Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation论文解读
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation

论文:[2105.05537] Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation (arxiv.org)
代码:HuCaoFighting/Swin-Unet: The codes for the work “Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation” (github.com)
期刊/会议:ECCV2021
摘要
在过去的几年中,卷积神经网络(CNN)在医学图像分析方面取得了里程碑式的进展。特别是基于U型结构和跳跃连接的深度神经网络在各种医学图像任务中得到了广泛的应用。然而,尽管CNN已经取得了优异的性能,但由于卷积运算的局部性,它不能很好地学习全局和长程的语义信息交互。在本文中,我们提出了Swin-Unet,它是一个类Unet的纯Transformer,用于医学图像分割。Token化的图像patch被输入到基于transformer的U型编码器-解码器架构中,并具有跳跃连接,用于局部全局语义特征学习。具体来说,我们使用带有移位窗口(shifted windows)的分层Swin Transformer作为编码器来提取上下文特征。设计了一种基于对称Swin Transformer的patch expanding层解码器,对特征图进行上采样操作,恢复特征图的空间分辨率。在输入输出直接下采样和上采样4倍的情况下,对多器官和心脏分割任务的实验表明,纯基于Transformer的U型编码器-解码器网络优于全卷积或Transformer与卷积结合的方法。
1、简介
得益于深度学习的发展,计算机视觉技术已广泛应用于医学图像分析。图像分割是医学图像分析的重要组成部分。特别是,准确而鲁棒的医学图像分割在计算机辅助诊断和图像引导临床手术中起着至关重要的作用。
现有的医学图像分割方法主要依靠U型结构的全卷积神经网络(FCNN)。典型的U型网络U-Net由一个具有跳跃连接的对称编码器-解码器组成。在编码器中,使用一系列卷积层和连续下采样层来提取具有大感受野的深度特征。然后,解码器将提取的深度特征上采样到输入分辨率进行像素级语义预测,并将来自编码器的不同尺度的高分辨率特征进行跳跃连接融合,以缓解下采样造成的空间信息丢失。凭借如此优雅的结构设计,U-Net在各种医学成像应用中取得了巨大的成功。按照这一技术路线,已经开发了3D U-Net、Res-UNet、U-Net++和UNet3+等算法,用于各种医学成像方式的图像和体积分割(volumentric segmentation)。这些基于FCNN的方法在心脏分割、器官分割和病变分割方面的优异表现证明了CNN具有较强的特征学习辨别能力。
目前,基于CNN的方法虽然在医学图像分割领域取得了优异的性能,但仍不能完全满足医学应用对分割精度的严格要求。图像分割仍然是医学图像分析中的一个具有挑战性的任务。由于卷积运算固有的局部性,基于CNN的方法很难学习显式的全局和远程语义信息交互。一些研究试图通过使用atrous卷积层、自注意机制和图像金字塔来解决这个问题。然而,这些方法在建模长期依赖关系时仍有局限性。最近,受Transformer在自然语言处理(NLP)领域的巨大成功的启发,研究人员试图将Transformer引入视觉领域。在VIT论文中,提出了视觉转换器(ViT)来执行图像识别任务。以带有位置嵌入的二维图像patch为输入,在大型数据集上进行预训练,其性能与基于CNN的方法相当。此外,DeiT中提出了数据高效图像转换器(data-efficient image transformer, DeiT),这表明transformer可以在中等规模的数据集上进行训练,并将其与蒸馏方法相结合,可以获得更鲁棒的transformer。在Swin transformer论文中,开发了一个分层的Swin Transformer。[19]以Swin Transformer为视觉骨干网络,在图像分类、目标检测和语义分割等方面取得了最先进的性能。ViT、DeiT和Swin Transformer在图像识别任务中的成功证明了Transformer在视觉领域的应用潜力。
