SVD——奇异值分解的原理机制
篇章目录
背景
一、SVD用途概况
优缺点分析
主要应用领域
二、预备知识
1.线性代数、概率论与数理统计常用分布
2.隐形语义含义:隐形语义检索(LSI)
*3.PCA 降维算法原理与应用
三、SVD概念与求解
1. 与PCA的区别
2.求解各种分解矩阵
3.SVD运用于PCA
四、建模实例及代码实现
1.读取相关svd要分解的数据
2.特征值分解实现特征值 以及 特征向量
3.每个特征矩阵的算法实现
完整代码
五、SVD应用拓展
SVD++推荐系统
小结
背景
奇异值分解(SVD),全称:Singular Value Decomposition,是一种提取信息的强大工具,它不仅提供了一种非常便捷的矩阵分解方式,能够发现数据中难以发觉的潜在模式,还能去除噪声和冗余信息,以此达到了优化数据、提高结果的目的。再者,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域,提高对数据利用性。也是很多机器学习算法的基石。废话少谈,让我们赶紧进入原理叙述吧!
一、SVD用途概况
优缺点分析
- 可以简化复杂数据,降低建模实现的时间复杂度
- 提高复杂算法的效率,优化最终效果
- 数据转换或许难以理解
- 不利于数据类型的转换
主要应用领域
- 隐性语义分析 (Latent Semantic Analysis, LSA) 或隐性语义索引 (Latent Semantic Indexing, LSI)
- 矩阵形式数据(对图像数据)的压缩
- 推荐系统:较为先进的推荐系统先利用SVD从数据中构建一个主题空间,然后再在该空间下计算相似度,以此提高推荐的效果
二、预备知识
1.线性代数、概率论与数理统计常用分布
1.1、特征值与特征向量
问题引入:线性方程  是稳定状态的问题,特征值在动态问题中有着巨大的重要性。
是稳定状态的问题,特征值在动态问题中有着巨大的重要性。![]() 的解随着时间增长、衰减或者震荡,是不能通过消元来求解的。
的解随着时间增长、衰减或者震荡,是不能通过消元来求解的。
概念:几乎所有的向量在乘以矩阵 后都会改变方向,某些特殊的向量
后都会改变方向,某些特殊的向量  和
和  位于同一个方向,它们称之为特征向量。固有式子:
位于同一个方向,它们称之为特征向量。固有式子:![]() 。(
。(  即为特征值)
即为特征值)
1.2、幺正矩阵(酉矩阵)
概念(选自百科):如果一个n阶方阵,它的列向量构成一组标准正交基,那么这个矩阵就是幺正矩阵,又称酉矩阵。
性质:① 矩阵U为酉矩阵的充要条件是它的共轭转置矩阵等于其逆矩阵,即 ![]()
② 当A为酉矩阵时,伴随矩阵等于其共轭转置矩阵
③ 酉矩阵的行列式的绝对值为1
④ ![]() , 其中V为幺正矩阵,Σ 是主对角线上元素绝对值为1的对角阵
, 其中V为幺正矩阵,Σ 是主对角线上元素绝对值为1的对角阵
1.3、概率论与数理统计常用分布
常用离散分布
二项分布:记X为n重伯努利试验成功事件(记为A事件)的次数,![]() 。则称X服从二项分布,记符号
。则称X服从二项分布,记符号 ![]() 。公式如下:
。公式如下:
![]()
泊松分布:记X为服从参数为泊松分布,参数λ是单位时间(或单位面积)内随机事件的平均发生次数,适合于描述单位时间内随机事件发生的次数。记符号 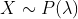 。公式如下:
。公式如下:
![]()
常用连续分布
正态分布:全名Normal Distribution。当在大量随机变量上重复很多次实验时,它们的分布总和将非常接近正态分布。由于人的身高是一个随机变量,并且基于其他随机变量,例如一个人消耗的营养量,他们所处的环境,他们的遗传等等,这些变量的分布总和最终是非常接近正态的,即中心极限定理。故此,正态分布是连续性随机变量函数。记符号 ![]() 。
。
随机变量x的密度函数: ![]()
随机变量x的分布函数:![]()
2.隐形语义含义:隐形语义检索(LSI)
概念:隐式语义分析(Latent Semantic Analysis,LSA),也被称为隐式语义索引(Latent Semantic Indexing,LSI),是一种不同于关键词检索的搜索引擎解决方案,其检索结果的实际效果更接近于人的自然语言,在一定程度上能够提高搜索结果的相关性。所谓隐式语义索引指的是,怎样通过海量文献找出词汇之间的关系。当两个词或一组词出现在同一个文档中时,这些词之间可以被认为是语义相关的。机器并不知道某个词究竟代表什么,不知道某个词是什么意思。具体说来就是对一个大型的文档集合使用一个合理的维度建模,并将词和文档都表示到该空间,比如有2000个文档,包含7000个索引词,LSA使用一个维度为100的向量空间将文档和词表示到该空间,进而在该空间进行信息检索。而将文档表示到此空间的过程就是SVD奇异值分解和LSA降维的过程。通过降维,去除了文档中的“噪音”,即无关信息,语义结构逐渐呈现。相比传统向量空间,潜在语义空间的维度更小,语义关系更明确。
