python爬虫:scrapy-redis分布式爬虫(详细版)
本文是将现有的scrapy爬虫改造为分布式爬虫,为详细版,简略版请看https://blog.csdn.net/Aacheng123/article/details/114265960
使用scrapy-redis
改造前:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
改造后:
import scrapy
from scrapy import Item, Field
from scrapy_redis.spiders import RedisSpider
class ExampleSpider(RedisSpider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
实际上就是把原来继承的scrapy.Spier,换成了scrapy_redis.RedisSpider
启动爬虫
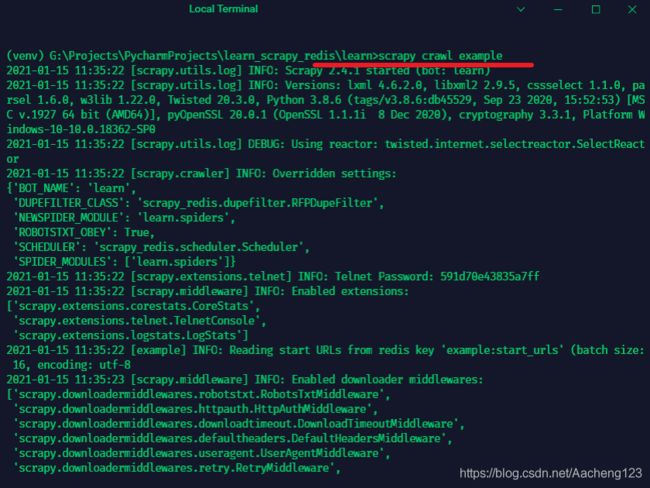
启动之后,不会立即爬取内容,因为在redis中还没有"任务"

这个时候,我们向redis中推送一个“任务”
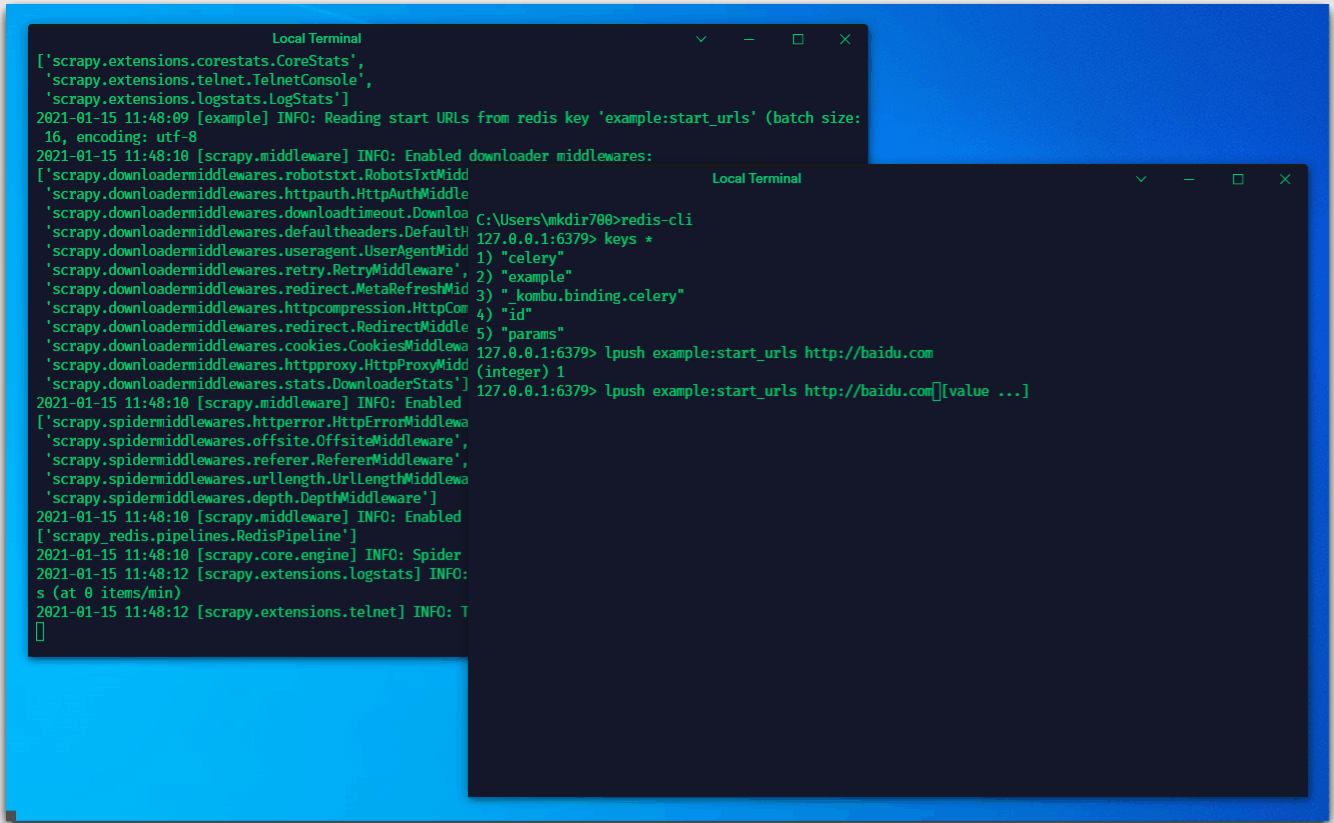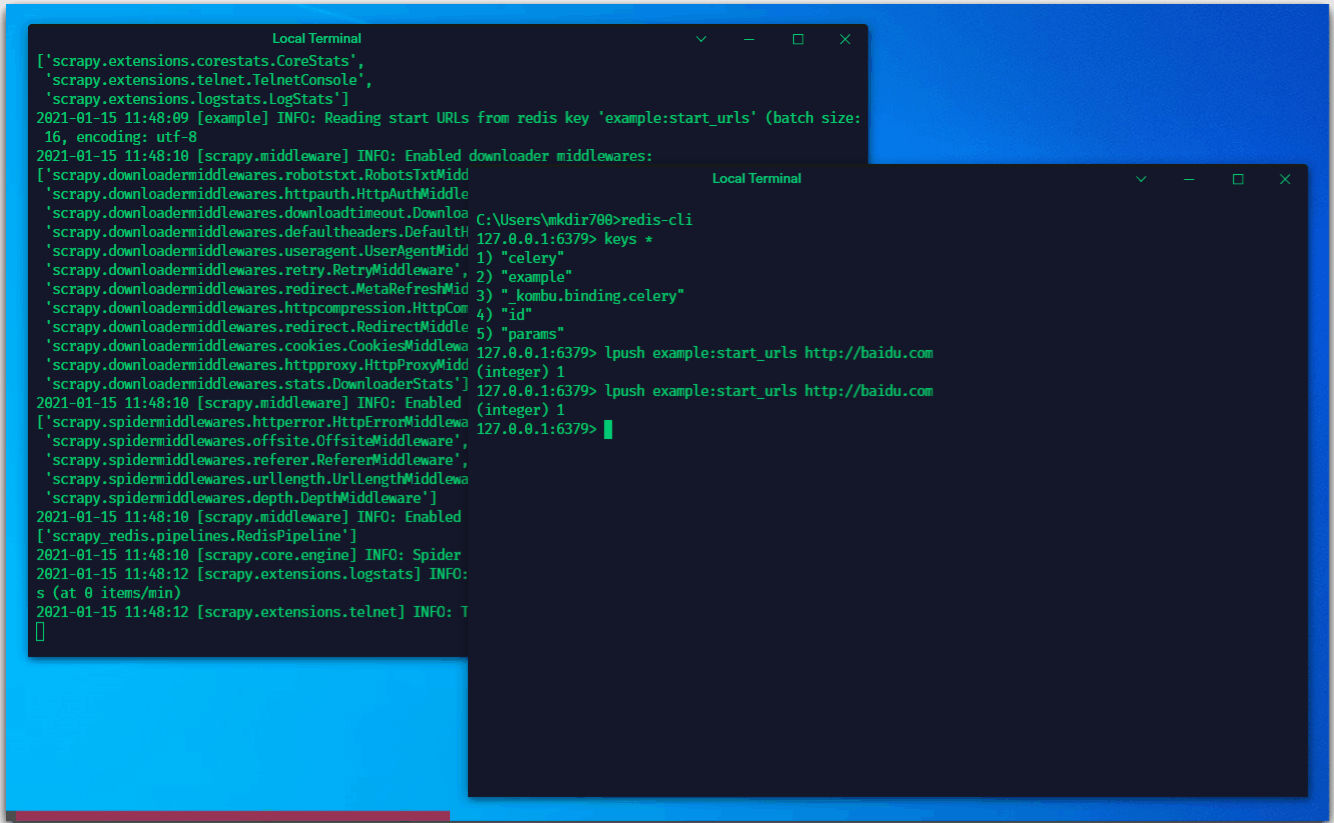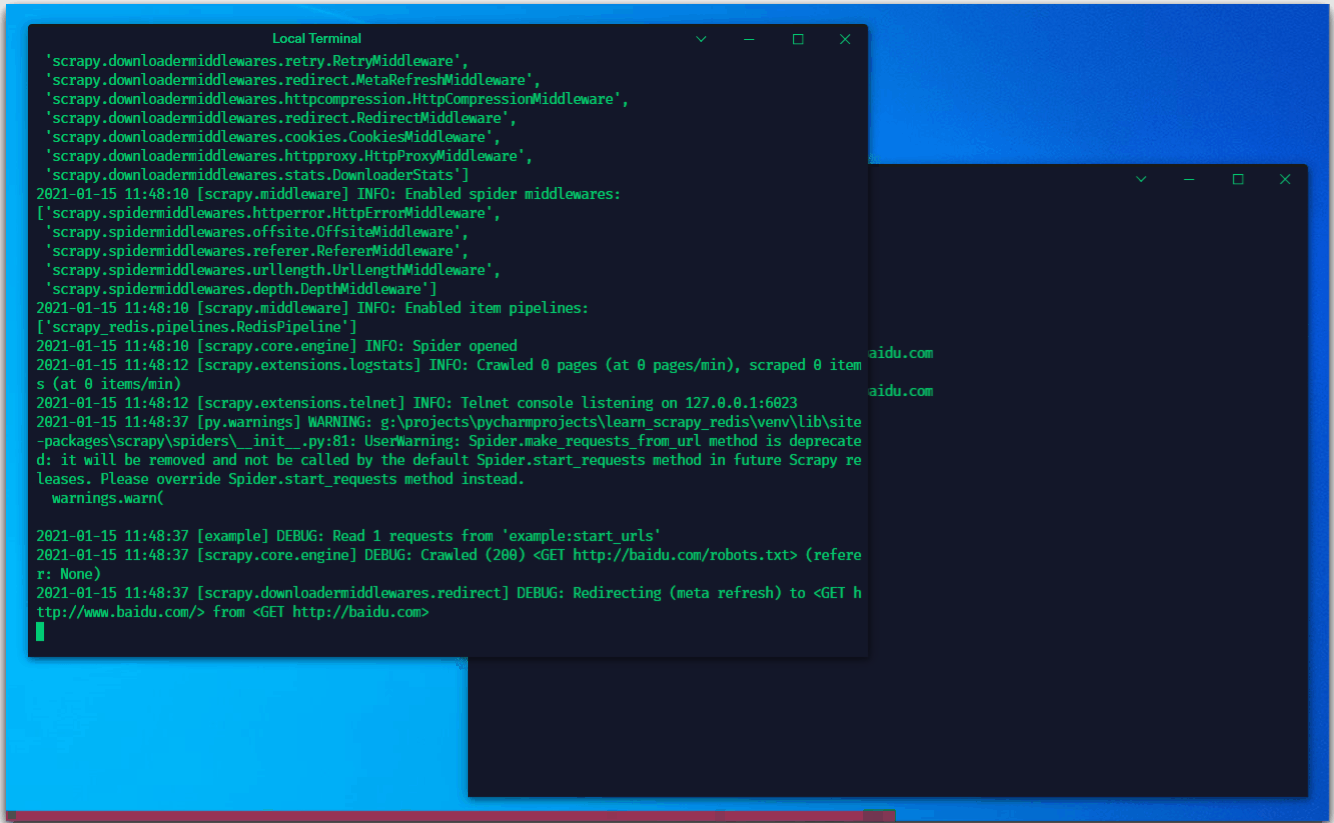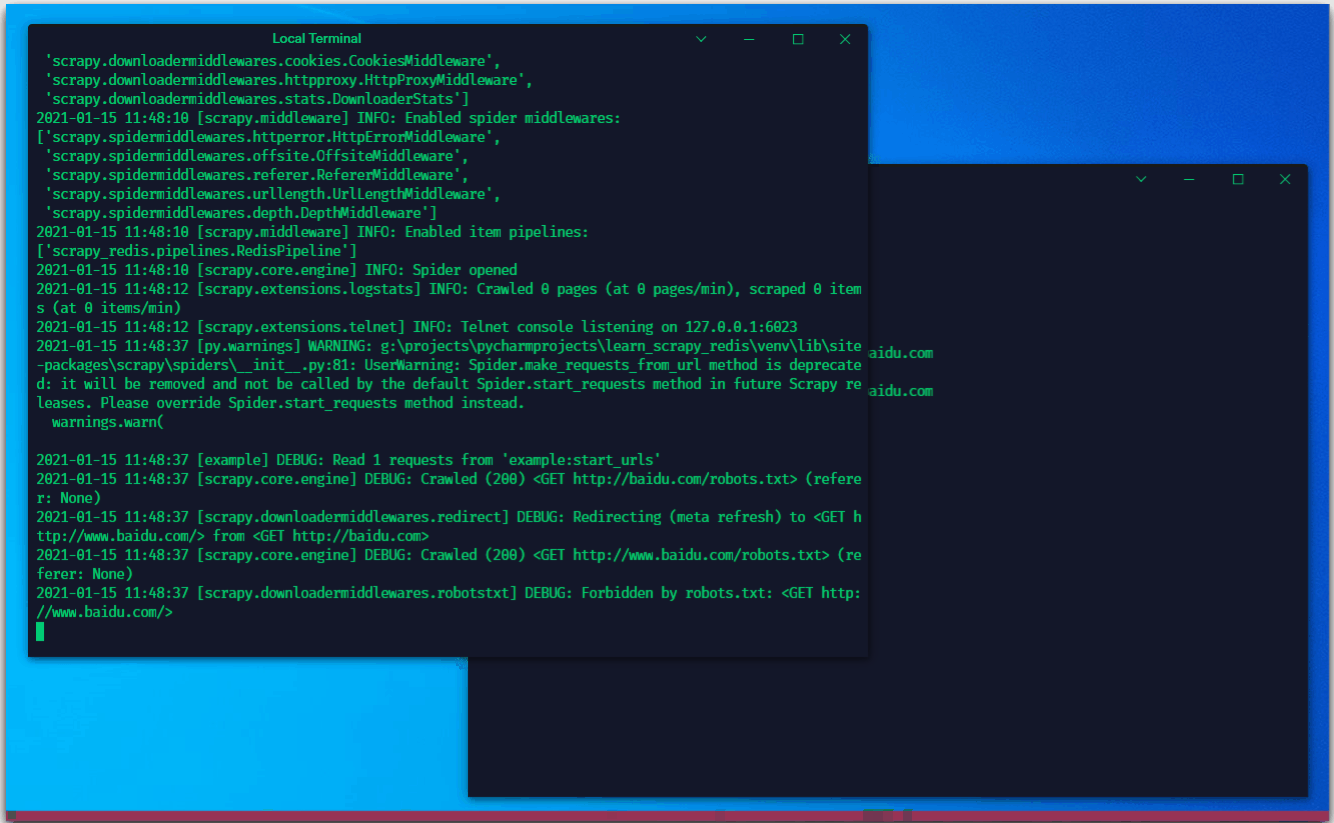
可以看到,紧接着爬虫就去执行了这个任务
