医保反欺诈:用大数据守住人民的保命钱
2020年12月28日,国家医保局公布了新版《国家基本医疗保险、工伤保险和生育保险药品目录(2020年)》。本次目录调整首次尝试对目录内药品进行降价谈判。在医保谈判现场,谈判专家和药企代表你来我往,上演“灵魂砍价”!
“4.4元,4太多,难听,再便宜点。”“降价别跟挤牙膏似的!”
最终,119种药品谈判成功,平均降价50.64%。通过调整医保药品结构、优化药品价格,在不额外增加医保基金负担的情况下,满足了更多百姓看病的用药需求。新目录将于2021年3月1日在全国范围启用。值得关注的是,最新版国家新冠肺炎诊疗方案所列药品已全部纳入国家医保目录,为打赢这场仍在蔓延的新冠疫情阻击战注入了必胜的信心。

社会医疗保险作为我国基础保险制度,医保基金被形象地称为老百姓的“保命钱”。谈判代表在谈判桌上一分一厘的“较真”,就是为了老百姓守住这份“保命钱”。然而,有一部分人为了自己的利益,在报销规则上钻空子,利用伪造发票、重复就诊、重复开药、冒名就医、支付非医保药费或诊疗项目等各种方式骗取医保基金,导致医保基金大量流失。

中国社会保障学会日前发布的《中国医疗保障发展报告2020》中,全球因欺诈导致的医疗保险基金损失占医保基金支出的4.57%。以此为标准,按照2019年全国医保总支出20854亿元计算,2019年全国医保基金因欺诈的损失高达953.03亿元。
2020年7月9日,我国第一部国家层面的医保基金监管文件《关于推进医疗保障基金监管制度体系改革的指导意见》由国务院办公厅印发,《意见》中要求依托现代技术,强化事前、事中监管是一大亮点。
大数据、人工智能发展至今已在诸多领域成功应用落地,发挥了巨大的价值。在医疗领域,大数据、人工智能等技术为医保反欺诈增加了新的防控手段。

通过机器学习算法模型对结算数据、电子病历等平台采集的住院、门诊相关数据进行全方位、多维度、长周期的分析,挖掘其中的行为模式、常用药物和治疗项目,再根据聚类算法,将存在其中的真实性问题数据识别出来,建立医保反欺诈模型,自动识别医保欺诈行为,减少医保基金的流失。
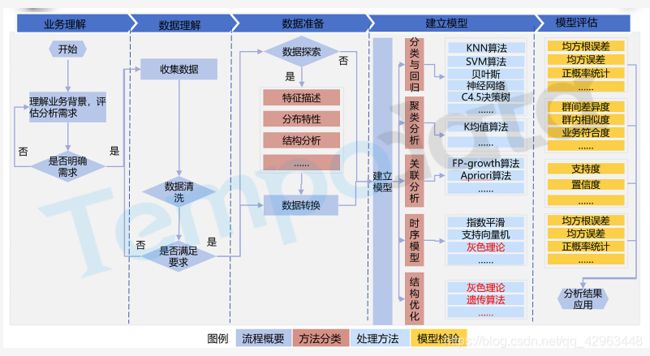
基于数据挖掘的标准流程分为五个大的步骤——业务理解、数据理解、数据准备、建立模型和模型评估。
医保反欺诈分析