在Swin Transformer的成功的激励下,我们提出Swin-Unet在这项工作中利用Transformer的强大功能进行2D医学图像分割。据我们所知,Swin-Unet是第一个纯基于transformer的U型架构,由编码器、瓶颈(bottleneck)、解码器和跳跃连接(skip connection)组成。编码器、瓶颈和解码器都是基于Swin Transformer区块构建的。将输入的医学图像分割成不重叠的图像patch。每个patch都被视为一个token,并输入到基于transformer的编码器中,以学习深度特征表示。解码器利用patch expanding层对提取的上下文特征进行上采样,并与编码器的多尺度特征进行跳跃连接融合,恢复特征映射的空间分辨率,进而进行分割预测。在多器官和心脏分割数据集上的大量实验表明,该方法具有良好的分割精度和鲁棒的泛化能力。具体来说,我们的贡献可以概括为:(1)基于Swin Transformer块,我们构建了一个具有跳跃连接的对称编码器-解码器架构。在编码器中,实现了从局部到全局的自注意力机制;在解码器中,全局特征被上采样到输入分辨率,用于相应的像素级分割预测。(2)设计了一种patch expanding层,在不使用卷积和插值运算的情况下实现上采样和特征维的增加。(3)在实验中发现,对于Transformer,跳跃连接也是有效的,因此最终构造了一个纯基于Transformer的带有跳跃连接U型编码器-解码器架构,命名为Swin-Unet。
2、相关工作
基于CNN的方法: 早期的医学图像分割方法主要是基于轮廓和传统的基于机器学习的算法。随着深度CNN的发展,提出了U-Net用于医学图像分割。由于U型结构简单、性能优越,各种类Unet方法不断涌现,如Res-UNet、Dense-UNet、U-Net++、UNet3+等。并将其引入到三维医学图像分割领域,如3D-Unet[和V-Net。目前,基于CNN的方法由于其强大的表示能力在医学图像分割领域取得了巨大的成功。
Vision Transformer:Transformer最初是在机器翻译任务提出的。在自然语言处理领域,基于transformer的方法在各种任务中都取得了最先进的性能。在Transformer成功的推动下,研究人员在中引入了一个开创性的视觉Transformer(ViT),它在图像识别任务中实现了令人印象深刻的速度-精度权衡。与基于CNN的方法相比,ViT的缺点是需要在自己的大型数据集上进行预训练。为了减轻训练ViT的困难,Deit描述了几种训练策略,使ViT在ImageNet上训练得很好。近年来,基于ViT的一些优秀工作已经完成。值得一提的是,提出了一种高效有效的分层视觉转换器Swin Transformer作为视觉主干网络。基于移动窗口机制,Swin Transformer在图像分类、目标检测和语义分割等各种视觉任务上都取得了最先进的性能。在这项工作中,我们尝试使用Swin Transformer块作为基本单元来构建一个U型编码器-解码器为医学图像分割提供了具有跳跃式连接的架构,从而为Transformer在医学图像领域的发展提供了基准比较。
self-attention/transformer对比CNN:近年来,研究人员尝试在CNN中引入自注意机制,以提高网络的性能。在一些工作中,采用U型结构集成了带有附加注意门的跳跃连接,用于医学图像分割。然而,这仍然是基于CNN的方法。目前,一些人正在努力将CNN和Transformer结合起来,以打破CNN在医学图像分割中的主导地位。在一些工作中,研究者将Transformer与CNN相结合,构成了用于二维医学图像分割的强编码器,也有研究学者利用Transformer和CNN的互补性来提高模型的分割能力。目前,Transformer与CNN的各种组合应用于多模态脑肿瘤分割和三维医学图像分割。与上述方法不同,我们尝试探索纯Transformer在医学图像分割中的应用潜力。
3、方法
3.1 模型架构总览
