【MobileNetV2 FLOPs】MobileNetV2网络结构详解并获取网络计算量与参数量
文章目录
- 1 MobileNetV2简介
- 2 线性激活函数的使用原因
- 3 Inverted residual block 和 residual block的区别
- 4 一种常规MobileNetv2结构
- 5 MobilenetV2代码
- 6 感谢链接
1 MobileNetV2简介
MobileNetV2是一个轻量型卷积神经网络,使用深度可分离卷积。
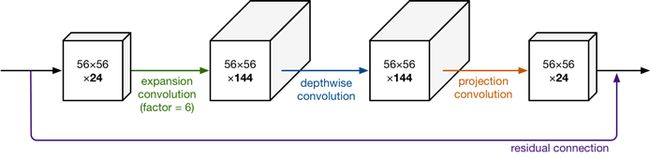
如下图表示其中一个block的结构(学名:Inverted residual block),主要包括Expansion layer,Depthwise Convolution,Projection layer。
Expansion layer表示扩展层,使用1x1卷积,目的是将低维空间映射到高维空间(升维)。
Projection layer表示投影层,使用1x1卷积,目的是把高维特征映射到低维空间去(降维)。
Depthwise Convolution表示深度可分离卷积,完成卷积功能,降低计算量、参数量。

宏观上看,结构是短连接,内部结构是CBR+CBR+CB,最后一个没有Relu了。[注释: CBR表示Conv+BN+Relu]
这种Inverted residual block是一种中间胖,两头窄的结构,像一个纺锤形,常规Residual Block结构,是两头胖,中间窄的结构。
那Inverted residual block从瘦到胖,胖多少呢?再从胖到瘦,又瘦多少呢?这就涉及到新名词Expansion factor(扩展系数),它控制着网络维度,为了保证短连接的形成,一个block中的“胖瘦”系数相同,这个系数通常是6,可改动。如下图所示。
2 线性激活函数的使用原因
论文中所谓使用了线性激活函数,也就是恒等函数( f ( x ) = x f(x)=x f(x)=x)的意思。为什么要这样做呢?
回答:ReLu激活函数对低维特征信息造成较大损失,对高维特征信息影响较小,在Inverted residual block这种中间胖,两头窄的结构输出时,输出的是一种相对低维的特征,故使用线性激活函数。
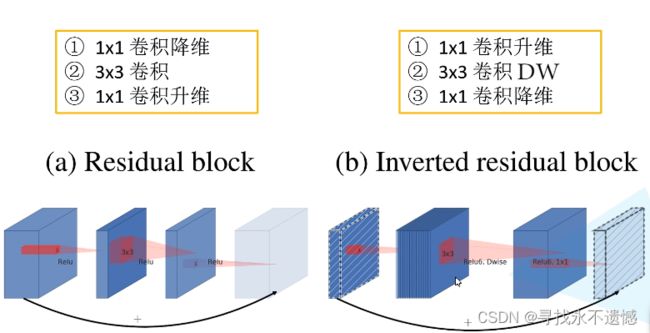
3 Inverted residual block 和 residual block的区别
下图参考 霹雳吧啦Wz 大佬的b站视频,图中明确指明了三点区别。
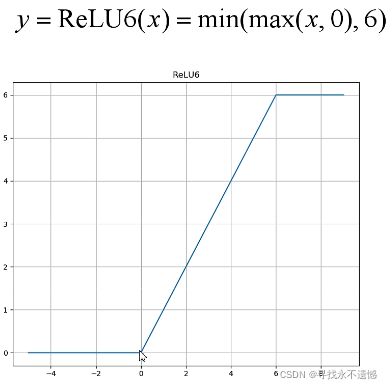
此外,residual block采用ReLu激活函数,Inverted residual block采用ReLu6激活函数,ReLu6激活函数如下图所示,相当于加了个最大值6进行限制。
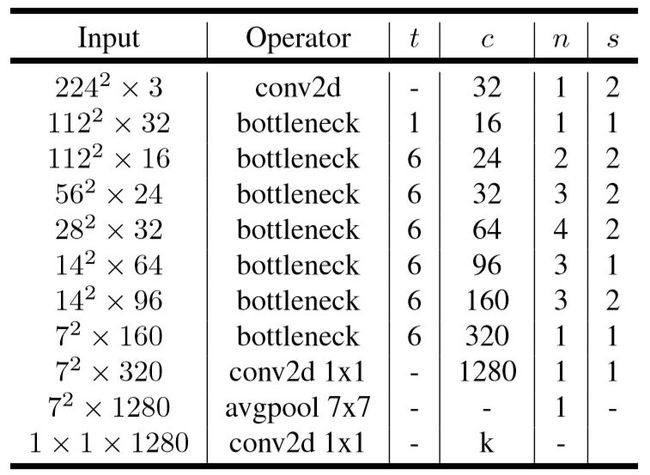
4 一种常规MobileNetv2结构
如下表所示,t 表示bottleneck中“胖瘦”系数,通道数变为几倍;c 表示输出通道数,n 表示bottleneck模块重复了几次,s 表示stride,步长,控制特征图尺寸大小,1的话尺寸不变,2的话,尺寸变为原来的一半,下图中s为1或者2 只针对重复了n次的bottleneck 的第一个bottleneck,重复n次的剩下几个bottleneck中s均为1。
在此处着重强调一下,并不是所有的Inverted residual block都有shortcut短连接的!只有当stride=1(特征图尺寸一致)且输入特征矩阵与输出特征矩阵shape相同(也就是输入输出 通道数c 也要相同)时才有短连接。
5 MobilenetV2代码
直接看代码,可运行,获取网络计算量与参数量。
import torch
from torch import nn
# ------------------------------------------------------#
# 这个函数的目的是确保Channel个数能被8整除。
# 很多嵌入式设备做优化时都采用这个准则
# ------------------------------------------------------#
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
# int(v + divisor / 2) // divisor * divisor:四舍五入到8
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# -------------------------------------------------------------#