在本案例中,医保反欺诈分析的流程包括:业务理解、数据收集和理解、数据预处理、特征分析、样本集筛选、模型训练与评估。
1、业务理解
首先是对医保欺诈行为进行业务理解,分解出医保欺诈的具体行为和相关特征。以医保欺诈中的个人骗保和组织骗保为例,聚焦医保资金套现的具体手段,包括但不限于虚报病情、伪造票据、挂名住院、冒名就医等。
2、数据收集和理解
基于业务理解,确定需要收集的数据内容。通过医保结算等系统收集患者信息表、消费明细表、处方信息表、住院记录等,并对医保反欺诈模型构建所需要的数据字段进行筛选。
3、数据预处理
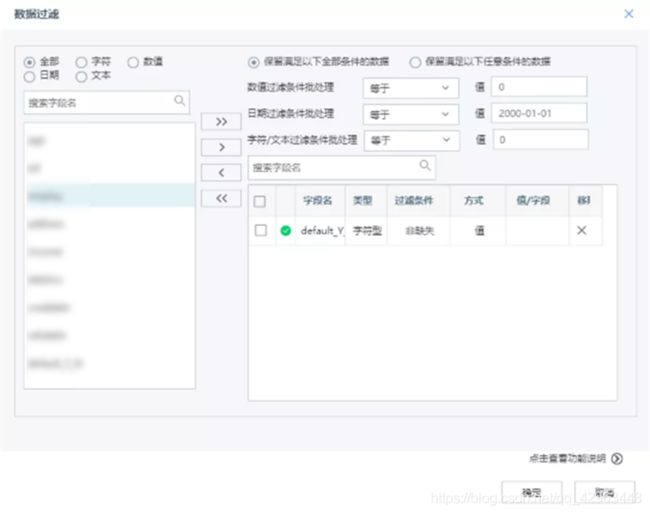
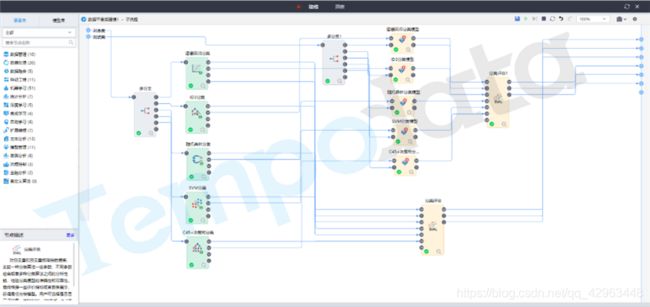
将医保报销系统中的原始数据导入TempoAI。为了确保模型质量,首先需要对数据信息进行预处理操作。通过平台的“属性过滤”节点抽取所需字段,并完成字段类型转换,使用“重命名”、“数据过滤”、“数据连接”等节点完成数据的处理工作,得到包括报销单号、医保编号、门诊号、住院号、门诊挂号日期、住院日期、出院结算日期、报销金额、病种编码等分析所需的数据。

4、特征分析
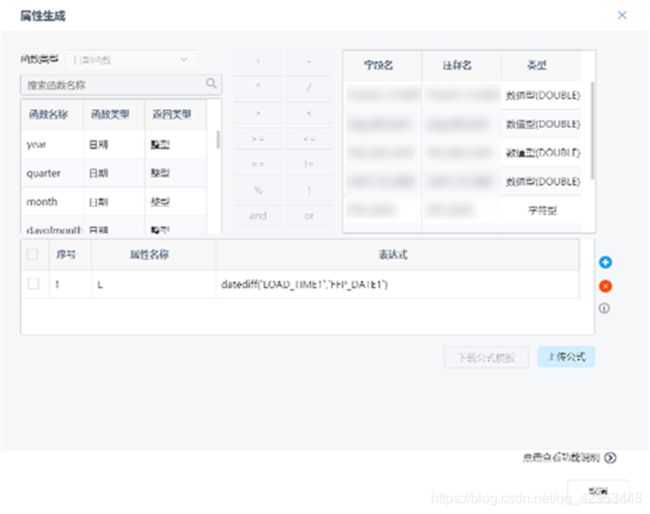
在完成数据预处理后,从这些数据中探索欺诈行为的特征,例如:医保账号在过去一段时间的平均门诊次数、住院次数、住院时长、报销金额、报销次数等内容是否远超平均水平,如果有就意味存在欺诈的嫌疑。针对这些特征,通过“数据过滤”与“属性生成”节点,筛选、计算、新增所需的字段,包括平均门诊次数、平均住院次数、平均住院时长、平均报销金额、超平均住院时长、超平均报销金额次数共计六个数据。
5、样本集筛选
通过箱线图对数据的分布情况进行观察,以确保所获取的“特征字段”数据的可靠性。
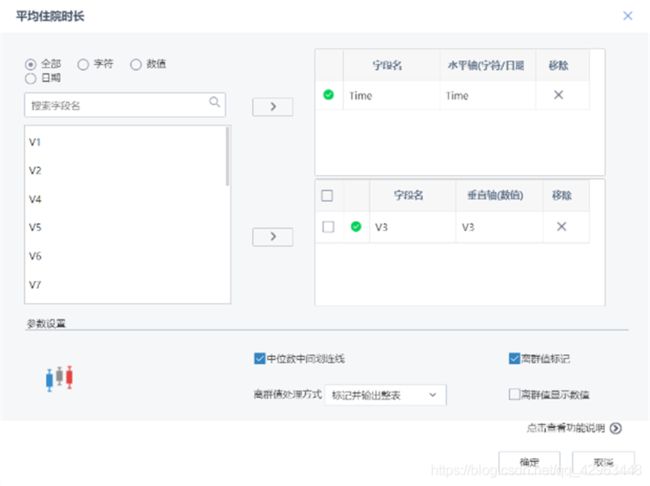
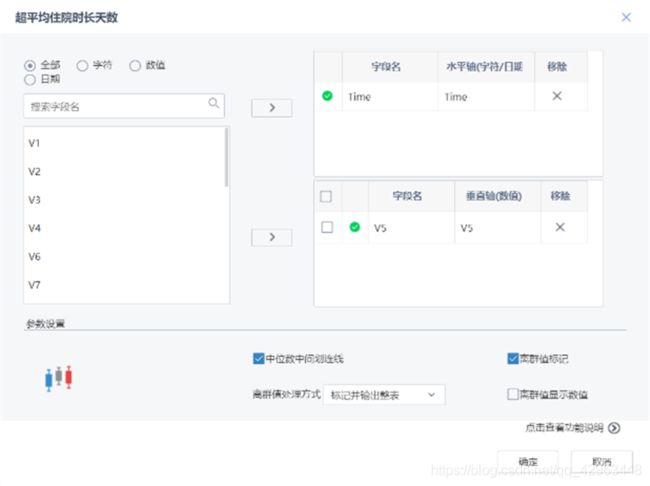
通过箱线图确认特征的可靠性后,基于这些特征对样本数据进行聚类分析,获取到正、负样本的两个数据集。正样本为“欺诈行为”,负样本为“正常行为”。按比例用随机抽样抽取正负样本,形成训练集与测试集,为接下来的模型训练与评估提供数据支撑。
6、模型训练与评估