我们所提出的Swin-Unet的总体架构如图1所示。Swin-Unet由编码器、瓶颈(bottleneck)、解码器和跳过连接组成。Swin-Unet的基本单元是Swin Transformer block。编码器将医学图像分割成不重叠的patch, patch大小为4 × 4,将输入信息转换为序列嵌入。通过这种划分方法,每个patch的特征维数为4 × 4 × 3 = 48。将投影的特征维度线性嵌入层转化为任意维度(表示为C),转换后的patch token通过多个Swin Transformer块和patch合并层生成分层的特征表示。其中,patch merge层负责降采样和增维,Swin Transformer块负责特征表示学习。以U-Net为灵感,设计了一种基于对称transformer的解码器。该解码器由Swin Transformer block和patch expanding层组成。通过跳跃式连接将提取的上下文特征与编码器的多尺度特征融合,弥补了下采样造成的空间信息丢失。与patch merge层相比,patch expanding层被专门设计来执行上采样。patch expanding层将相邻维度的特征图重新塑造为分辨率为2倍上采样的大特征图。最后使用最后一层patch展开层进行4×上采样,将特征图的分辨率恢复到输入分辨率(W × H),然后对这些上采样的特征进行线性投影层,输出像素级分割预测。我们将在下面详细说明每个区块。
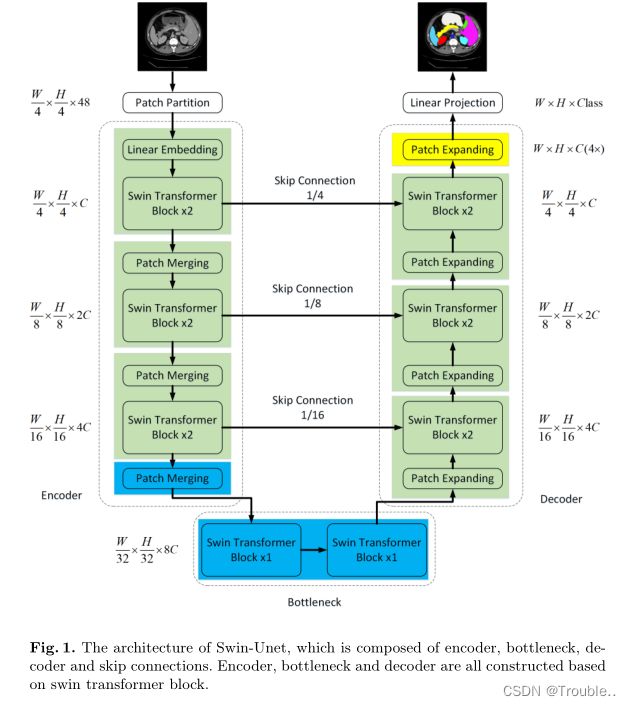
3.2 Swin Transformer block

与传统的多头自注意(MSA)模块不同,Swin Transformer block是基于shifted window构造的。在图2中,给出了两个连续的Swin Transformer block。每个Swin Transformer block由LayerNorm (LN)层、多头自注意模块、残差连接和具有GELU非线性的2层MLP组成。基于窗口的multi-head self-attention (W-MSA)模块和基于移位窗口的multi-head self-attention (SW-MSA)模块分别应用于这两个transformer block。基于这种窗口划分机制,连续swin transformer block可以表示为:
z ^ l = W − M S A ( L N ( z l − 1 ) ) + z l − 1 \hat z^l=W-MSA(LN(z^{l-1}))+z^{l-1} z^l=W−MSA(LN(zl−1))+zl−1
z l = M L P ( L N ( z ^ l ) ) + z ^ l z^l=MLP(LN(\hat z^l))+\hat z^l zl=MLP(LN(z^l))+z^l
z ^ l + 1 = S W − M S A ( L N ( z l ) ) + z l \hat z^{l+1}=SW-MSA(LN(z^l))+z^l z^l+1=SW−MSA(LN(zl))+zl
z l + 1 = M L P ( L N ( z ^ l + 1 ) ) + z ^ l + 1 z^{l+1}=MLP(LN(\hat z^{l+1}))+\hat z^{l+1} zl+1=MLP(LN(z^l+1))+z^l+1
其中 z ^ l \hat z^l z^l和 z ^ l \hat z^l z^l代表(S)W-MSA和MLP模块在第 l l l个block的输出。和先前的工作类似,self-attention计算计算如下所示:
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T d + B ) V Attention(Q,K,V)=SoftMax(\frac{QK^T}{\sqrt{d}}+B)V Attention(Q,K,V)=SoftMax(dQKT+B)V
Q , K , V ∈ R M 2 × d Q,K,V \in \R^{M^2 \times d} Q,K,V∈RM2×d指的是query,key,value向量。 M 2 , d M^2,d M2,d分别指的是patch在窗口中的数量和query/key的向量维度。 B B B是偏置,来自偏置矩阵 B ^ ∈ R ( z M − 1 ) × ( 2 M + 1 ) \hat B\in \R^{(zM-1) \times (2M+1)} B^∈R(zM−1)×(2M+1)