详情转至链接:隐式语义分析
*3.PCA 降维算法原理与应用
概念:在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难。随着数据集维度的增加,算法学习需要的样本数量呈指数级增加。有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习需要更多的内存和处理能力。另外,随着维度的增加,数据的稀疏性会越来越高。在高维向量空间中探索同样的数据集比在同样稀疏的数据集中探索尤为困难。此时,PCA(Principal Component Analysis),即主成分分析,也叫卡尔胡宁-勒夫变换(Karhunen-Loeve Transform),它来了!PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,尽可能地保留住原有的数据。
实质原理:由于 PCA 实质叙述相对复杂,这里只用作者本身观点尽可能形象叙述说明。如果现在我在拍摄一本书,但是这里遇到一个问题——维度的差异。对比下图明显发现,书是三维结构,但是图片仅仅是二维结构,因此如果我要通过图片完整分析实物,固然不可能,除非拍摄了不同位置的全景。对此,利用 PCA 实现降维,举个例子,将方程 ![]() 数据集降维就是把点投射成一条线,数据集的每个样本都可以用一个值表示,不需要两个值。三维数据集可以降成二维,就是把变量映射成一个平面。一般情况下,n 维数据集可以通过映射降成 k 维子空间,其中
数据集降维就是把点投射成一条线,数据集的每个样本都可以用一个值表示,不需要两个值。三维数据集可以降成二维,就是把变量映射成一个平面。一般情况下,n 维数据集可以通过映射降成 k 维子空间,其中 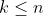 。
。

这里有篇关于主成分分析 PCA 原理叙述不错的文章,推荐读者们去浏览(不是打广告)。
链接:主成分分析(PCA详解)
三、SVD概念与求解
1. 与PCA的区别
SVD与PCA不同,SVD虽然也是对矩阵进行分解,但是与特征分解不同,SVD并不要求分解的矩阵为方阵。PCA是对数据的协方差矩阵进行矩阵的分解,而SVD是直接在原始矩阵上进行的矩阵分解。并且能对非方阵矩阵分解,得到左奇异矩阵  、
、 矩阵、右奇异矩阵
矩阵、右奇异矩阵 。
。
SVD的分解公式(类似于因式分解):![]() 。其中是变换前的原矩阵, 、都是单式矩阵(unitary matrix); 矩阵为对角矩阵,对角元素称为奇异值。形象描绘如下图:
。其中是变换前的原矩阵, 、都是单式矩阵(unitary matrix); 矩阵为对角矩阵,对角元素称为奇异值。形象描绘如下图:

2.求解各种分解矩阵
2.1、矩阵
转置矩阵,得到转置后的矩阵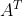 ,作积
,作积 ![]() ,对方阵
,对方阵![]() 进行特征分解,得到
进行特征分解,得到  个特征值
个特征值  和特征向量
和特征向量  ,将所有的特征向量 重新制作成一个全新的方阵 ,即分解矩阵的 ,求解完毕。
,将所有的特征向量 重新制作成一个全新的方阵 ,即分解矩阵的 ,求解完毕。
2.2、矩阵
转置矩阵,得到转置后的矩阵,与分解矩阵 不同,作反积 ![]() ,对方阵
,对方阵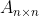 进行特征分解,得到
进行特征分解,得到  个特征值 和特征向量 ,将所有的特征向量 重新制作成一个全新的方阵,即分解矩阵的,求解完毕。
个特征值 和特征向量 ,将所有的特征向量 重新制作成一个全新的方阵,即分解矩阵的,求解完毕。
*2.3、矩阵Σ
通过公式 ![]() ,求得每个i对应的奇异值
,求得每个i对应的奇异值  ,由此求得分解矩阵 完毕。
,由此求得分解矩阵 完毕。
其中求得奇异值 ![]()
3.SVD运用于PCA
- 在PCA讲解中,我们说明了PCA和SVD的不同,但不代表这两者没有相关性。我们在找二者联系时,需要找到样本协方差矩阵的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵,当样本数多样本特征数也多的时候,这个计算量是很大的。
- 另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,这是因为假设我们的样本是的矩阵X,如果我们通过SVD找到了矩阵最大的d个特征向量张成的维矩阵U,可以得到一个的矩阵X‘,这个矩阵和我们原来的维样本矩阵X相比,行数从m减到了k,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
四、建模实例及代码实现
在参考了不少资料后,作者这里打算使用python实现SVD,需要涉及到的库为numpy和pandas。值得一提的是python里有自带的SVD算法实现库(这一点挺良心)。重点的分块代码以及总代码依依给大家介绍。详情如下:
1.读取相关svd要分解的数据
import numpy as np
import pandas as pd
from scipy.io import loadmat
# 读取数据,自己找好路径
train_data_mat = loadmat() #自己设置好路径
train_data = train_data_mat["Data"]
print(train_data.shape)2.特征值分解实现特征值 以及 特征向量
# 这里之所以是除以255.0是优化的结果,使用浮点型优化结果,否则结果会不准确
train_dataFloat = train_data / 255.0
# 计算特征值和特征向量
eval_sigma1,evec_u = np.linalg.eigh(train_dataFloat.dot(train_dataFloat.T))
3.每个特征矩阵的算法实现
#降序排列后,逆序输出
eval1_sort_idx = np.argsort(eval_sigma1)[::-1]
# 将特征值对应的特征向量也对应排好序
eval_sigma1 = np.sort(eval_sigma1)[::-1]
evec_u = evec_u[:,eval1_sort_idx]
# 计算奇异值矩阵的逆
eval_sigma1 = np.sqrt(eval_sigma1)
eval_sigma1_inv = np.linalg.inv(np.diag(eval_sigma1))
# 计算右奇异矩阵
evec_part_v = eval_sigma1_inv.dot((evec_u.T).dot(train_dataFloat))
#这里的evec_u, eval_sigma1, evec_part_v分别代表左奇异矩阵,所有奇异值,右奇异矩阵完整代码
import numpy as np
import pandas as pd
from scipy.io import loadmat
# 读取数据,使用自己数据集的路径。
train_data_mat = loadmat() #自己设置好路径
train_data = train_data_mat["Data"]
print(train_data.shape)
# 数据必需先转为浮点型,否则在计算的过程中会溢出,导致结果不准确
train_dataFloat = train_data / 255.0
# 计算特征值和特征向量
eval_sigma1,evec_u = np.linalg.eigh(train_dataFloat.dot(train_dataFloat.T))
#降序排列后,逆序输出
eval1_sort_idx = np.argsort(eval_sigma1)[::-1]
# 将特征值对应的特征向量也对应排好序
eval_sigma1 = np.sort(eval_sigma1)[::-1]
evec_u = evec_u[:,eval1_sort_idx]
# 计算奇异值矩阵的逆
eval_sigma1 = np.sqrt(eval_sigma1)
eval_sigma1_inv = np.linalg.inv(np.diag(eval_sigma1))
# 计算右奇异矩阵
evec_part_v = eval_sigma1_inv.dot((evec_u.T).dot(train_dataFloat))
五、SVD应用拓展
SVD++推荐系统
SVD++建立于SVD之上,举个例子。如果现在有个客户想要对某视频或文章做出评定,我们不妨考虑用户对物品的隐式行为。因为有时候一个用户的点击,收藏,浏览时长等隐式行为,我们是可以将其考虑进来的,它作为一种交互,也反应了用户的一种隐式意愿。为了将隐式兴趣加入到模型中,在预测规则中加入多一个特征值与特征向量,公式如下:
![]() ,其中
,其中 ![]() 。
。
这里的![]() 指的是用户有交换过的商品,或许将会考虑在内。
指的是用户有交换过的商品,或许将会考虑在内。 指的是和
指的是和![]() 相同的维度的向量。然而,SVD++问题真实的情况却比SVD要复杂得多,增加太多参数可能造成过拟合。不仅如此,SVD++还需要进一步涉及到损失函数、LFM预测公式等概念。详情前往链接参考:SVD++详解
相同的维度的向量。然而,SVD++问题真实的情况却比SVD要复杂得多,增加太多参数可能造成过拟合。不仅如此,SVD++还需要进一步涉及到损失函数、LFM预测公式等概念。详情前往链接参考:SVD++详解
小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。这一点在特征分解中可以减少奇异值的大量批处理计算,简化时间复杂度。SVD最初理解起来相比PCA偏难,但实质原理不难,只要有基本的线性代数知识就可以理解,实现也很简单,因此值得深究。诚然,SVD缺点明显是分解出的矩阵解释性往往不强,这一点类似黑盒,但这不影响它的在机器学习的使用。