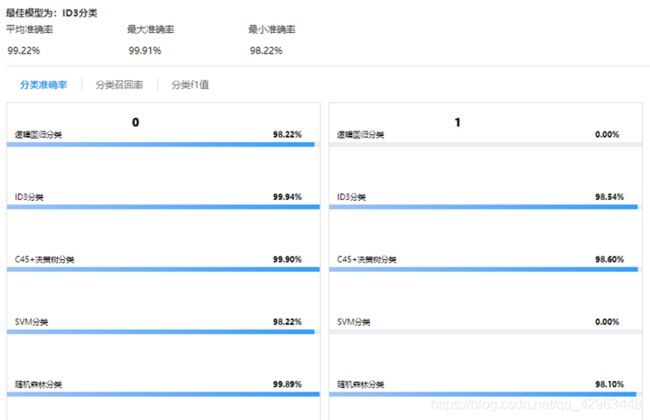
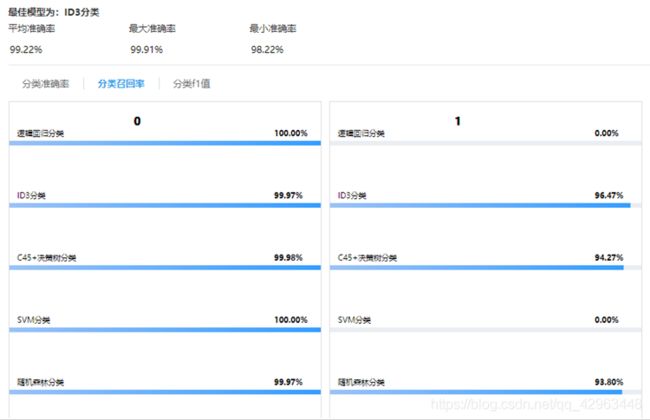
选择逻辑回归分类、随机森林分类、SVM分类、ID3分类、C45+决策树分类五种分类算法进行模型训练,通过验证数据集对训练好的模型进行评估。
模型运行后,在洞察页面重点关注模型评价“召回率”与“精度”,召回率高意味着通过模型,用户可以识别更多的可疑单号,而精度高则意味识别的可疑单号是欺诈行为的可能性更高。可以看到,在“召回率”与“精度”两个评价中,最佳模型选项均为ID3分类。
以上就是利用TempoAI建立医保反欺诈模型的整个流程。
医保反欺诈模型价值
医院可以通过识别医保欺诈行为的支付订单,发现风险后延迟支付,并通知人工进行二次核验,降低因为核算报销时发现不合理报销单拒付的风险,为医院年底医保报销结算的金额数量提供保障。
医保中心或地方财政部门可以在月度或年度医保核算时候通过模型识别风险订单,自动合计风险订单涉及金额并输出风险订单,为工作人员工作提供便捷的同时,为地方财政的医保资金盘子减压。
商业用户,例如各类保险公司与金融机构可以利用医保反欺诈行为识别模型来识别风险订单,为企业降低资金风险与人力成本。
结语
医保基金是整个社会民生基础之一,是每一个参保人的救命钱。守住医保基金的安全,就是守住社会底线。在当前新冠疫情仍在蔓延的特殊时期,为医保基金保驾护航有着尤为重要的意义。
正常需要几周的建模工作量,通过TempoAI在几小时内就可以快速构建出“医保反欺诈行为模型”,利用大数据、机器学习自动识别出欺诈行为,为工作人员提供判断依据,减少因欺诈产生的基金流失。
当然,随着医保欺诈行为越来越隐匿、手段越来越多样,反欺诈模型构建的复杂程度也越来越高。不过,随着大数据、人工智能等技术手段不断深入应用,相信百姓的救命钱袋也会越来越安全,社会医疗保险的根基也会越来越稳固。
社会医疗保险作为我国解决民生防治疾病问题推出的基础保险制度,医保基金被形象地称为老百姓的“保命钱”。谈判代表在谈判桌上一分一厘的“较真”,就是为了老百姓守住这份“保命前”。然而,有一部分人为了自己的利益,在报销规则上钻空子,利用伪造发票、重复就诊、重复开药、冒名就医、支付非医保药费或诊疗项目等各种方式骗取医保基金,导致医保基金大量流失。