信息增益的介绍
在前面的两篇文章中我们介绍了信息熵和条件熵。
信息熵代表的是随机变量的复杂度(不确定度)。
条件熵代表的是在某一个条件下,随机变量的复杂度(不确定度)。
现在信息增益=信息熵-条件熵。
换句话说,信息增益代表了在一个条件下,信息复杂度减少的程度。
在决策树算法中的关键问题时特征的选择,当有多个特征的时候,我们选择哪个特征来进行分类呢?或者是按照什么标准来选择特征呢?
这个问题我们利用信息增益的概念来解决,如果选择某一个特征,其信息增益最大(信息复杂度减少的程度最大),那么我么就选择这个特征开进行划分类。
下面举一个例子;
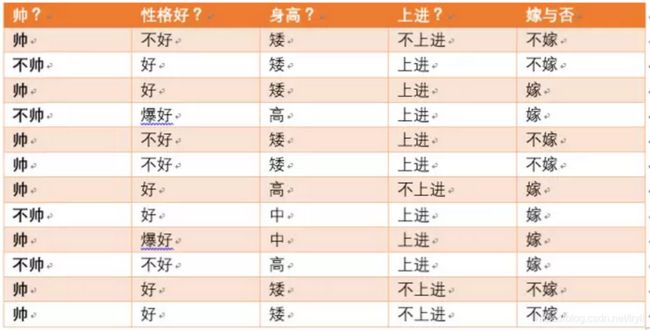
可以求得随机变量X(嫁与不嫁)的信息熵为:
嫁的个数为6个,占1/2,那么信息熵为-1/2log1/2-1/2log1/2 = -log1/2=0.301
现在假如我知道了一个男生的身高信息。
身高有三个可能的取值{矮,中,高}
矮包括{1,2,3,5,6,11,12},嫁的个数为1个,不嫁的个数为6个
中包括{8,9} ,嫁的个数为2个,不嫁的个数为0个
高包括{4,7,10},嫁的个数为3个,不嫁的个数为0个
先来回忆一下条件熵的公式为:
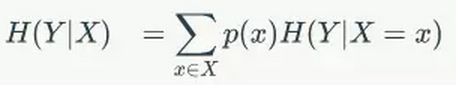
我们先求出公式对应的: 在对应身高的时候嫁或者不嫁的条件熵。
H(Y|X = 矮) = -1/7log1/7-6/7log6/7=0.178
H(Y|X=中) = -1log1-0 = 0
H(Y|X=高) = -1log1-0=0
p(X = 矮) = 7/12,p(X =中) = 2/12,p(X=高) = 3/12
则可以得出条件熵为:
7/12*0.178+2/12*0+3/12*0 = 0.103
那么我们知道信息熵与条件熵相减就是我们的信息增益,为
0.301-0.103=0.198
所以我们可以得出我们在知道了身高这个信息之后,信息增益是0.198
我们可以知道,本来如果我对一个男生什么都不知道的话,作为他的女朋友决定是否嫁给他的不确定性有0.301这么大。
当我们知道男朋友的身高信息后,不确定度减少了0.198,不确定度只有0.103这么大了,(如果不确定是0就最好了,我肯定嫁给他,因为他好的没有悬念,哈哈).也就是说,身高这个特征对于我们广大女生同学来说,决定嫁不嫁给自己的男朋友是很重要的。
至少我们知道了身高特征后,我们原来没有底的心里(0.301)已经明朗一半多了,减少0.198了(大于原来的一半了)。
那么这就类似于非诚勿扰节目里面的桥段了,请问女嘉宾,你只能知道男生的一个特征。请问你想知道哪个特征。
假如其它特征我也全算了,信息增益是身高这个特征最大。那么我就可以说,孟非哥哥,我想知道男嘉宾的一个特征是身高特征。因为它在这些特征中,对于我挑夫君是最重要的,信息增益是最大的,知道了这个特征,嫁与不嫁的不确定度减少的是最多的。