Transformer模型学习笔记
Transformer模型
1 seq2seq方法对比
CNN:将序列分为多个窗口(卷积核),每个窗口具有相同的权重,可以带来平移不变性的好处;卷积核之间可以进行并行计算;根据局部关联性建模,若想获得更大的感受野,除了增加卷积核尺寸,还需要增加多层卷积;对相对位置敏感(旋转),对绝对位置不敏感(顺序)。
RNN:对顺序敏感;无法并行计算,耗时;长程建模能力弱(前后序列跨度大,若保存数据则耗费空间过大);对相对位置敏感,对绝对位置敏感。
Transformer:无局部假设,对相对位置不敏感;无有序假设,可并行计算,对绝对位置不敏感,需要增加位置编码来反应位置变化对于特征的影响;任意长度字符都可以建模,依赖自注意力机制,复杂度为序列长度平方级。
2 模型框架
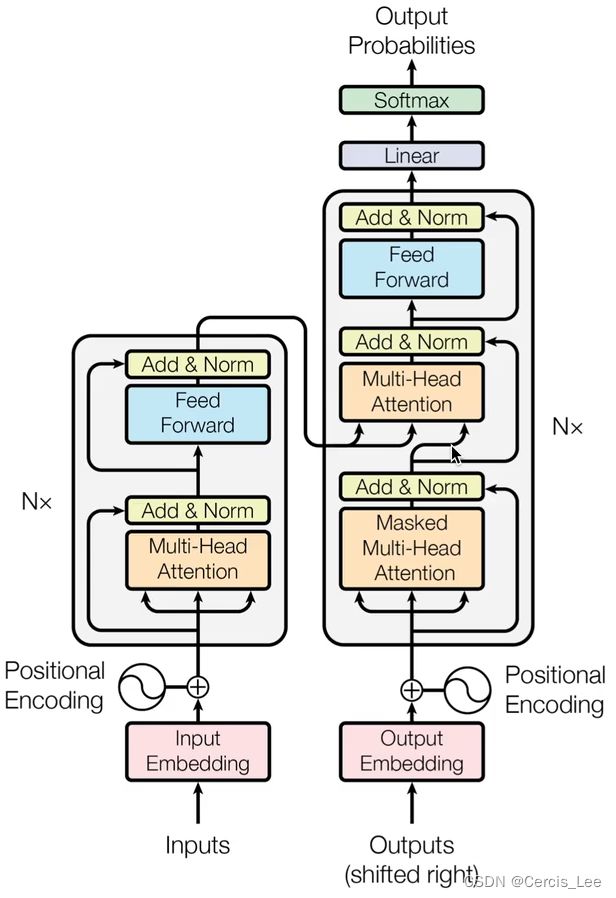
encoder:将输入字符embedding的结果和位置编码作为输入,经过N个block(多头注意力模块、前馈神经网络模块),输出状态。
decoder:以上一状态的字符、位置编码、encoder的状态输出作为输入,经过N个block(带掩码的多头注意力模块和与Encoder相同的模块),输出预测概率。
3 Encoder:
将输入序列数据(x1,…,xn)转化为(z1,…,zn),其中xt为序列中第t位字符,zt为xt的向量标示。
Encoder的层数N可以设定,每一层有两个子层,包括Mult-Head Attention和Feed Forward,并在每一个子层后面增加一个残差连接,最后进行标准化Norm,用公式表示即为:LayerNorm(x+Sublayer(x))。
与CNN每一层的数据维度递减channel数增加不同,Transformer的每一层数据的维度都设置为固定值d(model)。
3.1 Layernorm:
与batchnorm对每个feature做Norm不同,layernorm针对的是每个样本。
如果数据的长度变化较大时,使用batchnorm做均值和方差的抖动也会很大。
3.2 Input Embedding:
使稀疏的one-hot数据,通过不带bias的FCNN得到稠密的连续向量。
