激光点云3D目标检测算法之PointPillars
前言
《PointPillars: Fast Encoders for Object Detection from Point Clouds》是一篇发表在CVPR 2019上关于激光点云3D目标检测的文章,其中提出了一种新的点云编码方法用于给PointNet提取点云特征,再将提取的特征映射为2D伪图像以便用2D目标检测的方式进行目标检测。本文将对PointPillars算法模型进行简要的解读。

模型结构
PointPillars的网络结构如下图所示:

从图中可以看出,PointPillars分为三个部分。
第一部分:Pillar Feature Net (PFN)
该部分网络结构的作用是将点云转换为伪图像,转换过程的示意图如下:
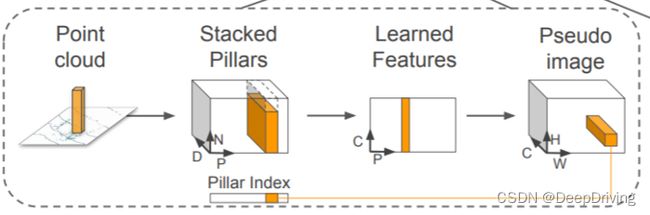
- 首先,输入点云被分割成多个Pillar单元,每个Pillar是在XY平面上(笛卡尔坐标系)以一定的步长对点云进行划分得到的一个3维的小单元格。

然后每个Pillar中的每个点云被编码成一个9维的向量D:(x,y,z,r,xc,yc,zc,xp,yp),其中x,y,z,r分别表示点云在三维空间中的3个坐标和反射强度;xc,yc,zc表示到该Pillar中所有点的算术平均值点的距离,xp,yp表示该点到该Pillar的x,y中心的偏移值。由于点云数据的稀疏性,可能很多Pillar都不含点云或者包含的点云数量比较少,考虑到计算复杂度的问题,会对Pillar的数量进行限制,最多处理P个非空的Pillar,同时每个Pillar中最多包含N个点云特征向量,如果点云数大于N,则采用随机采样的方法从中选取N个,反之,如果点云的数量少于N,则用零填充的方法填充到N个。通过上述方法,就将一帧点云数据编码成了一个维度为(D,P,N)的稠密张量。
-
接下来,用一个简化版的PointNet网络进行处理。首先将每个包含D维特征的点用一个线性层+BatchNorm+ReLU激活函数处理后,生成维度为(C,P,N)的张量;然后对每个Pillar单元进行最大池化操作,得到维度为(C,P)的张量。
-
最后一步是通过一个scatter算子生成伪图像。这一步的方法比较简单,就是通过每个点的Pillar索引值将上一步生成的(C,P)张量转换回其原始的Pillar坐标用来创建大小为(C,H,W)的伪图像。这里需要解释一下伪图像的高度H和宽度W是怎么来的:在第一步对点云进行Pillar划分的时候会设置XY平面上点云坐标的范围和每个Pillar的大小,假设X轴的范围是[0,69.12],Y轴的范围是[-39.68,39.68],每个Pillar的大小是0.16x0.16,那么以X轴表示宽,Y轴表示高,一个Pillar表示一个像素的话,那么这个伪图像的宽W = (69.12 - 0) / 0.16 = 432,高H = (39.68 -(-39.68)) / 0.16 = 496。
第二部分:骨干网络
PointPillars采用了与VoxelNet一样的RPN(Region Proposal Network)骨干网络,该部分由一个2D卷积神经网络组成,其作用是用于在第一部分网络输出的伪图像上提取高维特征。RPN骨干网分为两个子网络:一个自顶向下的子网络用于在越来越小的空间分辨率特征图上提取特征,另一个子网络则负责将不同分辨率特征图上提取的特征通过反卷积操作进行上采样至同样维度大小然后进行串联。
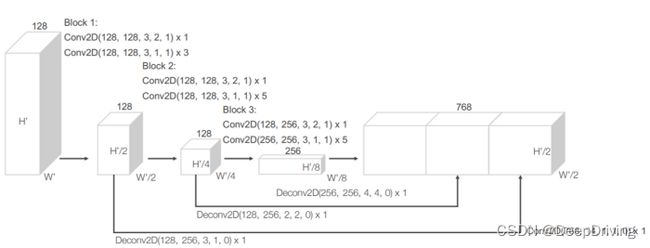
第三部分:检测头
PointPillars采用了SSD的检测头用来实现3D目标检测。与SSD类似,PointPillars在2D网格中进行目标检测,而Z轴坐标和高度则是通过回归的方式得到。
损失函数
PointPillars采用了与SECOND一样的损失函数。
每个目标的3D框用一个7维向量来表示: ( x , y , z , w , l , h , θ ) (x,y,z,w,l,h,\theta) (x,y,z,w,l,h,θ),其中x,y,z表示3D框的中心点坐标;w,l,h分别表示3D框的宽、长、高; θ \theta θ表示3D框的朝向角。那么在检测框定位回归任务中Ground truth和锚框之间的残差定义为:
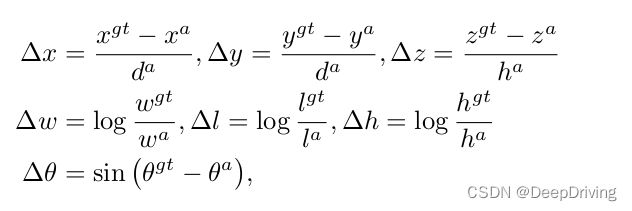
其中, x g t x^{gt} xgt 和 x a x^{a} xa 分别表示Ground truth和锚框, d a = ( w a ) 2 + ( l a ) 2 d^{a} = \sqrt{(w^{a})^{2} + (l^{a})^{2}} da=(wa)2+(la)2 。定位损失函数采用Smooth L1函数:

与SECOND一样,PointPillars采用Softmax分类损失来学习目标的朝向,该损失函数用$L_{dir} $来表示。
对于目标分类任务,PointPillars采用了Focal loss:
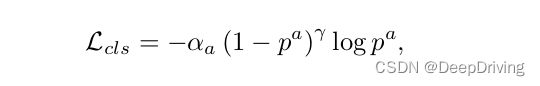
其中 p a p^{a} pa表示锚框的类别概率, α = 0.25 , γ = 2 \alpha=0.25, \gamma=2 α=0.25,γ=2。
总的损失函数如下:

其中 N p o s N_{pos} Npos是真阳性锚框的数量, β l o c = 2 , β c l s = 1 , β d i r = 0.2 \beta_{loc}=2, \beta_{cls}=1, \beta_{dir}=0.2 βloc=2,βcls=1,βdir=0.2。
总结
PointPillars提出了一种新的点云编码方式和3D转2D的方法,用2D卷积的方式实现目标检测而没有采用耗时的3D卷积,在速度和精度上达到了很好的平衡,其速度快、精度高、易于部署的特点使得其在工业界得到了广泛的应用。
参考资料
- PointPillars: Fast Encoders for Object Detection from Point Clouds
- https://becominghuman.ai/pointpillars-3d-point-clouds-bounding-box-detection-and-tracking-pointnet-pointnet-lasernet-67e26116de5a