我们这里是手动推送一个链接到redis。对于爬虫在执行的过程中,也会抛出item及request,抛出的request则会推送至redis中
我们重写start_request方法,让这个方法抛出request对象
import scrapy
from scrapy import Item, Field, Request
from scrapy_redis.spiders import RedisSpider
class ExampleSpider(RedisSpider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def start_requests(self):
for i in range(100):
yield Request(
url="http://google.com/"+str(i)
)
def parse(self, response):
pass
然后,重新执行爬虫,当爬虫开始爬取的时候Ctrl + c结束程序

接着,来看下redis

此时,新增两个key,分别是dupefilter 和 request,他们是zset类型
根据它们的名字,意思也很明了。
dupefilter:用于过滤重复请求,如果请求在这个里面,就不会放入request中
request:存储待执行的请求任务
查看request

使用pickle反序列化后:
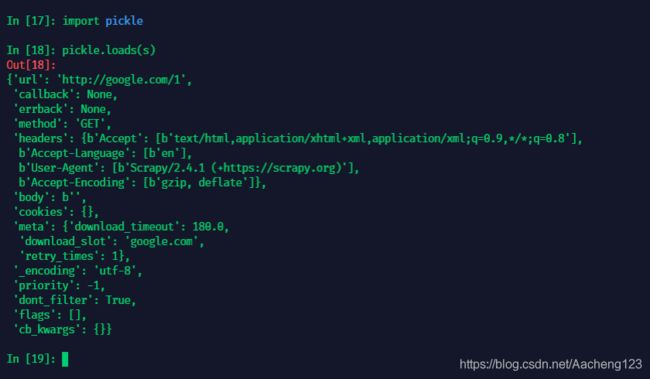
可以看到,是关于这个请求的一些信息,比如,请求头,回调函数等等