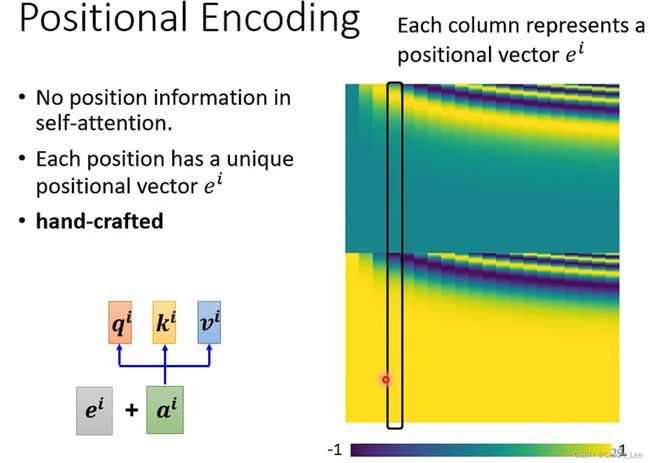
3.3 Position Encoding:
(原本无位置信息)
添加位置编码,使位置参数对Transformer有影响。
由于不同长度的序列数据位置编码可能不同,需要使用sin/cos来固定。
对于不同的句子,相同位置的距离一致。
可以推广到更长的测试句子,pe(pos+k)可以写成pe(pos)的线性组合。
通过残差连接使得位置信息流入深层。
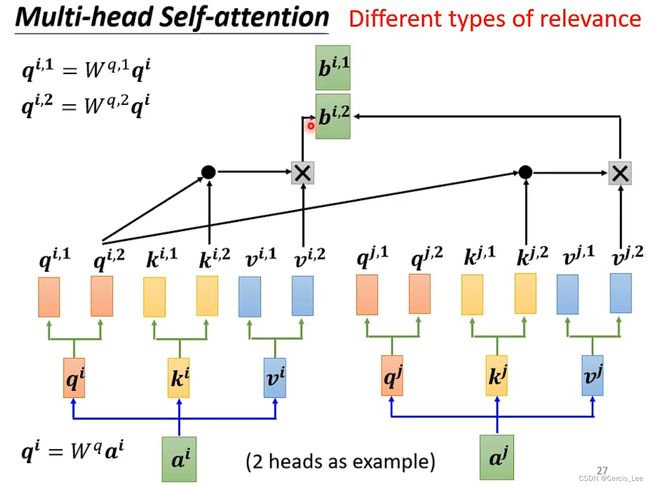
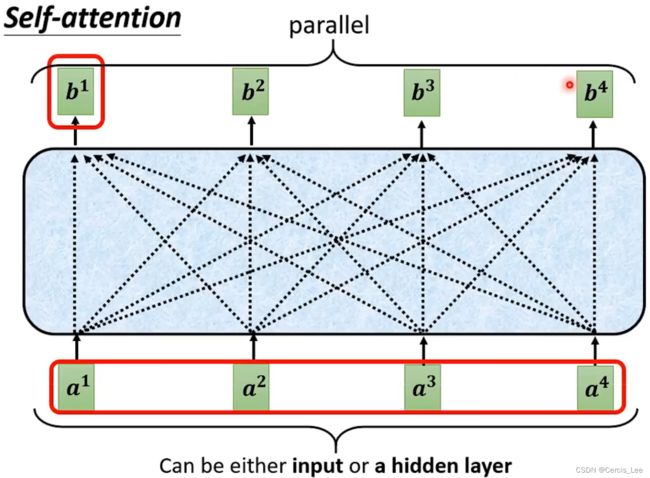
3.4 Multi-head Attention:
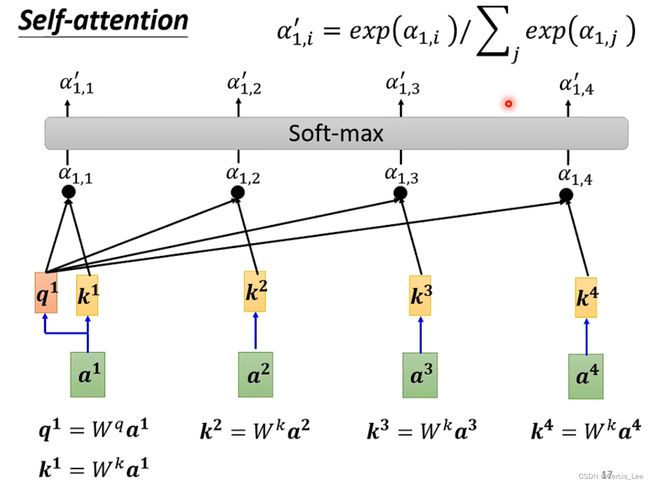
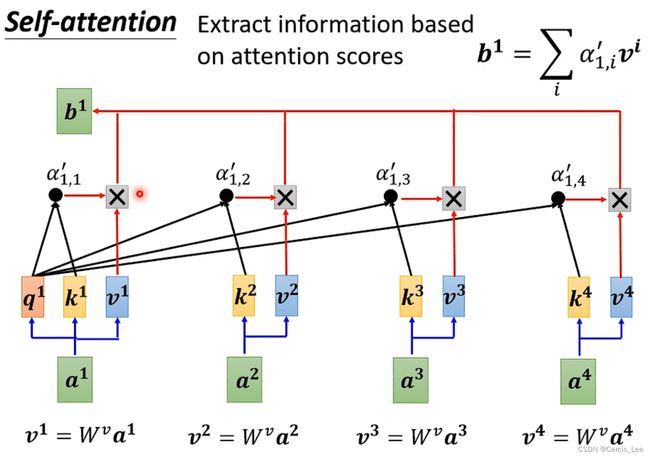
由多组Q,K,V组成,每组单独计算一共attention向量。
把每组attention向量拼接,通过一个FNN得到最终向量。
使得建模能力更强,表征空间更丰富。
可以使得特征向量维度降低,比如8个自监督模块可以将512维数据降低成64维。
可以弥补无法做到CNN多输出通道的缺陷。
3.5 Feed-Forward Network:
对每个单独位置上的字符建模,不同位置参数共享。
4 Decoder:
将Encoder的输出数据(z1,…,zn),转化为(y1,…,ym),与Encoder不同,编码器可以一次得到该批次所有字符,而解码器只能一个一个读取并输出(自回归)(auto-regressive)(RNN)
Encoder的每层有与Encoder相同的两个子层以外,还有一个Masked Multi-head Attention的子层。
4.1 Output Word Embedding:
另外一个序列的Embedding。在做预测时没有输入。
4.2 Masked Multi-head Self-attention:
因为Decoder是自回归模型,所以需要增加掩码机制,使得每次读取当前字符时不受当前时刻后的字符的干扰。机制是将t时刻之后的数值设置为非常大的负数,使其进入softmax时值接近于0。
