【论文阅读笔记】(2017 CVPR)See, Hear, and Read: Deep Aligned Representations
See, Hear, and Read: Deep Aligned Representations
(2017 CVPR)
Yusuf Aytar, Carl Vondrick, Antonio Torralba
Notes
Contributions
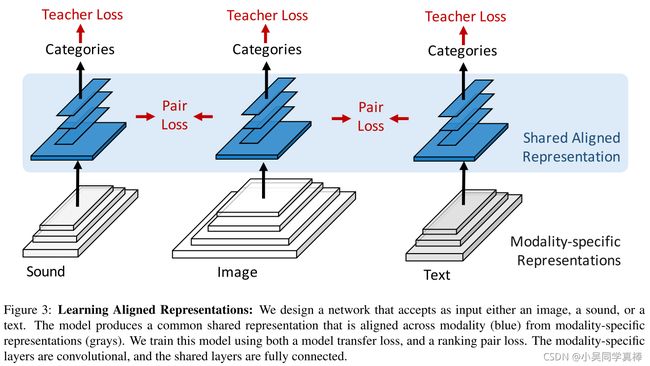
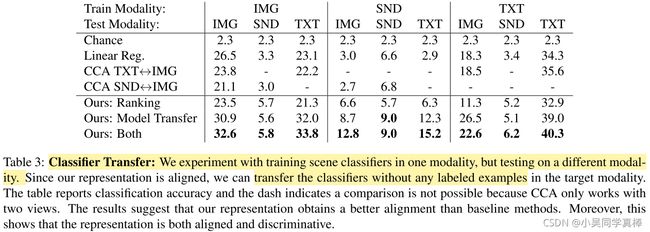
In this paper, we learn rich deep representations that are aligned across the three major natural modalities: vision, sound, and language. We present a deep convolutional network that accepts as input either a sound, a sentence, or an image, and produces a representation shared across modalities. We capitalize on large amounts of in-the-wild data to learn this aligned representation across modalities. We develop two approaches that learn high-level representations that can be linked across modalities. Firstly, we use an unsupervised method that leverages the natural synchronization between modalities to learn an alignment. Secondly, we design an approach to transfer discriminative visual models into other modalities.
Our experiments and visualizations show that a representation automatically emerges that detects high-level concepts independent of the modality. Figure
Method
Sound. We download videos from videos on Flickr and extract their sounds. We downloaded over 750, 000 videos from Flickr, which provides over a year (377 days) of continuous audio, as well as their corresponding video frames.
The only pre-processing we do on the sound is to extract the spectrogram from the video files and subtract the mean. We extract spectrograms for approximately five seconds of audio, and keep track of the video frames for both training and evaluation. We use 85% of the sound files for training, and the rest for evaluation.
The input spectrogram is a 500 × 257 signal, which can be interpreted as 257 channels over 500 time steps.
Language. We combine two of the largest image description datasets available: COCO, which contains 400, 000 sentences and 80, 000 images, and Visual Genome, which contains 4, 200, 000 descriptions and 100, 000 images. The concatenation of these datasets results in a very large set of images and their natural language descriptions, which cover various real-world concepts. We pre-process the sentences by removing English stop words, and embed- ding each word with word2vec.
Images. We use the frames from our sound dataset and the images from our language datasets. In total, we have nearly a million images which are synchronized with either sound or text (but not both). The only pre-processing we do on the images is subtracting the channel-wise mean RGB value. We use the same train/test splits as their paired sounds/descriptions.
Alignment by Model Transfer. We take advantage of discriminative visual models to teach a student model to have an aligned representation. Let ![]() be a teacher model that estimates class probabilities for a particular modality. For example,
be a teacher model that estimates class probabilities for a particular modality. For example, ![]() could be any image classification model, such as AlexNet. Since the modalities are synchronized, we can train
could be any image classification model, such as AlexNet. Since the modalities are synchronized, we can train ![]() to predict the class probabilities from the teacher model
to predict the class probabilities from the teacher model ![]() in another modality. We use the KL-divergence as a loss:
in another modality. We use the KL-divergence as a loss:
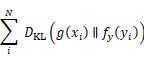
where ![]() . This objective by itself will enable alignment to emerge at the level of categories predicted by g. However, the internal representations of f would not be aligned since each student model is disjoint. To enable an alignment to emerge in the internal representation, we therefore constrain the upper layers of the network to have shared parameters across modalities.
. This objective by itself will enable alignment to emerge at the level of categories predicted by g. However, the internal representations of f would not be aligned since each student model is disjoint. To enable an alignment to emerge in the internal representation, we therefore constrain the upper layers of the network to have shared parameters across modalities.
Specifically, We train student models for sound, vision, and text to predict class probabilities from a teacher ImageNet model. We constrain the upper weights to be shared in the student models.
Alignment by Ranking. We additionally employ a ranking loss function to obtain both aligned and discriminative representations:

where ∆ is a margin hyper-parameter, ψ is a similarity function, and j iterates over negative examples. This loss seeks to push paired examples close together in representation space, and mismatched pairs further apart, up to some margin ∆. We use cosine similarity in representation space:
![]()
Specifically, we apply the ranking loss for alignment between vision → text, text → vision, vision → sound, and sound → vision on the last three hidden activations of the network.
Learning. To train the network, we use the model transfer loss in Equation 1 and the ranking loss in Equation 2 on different layers in the network. For example, we can put the model transfer loss on the output layer of the network, and the ranking loss on all shared layers in the network. The final objective becomes a sum of these losses.
Results
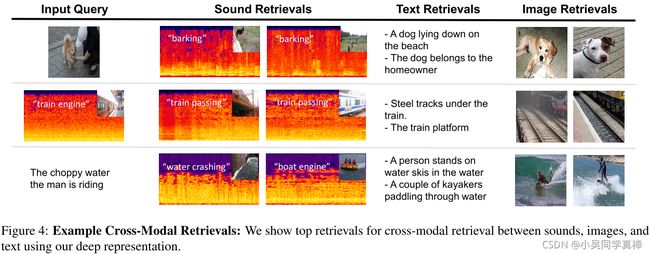
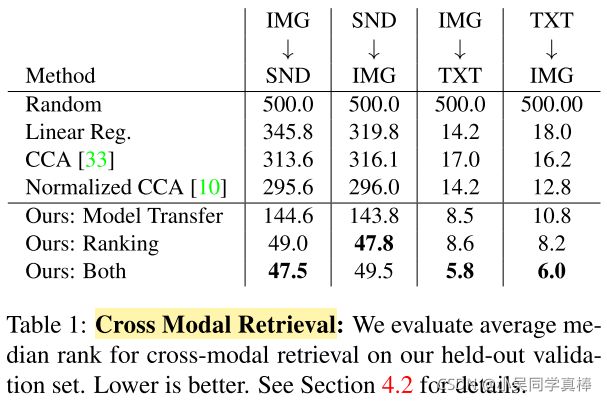

To better understand what our model has learned, we visualize the hidden units in the shared layers of our network, similar to [44]. Using our validation set, we find which inputs activate a unit in the last hidden layer the most, for each modality. We visualize the highest scoring inputs for several hidden units in Figure 5. We observe two properties. Firstly, although we do not supervise semantics on the hidden layers, many units automatically emerge that detect high-level concepts. Secondly, many of these units seem to detect objects independently of the modality, suggesting the representation is learning an alignment at the object level.