在分布式爬虫中,当其他爬虫拿到这个请求时,根据这个请求的信息就知道该如何去执行
items存储
当我们的爬虫抛出item,经由pipeline中间件进行存储。
使用scrapy-redis,我们可以将多个爬虫抛出的item,统一存储至redis数据库中,然后进行统一处理。
在此前提,需要开启scrapy-redis的存储中间件
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
我们还可以进行其他的items设置
# The item pipeline serializes and stores the items in this redis key.
# item存储键的设置
REDIS_ITEMS_KEY = '%(spider)s:items'
# The items serializer is by default ScrapyJSONEncoder. You can use any
# importable path to a callable object.
# items的序列化器默认是ScrapyJsonEncoder,
# 你也可以使用在任意路径都可导入并调用的对象作为序列化器
# REDIS_ITEMS_SERIALIZER = 'json.dumps'
注意:存储至redis需要序列化,就像存储request那样。默认scrapy-redis使用的是ScrapyJsonEncoder,可以方便的将item序列化。如果你需要使用自定义序列化器,必要条件:序列化对象必须是任意路径下均可调用的对象。
例如:json.dumps,在任意python文件中,通过from json import dumps即可调用,自定义的序列化器也得满足这样。
改写代码如下:
import scrapy
from scrapy import Item, Field, Request
from scrapy_redis.spiders import RedisSpider
class ExampleSpider(RedisSpider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def start_requests(self):
yield Request(
url="https://www.baidu.com/",
dont_filter=False
)
def parse(self, response):
item = Item()
item.fields['hello'] = Field()
item['hello'] = 'scrapy-redis'
yield item
随便请求一个网址,然后parse方法被调用,设置item并抛出
在redis中查看:

步骤小结
经过上面的探究,要使现有爬虫改成分布式爬虫,步骤非常简单。
1. 安装scrapy_redis
pip install scrapy_redis
2. 配置settings
根据自己的需求,进行配置,我这里对每个配置项进行了简单的翻译
将下面的配置信息,放进settngs.py即可
注意:既然是分布式爬虫,则必须指定你的redis链接哦!,默认是本地
# Enables scheduling storing requests queue in redis.
# 开启redis中调度存储请求队列
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
# 保证所有爬虫共享同一去重过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Default requests serializer is pickle, but it can be changed to any module
# with loads and dumps functions. Note that pickle is not compatible between
# python versions.
# Caveat: In python 3.x, the serializer must return strings keys and support
# bytes as values. Because of this reason the json or msgpack module will not
# work by default. In python 2.x there is no such issue and you can use
# 'json' or 'msgpack' as serializers.
#SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# Don't cleanup redis queues, allows to pause/resume crawls.
