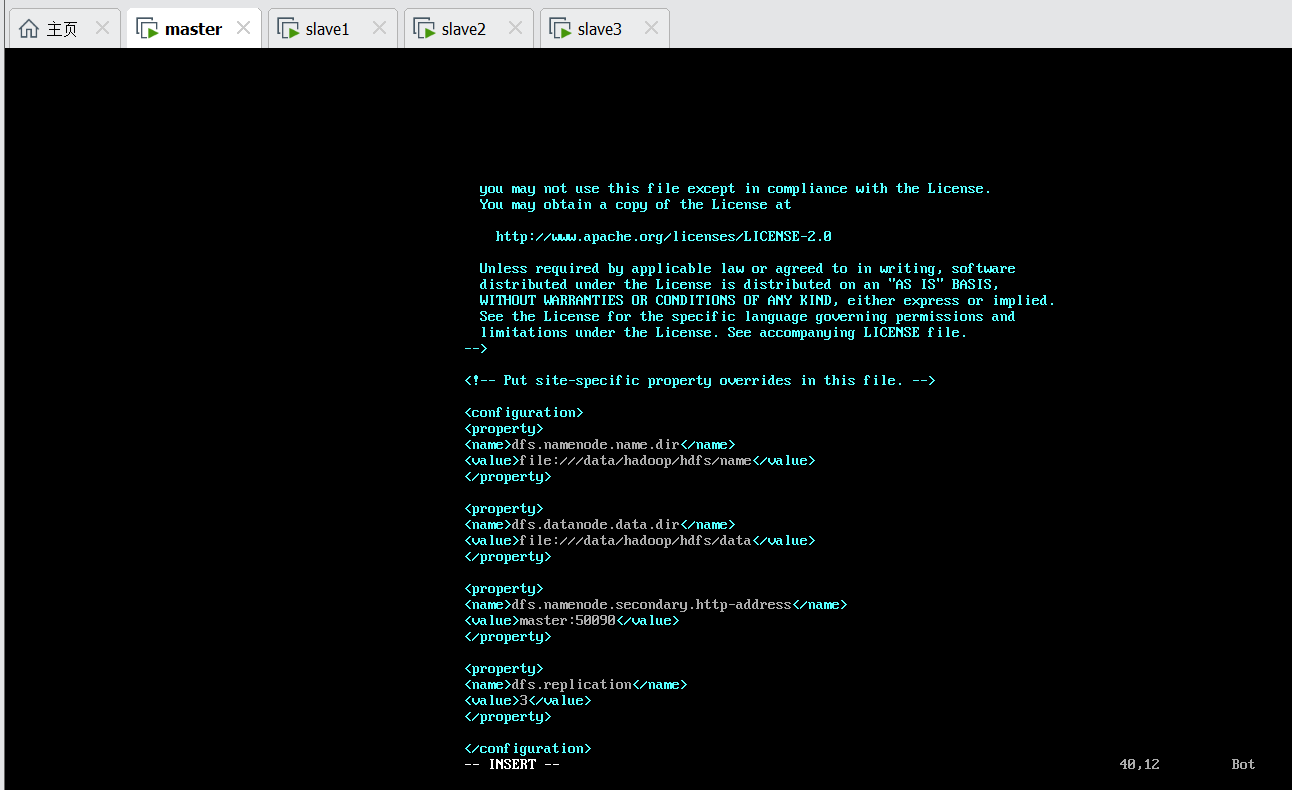
定义了四个属性,分别指定了NameNode和DataNode数据的存储位置,SecondaryNameNode的地址,文件块的副本数
8.6 /etc/hadoop/mapred-site.xml
我下的这个Hadoop中这个文件名已经改成mapred-site.xml.template了,注意一下自己的hadoop中的文件名,添加以下配置,设置mapreduce使用yarn框架

8.7 /etc/hadoop/yarn-site.xml
添加以下配置
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.webapp.address
master:8088
yarn.resourcemanager.webapp.https.address
master:8090
yarn.resourcemanager.ressource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.nodemanager.local-dirs
/home/oldsummer/data/hadoop/yarn/local
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/home/oldsummer/data/tmp/logs
yarn.log.server.url
http://master:19888/jobhistory/logs/
URL for job history server
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
2048
yarn.scheduler.minimum-allocation-mb
512
yarn.shceduler.maximum-allocation-mb
4096
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
yarn.nodemanager.resource.cpu-vcores
1
8.8 克隆虚拟机
关闭当前虚拟机,右键克隆->创建完整克隆 等待克隆,然后修改相关配置,先删除一个文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules 然后输入
ifconfig -a 记录下HWADDR的值 修改slaves的网卡配置,修改HWADDR、IPADDR的值,注释掉UUID
输入
vi /etc/sysconfig/network 修改机器名,然后重启,主机和克隆机之间互ping一下查看是否成功,按照同样的步骤克隆slaves2、slaves3
8.9 配置SSH免密登录
在主节点master上,输入
ssh-keygen -t rsa 然后连按三次enterssh 然后复制公钥到相应机器中
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
ssh-copy-id -i /root/.ssh/id_rsa.pub slave3 按照提示输入yes和密码即可,最后在master下分别输入 ssh slave1 ssh slave2 ssh slave3 如果登录上了证明配置成功
8.10 配置时间同步
在每个机器上输入
yum install -y ntp 安装时间同步工具
设置master节点为主节点,在master中
vi /etc/ntp.conf 注释掉以server开头的行,并添加
restrict 192.168.0.0 mask 255.255.255.0
nomodify notrap server 127.127.1.0
fudge 127.127.1.0 stratum 10 在slave机器中同样注释掉server开头的行,然后添加
server master 然后确定所有机器都关闭了防火墙 在master节点输入
service ntpd start chkconfig ntpd on 在slave节点输入
ntpdate master service ntpd start chkconfig ntpd on 启动时间同步服务 这样就安装、配置完毕了,接下来就是该初始化初始化,启动集群就启动集群,如果还是出现问题可以参考这篇文章修改一下配置hadoop分布式集群的启动和关闭的问题_ghsticker的博客-CSDN博客_hadoop集群开启后忘记关闭