3.3 Encoder
在编码器中,分辨率为 H 4 × H 4 \frac{H}{4} \times \frac{H}{4} 4H×4H的 C C C维标记化输入被输入到两个连续的Swin Transformer block中进行表示学习,其中特征维度和分辨率保持不变。同时,patch merge层将减少token数量(2× downsampling),并将特征维数增加到原始维数的2×。这个过程将在编码器中重复三次。
Patch merge layer:输入的patch被分成4个部分,并通过patch合并层连接在一起。通过这样的处理,特征分辨率将降低2倍。由于级联操作导致特征维数增加4倍,因此在级联后的特征上加线性层,使特征维数统一为原始维数的2倍。
3.4 Bottleneck
由于Transformer深度太深,无法收敛,因此只用两个连续的Swin Transformer块构造瓶颈来学习深度特征表示。在瓶颈区,特征维数和分辨率保持不变。
3.5 Deccoder
与encoder相对应的是基于Swin Transformer block的对称decoder。为此,与编码器中使用的patch merge layer相比,我们在encoder中使用patch expand layer对提取的深层特征进行上采样。patch expand layer将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数降低到原维数的一半。
patch expand layer:以第一个patch expand layer为例,在上采样前,对输入特征( W 32 × W 32 × 8 C \frac{W}{32} \times \frac{W}{32} \times 8C 32W×32W×8C)施加线性层,将特征维数增加到原维数( W 32 × W 32 × 16 C \frac{W}{32} \times \frac{W}{32} \times 16C 32W×32W×16C)的2倍。然后,我们使用重排操作将输入特征的分辨率扩大到输入分辨率的2倍,并将特征维数减小到输入维数的四分之一( W 32 × W 32 × 16 C → W 16 × W 16 × 4 C \frac{W}{32} \times \frac{W}{32} \times 16C \to \frac{W}{16} \times \frac{W}{16} \times 4C 32W×32W×16C→16W×16W×4C)。我们将在4.5节中讨论使用patch expand layer执行上采样的影响。
3.6 skip connection
类似于U-Net,跳跃连接用于融合编码器的多尺度特征与上采样特征。我们将浅层特征和深层特征拼接在一起,减少了下采样造成的空间信息损失。接着是线性层,连接特征的维数保持与上采样特征的维数相同。在4.5节中,我们将详细讨论跳过连接的数量对模型性能的影响。
4、实验
4.1 数据集
Synapse multi-organ segmentation dataset (Synapse):数据集包括30例病例3779张轴向腹部临床CT图像。将18个样本分为训练集,12个样本分为测试集。并以Dice-similarity coefficient(DSC)和average Hausdorff Distance(HD)作为评价指标,对8个腹部器官(主动脉、胆囊、脾脏、左肾、右肾、肝脏、胰腺、脾脏、胃)进行了评价。
Automated cardiac diagnosis challenge dataset (ACDC):ACDC数据集是使用MRI扫描仪从不同的患者中收集的。对于每个患者的MR图像,左心室(LV),右心室(RV)和心肌(MYO)被标记。数据集分为70个训练样本,10个验证样本和20个测试样本。仅使用平均DSC来评估此数据集上的方法。
4.2 实施细节
Swin-Unet是基于Python 3.6和Pytorch 1.7.0实现的。对于所有训练案例,数据增强(如翻转和旋转)用于增加数据多样性。输入图像大小设置为224×224, patch大小设置为4。我们用32GB内存的Nvidia V100 GPU训练我们的模型。在ImageNet上预训练的权重用于初始化模型参数。在训练期间,batch size为24,使用动量为0.9,权重衰减为1e-4的SGD优化器来优化我们的反向传播模型。
