B*树索引(第十一章 索引)
Expert Oracle Database Architecture学习笔记
B*树索引(第十一章 索引)
Tom说,B*树索引是“传统索引”。到目前为止,这是Oracle和大多数其他数据库中最常用的索引。需要注意的是,这里的“B”不代表二叉(binary),而是代表平衡(balanced).B*树索引并不是一颗二叉树。
但是,其实现与二叉查找树很相似,其目标是尽可能减少Oracle查找数据所花费的时间。
Tom说话很严谨,他画出了一个示意图,并注明“不严格地说,如果在一个数字列上有一个索引,那么从概念上讲这个结构可能会如图11-1所示”,并进一步说,“也许会有一些块级优化和数据压缩,这些可能会使实际的块结构与图11-1所示并不相同。”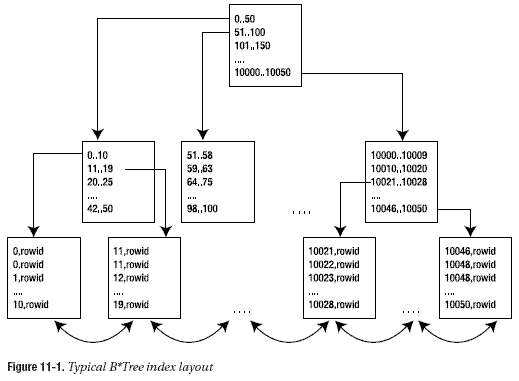
我真佩服Tom的严谨的态度。想想我们身边的许多人和事,要是出一个考试卷,就会有一个标准答案,可是这个答案真的标准吗?尤其是在计算机程序上,同样一个目的可以有许多途径来完成,可是如果你没有使用所谓的“标准答案”,就要被扣分,甚至不能得分。所以在大考试题时,不仅要考虑怎么解答问题,还要考虑出题的人想要哪个答案。呵呵,跑题了,接着做笔记。
这个树最底层的块称为叶子节点(leaf node)或叶子块(leaf block),其中分别包含各个索引建以及一个rowid(指向所索引的行)。叶子节点之上的内部块称为分支块(branch block)。这些节点用于在结构中实现导航。
有意思的是,索引的叶子节点实际上又构成了一个双向链表,执行索引区间扫描(值的有序扫描)也很容易,找到第一个值之后,我们不需要再在索引结构中导航,而只需根据需要,通过叶子节点向前或向后扫描就可以了。所以要满足诸如以下的谓词条件将相当简单:
where x between 20 and 30
Oracle发现第一个最小值大于或等于20的索引叶子块,然后水平地遍历叶子节点链表,直到命中一个大于30的值。
B*树索引中不存在非唯一(nonunique)条目。在一个非唯一索引中,Oracle会把rowid作为一个额外的列追加到键上,使得键唯一。在一个唯一索引中,根据你定义的唯一性,Oracle不会再向索引建增加rowid。
B*树的特点之一是,所有叶子块都应该在书的同一层上。(这一段好像翻译的有些小问题,所以把Tom的原文抄写如下)
One of the properties of a B*Tree is that all leaf blocks should be at the same level in the tree. This level is also known as the height of the index, meaning that any traversal from the root block of the index to a leaf block will visit the same number of blocks. That is, to get to the leaf block to retrieve the first row for a query of the form "SELECT INDEXED_COL FROM T WHERE INDEXED_COL = :X" will take the same number of I/Os regardless of the value of :X that is used. In other words, the index is height balanced. Most B*Tree indexes will have a height of 2 or 3, even for millions of records. This means that it will take, in general, two or three I/Os to find your key in the index—which is not too bad.
B*树是一个绝佳的通用索引机制,无论是大表还是小表都很适用,随着底层表达小的增长,获取数据的性能只会稍有恶化(或者根本不会恶化)。