机器学习-降维算法(SVD和PCA)
降维算法主要分为线性降维和非线性降维。
1奇异值分解(SVD)
SVD 还可以用于推荐系统以及自然语言处理等领域,
矩阵的特征分解,矩阵A和特征值,特征向量之间的关系如下:
![]()
将A 矩阵做特征分解,特征向量Q是一组正交向量,具体表达式如下:
![]()
在这里因为Q 中n个特征向量为标准正交基,满足![]() ,也就是说Q 为酉矩阵。
,也就是说Q 为酉矩阵。
矩阵的特征值分解的局限性比较大,要求矩阵A 必须是方阵,那么一般的矩阵该如何分解呢?
奇异值分解可以处理这些一般性的矩阵,假设现在矩阵A 是一个m*n 的矩阵,我们可以将它的奇异值分解下面的形式。
![]()
这里的U是m*m 的矩阵,![]() 是m*n 的矩阵(除对角线上的值,其余的值全为0) V 是n*n 的矩阵,这里U和V 都是酉矩阵,也就满足
是m*n 的矩阵(除对角线上的值,其余的值全为0) V 是n*n 的矩阵,这里U和V 都是酉矩阵,也就满足![]() 。I 为单位矩阵。
。I 为单位矩阵。
2 主成分分析(PCA)
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间。
首先假设在低维空间中存在这样一个超平面,将数据从高维映射到该超平面上会使得样本之间的方差最大,假定对样本做中心化处理,也就是使得样本的均值为0,则所有样本的方差和可以表示为
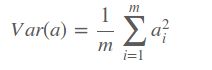
因此我们只要找到一组基,使得样本投影到每个基的方差最大,但是存在一个问题,因为在寻找每个基时都是满足方差最大,这可能会导致后面的基和前面的基重合,这样就没有意义。因此单纯的选择方差最大的方向显然是不合适的,我们引入一个约束条件,在寻找这样一组正价基时,我们不仅要使得映射后的方差最大,还要使得各特征之间的协方差为0,(协方差表示特征之间的相关性,使得特征都线性无关)。协方差表示如下:
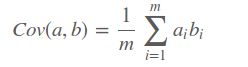
有没有同时表达方差和协方差的东西,协方差矩阵就可以,协方差矩阵是对称矩阵,矩阵的对角线上方差,其余值是协方差。具体表示如下:
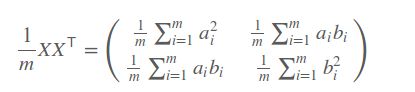
那么只要将协方差矩阵进行对角化,对角化后的矩阵除了对角线上的值,其余的值都为0.
设原始数据矩阵X对应的协方差矩阵为C,而P 是一组基按行组成的矩阵,设Y=PX,则Y对P 做基变换后的数据,设Y的协方差矩阵为D,推导一下D与C的关系,
![]()
优化目标变成了寻找一个矩阵P,满足是正交基矩阵,并且对角元素按照从大到小一次排列,那么P的前K 行就是要寻找的基,那么P的前K 行就是要寻找的基,用P 的前K 行组成的矩阵乘以X 就使得X 从N 维降到了K 维并满足上述优化条件。
因此现在我们只需要对协方差矩阵C 做对角化就好了。而且由于C 是实对称矩阵,因此原始矩阵X 是n*m,其中n是特征数,m 是样本数,这就是整个PCA 的简单理解流程。
实际上在数据量很大时,求协方差矩阵,然后在进行特征分解是一个很慢的过程,因此在PCA 背后的实现也是借助奇异值分解来做的,在这里我们只要求得奇异值分解中左奇异向量或右奇异向量中的一个(具体求哪个是根据你的X 向量的书写方式的,行数是样本数还是特征数,总之左奇异向量是用来压缩行数,右奇异向量是用来压缩列数,而我们的目的是要压缩特征数)
在我们的PCA转换中是一个线性转换,因此也被称为线性降维,但有时数据不是线性的,无法用线性降维获得好的结果,那么这里就引入了我们的核PCA方法来处理这些问题,具体表达式如下:

只需要在求协方差矩阵时,将数据先映射到高维(根据低维不可分的数据在高维必定可分的原理) ,然后再对这高维的数据进行PCA 降维处理。为了减少计算量,像SVM 那样用核函数来处理求内积的问题,这类方法就是核主成分分析方法(KPCA),KOCA 由于要做核运算,因此计算量比PCA 大很大。
ref:https://www.cnblogs.com/jiangxinyang/p/9291741.html
3 PCA 从特征分解的角度来理解
PCA 的主要思想是将n 维特征映射到k 维上,这个k 维是全新的正交特征也被称为主成分,是在原有n 维特征的基础上重新构造出来的k 维特征
PCA 构建k 维空间的具体过程:
PCA 从原始n 维空间中顺序地找一组相互正交的坐标轴,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2 个轴正交的平面中方差最大的。以此类推可以得到n个这样的坐标轴,通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k 个坐标轴中,后面的坐标轴所含的方差几乎为0,于是可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的正交坐标轴
3.1 为什么正交?
使得数据的损失最小,另外特征值的特征向量是正交的。
3.2 利用特征值分解计算PCA 的步骤:
首先将数据中每个特征的值去中心化,即减去该特征的均值,得到去中心化的X。
然后计算协方差矩阵
用特征值分解方法求上面协方差矩阵的特征值与特征向量,因为协方差矩阵是一个方阵,这里就是用线性代数中其次线性方程组的特征值的方法。
对特征值从大到小排序,选择其中最大的k 个,然后将其对应的k 个特征向量分别作为列向量组成特征向量特征P。将数据转换到k 个特征向量构建的新空间中,Y=XP。
如果我们通过特征值分解协方差矩阵,那么我们只能得到一个方向的PCA降维,这个方向就对数据矩阵X从列方向上压缩降维。
ref:https://www.zgcr1991.com/2019/03/09/zhu-cheng-fen-fen-xi-pca-jiang-wei-yuan-li-te-zheng-zhi-fen-jie-yu-svd-fen-jie/