4.3 在Synapse数据集上的实验结果
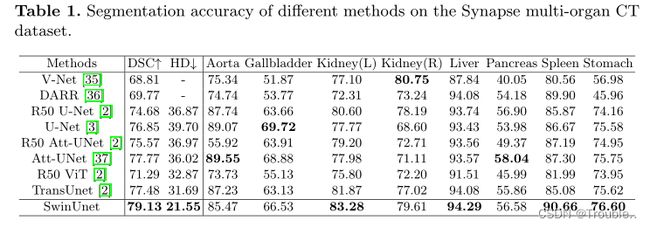
所提出的Swin-Unet与之前Synapse多器官CT数据集上最先进的方法的比较如表1所示。与TransUnet不同,我们在Synapse数据集上添加了我们自己实现的U-Net和Att-UNet的测试结果。实验结果表明,本文提出的类Unet纯transformer方法具有最佳的分割精度,分割精度分别为79.13%(DSC↑)和21.55%(HD↓)。与Att-Unet和最近的TransUnet方法相比,虽然我们的算法在DSC评价指标上没有太大的改进,但在HD评价指标上的精度提高了约4%和10%,这表明我们的方法可以实现更好的边缘预测。不同方法在Synapse多器官CT数据集上的分割结果如图3所示。从图中可以看出,基于CNN的方法容易出现过分割的问题,这可能是由于卷积运算的局部性造成的。在这项工作中,我们证明了通过将Transformer与具有跳过连接的U型架构集成在一起,没有卷积的纯Transformer方法可以更好地学习全局和远程语义信息交互,从而获得更好的分割结果。

4.4 在ACDC数据集上的实验结果
与Synapse数据集类似,所提出的Swin-Unet在ACDC数据集上进行训练,以执行医学图像分割。实验结果如表2所示。使用MR模式的图像数据作为输入,SwinUnet仍然能够取得优异的性能,准确率达到90.00%,说明我们的方法具有良好的泛化能力和鲁棒性。

4.5 消融实验
为了探究不同因素对模型性能的影响,我们对Synapse数据集进行了消融研究。具体地说,上采样,跳过连接的数量,输入大小和模型尺度将在下面讨论。
上采样效果:与编码器中的patch merge layer相对应,我们在解码器中专门设计了patch expand layer来进行上采样和特征维的增加。为了探索所提出的patch expand layer的有效性,我们在Synapse数据集上进行了双线性插值、转置卷积和补丁扩展层的Swin-Unet实验。表3的实验结果表明,本文提出的Swin-Unet结合patch展开层可以获得更好的分割精度。

跳跃连接数量的影响:我们的SwinUNet的跳跃连接被添加在1/4、1/8和1/16分辨率尺度的地方。通过将跳过连接数分别更改为0、1、2和3,我们探索了不同的跳过连接对所提出模型分割性能的影响。在表4中,我们可以看到,随着跳过连接数的增加,模型的分割性能有所提高。因此,为了使模型更具鲁棒性,本文将跳过连接数设置为3。

输入尺寸的影响:以224 × 224,384 × 384的输入分辨率作为输入,所提出的Swin-Unet的测试结果如表5所示。当输入大小从224 × 224增加到384 × 384, patch大小保持为4时,Transformer的输入token序列会变大,从而提高模型的分割性能。然而,虽然模型的分割精度略有提高,但整个网络的计算负荷也明显增加。为了保证算法的运行效率,本文实验以224 × 224分辨率尺度作为输入。

模型尺度的影响:,我们讨论了网络深化对模型性能的影响。从表6可以看出,模型规模的增加并没有提高模型的性能,反而增加了整个网络的计算成本。考虑到精度和速度的平衡,我们采用基于tiny的模型进行医学图像分割。

4.6 讨论
众所周知,基于transformer的模型的性能受到模型预训练的严重影响。在这项工作中,我们直接使用ImageNet上Swin Transformer的训练权值来初始化网络编码器和解码器,这可能是一种次优方案。这种初始化方法很简单,未来我们将探索如何对Transformer进行端到端的预训练,以用于医学图像分割。此外,由于本文的输入图像为2D图像,而医学图像数据大多为3D图像,因此我们将在接下来的研究中探索Swin-Unet在三维医学图像分割中的应用。
5、总结
本文介绍了一种新型的基于纯Transformer的U形编解码器用于医学图像分割。为了充分发挥Transformer的强大功能,我们将Swin Transformer块作为特征表示和远程语义信息交互学习的基本单元。广泛在多器官和心脏分割任务上的实验表明,所提出的Swin-Unet具有良好的性能和泛化能力。