# 不清理redis队列,允许暂停/恢复
SCHEDULER_PERSIST = True
# Schedule requests using a priority queue. (default)
# 调度器使用的队列(优先级队列)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# Alternative queues.
# 其他可选择的队列
# 先进先出队列
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# 后进先出队列
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
# Max idle time to prevent the spider from being closed when distributed crawling.
# This only works if queue class is SpiderQueue or SpiderStack,
# and may also block the same time when your spider start at the first time (because the queue is empty).
# 最大闲置时间,防止爬虫在分布式爬取的过程中关闭
# 这个仅在队列是SpiderQueue 或者 SpiderStack才会有作用,
# 也可以阻塞一段时间,当你的爬虫刚开始时(因为刚开始时,队列是空的)
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# Store scraped item in redis for post-processing.
# 将已得到的item结果存储至redis中,可用于结果的统一处理
# ITEM_PIPELINES = {
# 'scrapy_redis.pipelines.RedisPipeline': 300
# }
# The item pipeline serializes and stores the items in this redis key.
# item存储键的设置
REDIS_ITEMS_KEY = '%(spider)s:items'
# The items serializer is by default ScrapyJSONEncoder. You can use any
# importable path to a callable object.
# items的序列化器默认是ScrapyJsonEncoder,
# 你也可以使用在任意路径都可导入并调用的对象作为序列化器
# REDIS_ITEMS_SERIALIZER = 'json.dumps'
# Specify the host and port to use when connecting to Redis (optional).
# redis配置
# REDIS_HOST = 'localhost'
# REDIS_PORT = 6379
# Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
#REDIS_URL = 'redis://user:pass@hostname:9001'
# Custom redis client parameters (i.e.: socket timeout, etc.)
# 自定义redis客户端参数
#REDIS_PARAMS = {}
# Use custom redis client class.
# 使用自定义redis客户类
#REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
# If True, it uses redis' ``SPOP`` operation. You have to use the ``SADD``
# command to add URLs to the redis queue. This could be useful if you
# want to avoid duplicates in your start urls list and the order of
# processing does not matter.
# 如果为True,它将使用redis的``SPOP``操作,
# 你可以使用``SADD``命令添加urls到队列中。
# 如果你想要让start_url列表中的链接以及当处理顺序不重要时不去重,这是很有用的。
# REDIS_START_URLS_AS_SET = True
# If True, it uses redis ``zrevrange`` and ``zremrangebyrank`` operation. You have to use the ``zadd``
# command to add URLS and Scores to redis queue. This could be useful if you
# want to use priority and avoid duplicates in your start urls list.
# 如果为True,它将使用 ``zrevrange``和``zremrangebyrank``操作。
# 你可以用``zadd``命令添加urls和优先级到redis队列中。
# 如果你想让你的start_urls列表中的链接避免去重操作以及设置优先级,这是很有用的。
#REDIS_START_URLS_AS_ZSET = False
# Default start urls key for RedisSpider and RedisCrawlSpider.
# 默认start urls的键
# REDIS_START_URLS_KEY = '%(name)s:start_urls'
# Use other encoding than utf-8 for redis.
# redis使用utf-8以外的其他编码
#REDIS_ENCODING = 'latin1'
3. 更换爬虫父类
在上诉例子中,爬虫父类是scrapy.Spider,改成scrapy_redis.RedisSpider即可
如果你的父类是CrawlSpider,同样的操作改为scrapy_redis.RedisCrawlSpider
如果你是自定义父类,则需要额外继承scrapy_redis.RedisMixin,并实现
@classmethod
def from_crawler(self, crawler, *args, **kwargs):
obj = super(自定义的类名, self).from_crawler(crawler, *args, **kwargs)
obj.setup_redis(crawler)
return obj
4. Items Pipeline
这一步骤非强制性要求
如果你希望爬虫爬下来就保存至数据库,比如我现在的爬虫是保存至mongo数据库的,每个爬虫都与mongo建立链接,爬下来就存进去。
如果你希望数据后期统一处理,则可以增加’scrapy_redis.pipelines.RedisPipeline’: 300
ITEM_PIPELINES = {
...
'scrapy_redis.pipelines.RedisPipeline': 300
}
爬虫群:794630151