# Conv+BN+ReLU经常会用到,组在一起
# 参数顺序:输入通道数,输出通道数...
# 最后的groups参数:groups=1时,普通卷积;
# groups=输入通道数in_planes时,DW卷积=深度可分离卷积
# pytorch官方继承自nn.sequential,想用它的预训练权重,就得听它的
# -------------------------------------------------------------#
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
# 不使用偏置bias,因为使用了BN层,此时偏置不起作用了
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True)
)
# ------------------------------------------------------#
# InvertedResidual,先变胖后变瘦
# 参数顺序:输入通道数,输出通道数,步长,变胖倍数(扩展因子)
# ------------------------------------------------------#
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
# 所谓的隐藏维度,其实就是输入通道数*变胖倍数
hidden_dim = int(round(inp * expand_ratio))
# 只有同时满足两个条件时,才使用短连接
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
# 如果扩展因子等于1,就没有第一个1x1的卷积层
if expand_ratio != 1:
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1)) # pointwise
layers.extend([
# 3x3 depthwise conv,因为使用了groups=hidden_dim
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
# MobileNetV2是一个类,继承自nn.module这个父类
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
"""
super(MobileNetV2, self).__init__()
block = InvertedResidual
# 保证通道数是 8 的倍数,原因是:适配于硬件优化加速
input_channel = _make_divisible(32 * width_mult, round_nearest)
last_channel = _make_divisible(1280 * width_mult, round_nearest)
if inverted_residual_setting is None:
# t表示扩展因子(变胖倍数);c是通道数;n是block重复几次;
# s:stride步长,只针对第一层,其它s都等于1
inverted_residual_setting = [
# t, c, n, s
# 208,208,32 -> 208,208,16
[1, 16, 1, 1],
# 208,208,16 -> 104,104,24
[6, 24, 2, 2],
# 104,104,24 -> 52,52,32
[6, 32, 3, 2],
# 52,52,32 -> 26,26,64
[6, 64, 4, 2],
# 26,26,64 -> 26,26,96
[6, 96, 3, 1],
# 26,26,96 -> 13,13,160
[6, 160, 3, 2],
# 13,13,160 -> 13,13,320
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# conv1 layer
# 416,416,3 -> 208,208,32
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
# -----------------------------------#
# s为1或者2 只针对重复了n次的bottleneck 的第一个bottleneck,
# 重复n次的剩下几个bottleneck中s均为1。
# -----------------------------------#
stride = s if i == 0 else 1
# 这个block就是上面那个InvertedResidual函数
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
# 这一层的输出通道数作为下一层的输入通道数
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, kernel_size=1))
# *features表示位置信息,将特征层利用nn.Sequential打包成一个整体
self.features = nn.Sequential(*features)
# building classifier
# 自适应平均池化下采样层,输出矩阵高和宽均为1
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # 正太分布
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # 展平处理
x = self.classifier(x)
return x
def mobilenet_v2(num_classes: int = 1000):
model = MobileNetV2(num_classes=num_classes)
return model
if __name__ == "__main__":
model = mobilenet_v2()
print(model)
# ------------------------------------#
# 方法1 获取计算量与参数量
# ------------------------------------#
from torchsummaryX import summary
summary(model, torch.zeros(1, 3, 416, 416))
# ------------------------------------#
# 方法2 获取计算量与参数量
# ------------------------------------#
from thop import profile
input = torch.randn(1, 3, 416, 416) # 1张3通道尺寸为416x416的图片作为输入
flops, params = profile(model, (input,))
print(flops, params)
输出:
...
137_features.18.BatchNorm2d_1 2.56k 1.28k
138_features.18.ReLU6_2 - -
139_classifier.Dropout_0 - -
140_classifier.Linear_1 1.281M 1.28M
--------------------------------------------------------------------------------------------------
Totals
Total params 3.504872M
Trainable params 3.504872M
Non-trainable params 0.0
Mult-Adds 1.034246688G
==================================================================================================
[INFO] Register count_convNd() for .
[INFO] Register count_bn() for .
[INFO] Register zero_ops() for .
...
1080294976.0 3504872.0
6 感谢链接
https://blog.csdn.net/weixin_44791964?type=blog
https://www.bilibili.com/video/BV1yE411p7L7/?spm_id_from=333.788