4.3 Multi-head Attention:
如 3.4 5.2
5 Attention
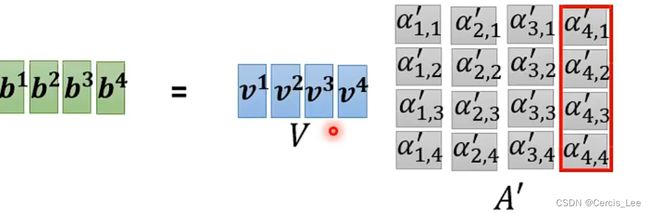
Attention函数的功能就是将query向量和key-value向量映射成一个output,output = weight * values,所以output的维度与value的维度相同,其中weight为key与query的相似度。
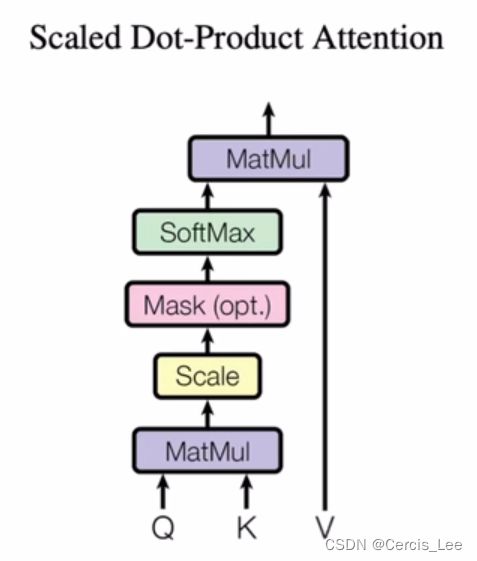
5.1 Scaled Dot-Product Attention(Self-Attention)
query和keys等长,维度为d(k),vaue维度为d(v)。对每一个query与keys做内积,把它作为相似度。再除以向量的长度(d(k))^(1/2),得到k个权值,再将这k个权重做softmax,得到k个合为1的权重。
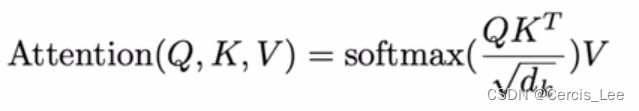
Q:n*d(k)
K:m*d(k)
Q(K)^T:n*m
V:m*d(v)
Output:n*d(v)
其中Q、K、V以及相似度的计算过程可以抽象成矩阵乘法:
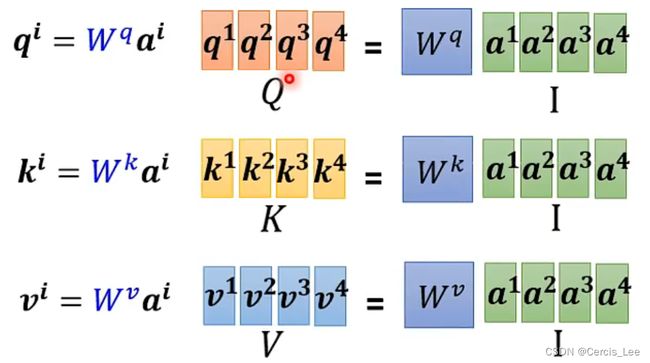

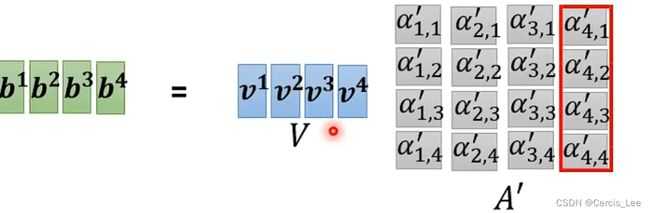
很容易实现并行计算。

Query和K等长的情况下可以采用该算法,在不等长的情况下,可以采用Additive Attention的方式。
为什么要除dk?:使用Transformer的序列维度一般比较大,做点积时的结果会很大或很小,导致不同的Key计算出来的差距会比较大,在经过softmax以后,有的值会很接近于1,有的值会很接近于0,会产生梯度消失或梯度爆炸。
5.2 Multi-head Attention
将a映射(乘一个矩阵)生成的q,k,v再通过一次映射(再乘一个矩阵),将其维度平分,使所有下标相同的q,k,v分给相同的Attention。