MPI Reduce and Allreduce
以下内容翻译自:MPI Reduce and Allreduce
在上一课中,我们介绍了使用MPI_Scatter和MPI_Gather执行MPI并行排序计算的应用示例。我们将通过MPI_Reduce和MPI_Allreduce进一步扩展集合通信例程。
注——本网站的所有代码均位于GitHub上。本教程的代码位于tutorials/mpi-reduce-and-allreduce/code下。
规约简介
Reduce是函数式编程的经典概念。数据规约涉及通过函数将一组数字缩减为一个较小的集合。例如,假设我们有一个数字列表[1,2,3,4,5]。用sum函数缩减这个数字列表将产生sum([1,2,3,4,5])= 15。同样,乘法规约将产生乘法([1, 2, 3, 4, 5]) = 120。
正如您可能想象的那样,将规约函数应用于一组分布式数字可能非常麻烦。除此之外,很难编制非交换规约,即必须按照设定的顺序进行规约。幸运的是,MPI有一个方便的MPI_Reduce函数,它可以处理程序员在并行应用程序中需要做的几乎所有常见的规约。
MPI_Reduce
与MPI_Gather类似,MPI_Reduce在每个进程上接收一组输入元素,并将一组输出元素返回到根进程。输出元素包含规约的结果。 MPI_Reduce的原型如下所示:
MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
send_data参数是一组每个进程准备规约的数据,其类型为datatype。 recv_data只与具有根rank的进程相关。recv_data数组包含规约的结果并且其大小为sizeof(datatype) * count。op参数是对数据应用的操作。MPI包含一组可以使用的通用约简操作。虽然可以定义自定义规约操作,但这超出了本课的范围。MPI定义的规约操作包括:
MPI_MAX——返回最大元素。MPI_MIN——返回最小元素。MPI_SUM——元素求和。MPI_PROD——将所有元素相乘。MPI_LAND——执行元素逻辑与。MPI_LOR——执行元素逻辑或。MPI_BAND——对元素的位进行按位与。MPI_BOR——对元素的位进行按位或。MPI_MAXLOC——返回最大值及对应的进程rank。MPI_MINLOC——返回最小值及对应的进程rank。
下面是MPI_Reduce通信模式的图示。
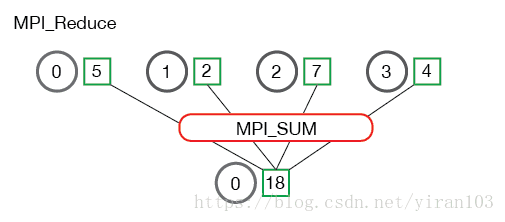
在上面,每个进程都包含一个整数。根进程0调用MPI_Reduce以并使用MPI_SUM作为缩减操作。将这四个数字加起来并存储在根进程中。
查看当进程包含多个元素时会发生什么对我们的理解非常有帮助。下图展示了每个进程中多个数字的规约。
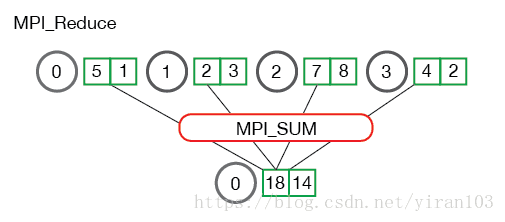
上面的插图中每个进程都有两个元素。由此产生的求和发生在每个元素的基础上。 换句话说,不是将所有数组中的所有元素合并到一个元素中,而是将来自每个数组的第i个元素合并到进程0的结果数组中的第i个元素。
现在您已经了解了MPI_Reduce的概念,我们可以进入一些代码示例。
用MPI_Reduce计算数字的平均值
在上一课中,我向您展示了如何使用MPI_Scatter和MPI_Gather来计算平均值。 使用MPI_Reduce可以简化上一课的代码。以下是本课示例代码中reduce_avg.c的摘录。
float *rand_nums = NULL;
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Print the random numbers on each process
printf("Local sum for process %d - %f, avg = %f\n",
world_rank, local_sum, local_sum / num_elements_per_proc);
// Reduce all of the local sums into the global sum
float global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// Print the result
if (world_rank == 0) {
printf("Total sum = %f, avg = %f\n", global_sum,
global_sum / (world_size * num_elements_per_proc));
}
在上面的代码中,每个进程创建随机数并进行local_sum计算。然后使用MPI_SUM将local_sum规约到根进程。全局平均值是global_sum / (world_size * num_elements_per_proc)。如果您从repo的tutorials目录运行reduce_avg程序,则输出应与此类似。
>>> cd tutorials
>>> ./run.py reduce_avg
mpirun -n 4 ./reduce_avg 100
Local sum for process 0 - 51.385098, avg = 0.513851
Local sum for process 1 - 51.842468, avg = 0.518425
Local sum for process 2 - 49.684948, avg = 0.496849
Local sum for process 3 - 47.527420, avg = 0.475274
Total sum = 200.439941, avg = 0.501100
现在是时候继续讨论``MPI_Reduce的兄弟——MPI_Allreduce`了。
MPI_Allreduce
许多并行应用程序需要所有进程访问规约的结果,而不仅是根进程。与MPI_Allgather对MPI_Gather的补充类似,MPI_Allreduce进行规约并将结果分发给所有进程。函数原型如下:
MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
正如您可能已经注意到的,MPI_Allreduce与MPI_Reduce相同,不同之处在于它不需要根进程ID(因为结果分发到所有进程)。以下说明了MPI_Allreduce的通信模式:
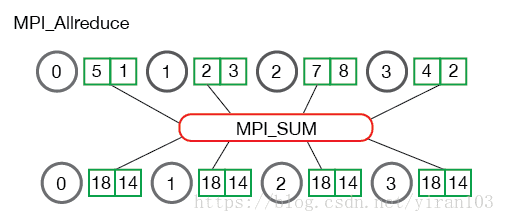
MPI_Allreduce相当于MPI_Reduce后跟MPI_Bcast。很简单,对吧?
用MPI_Allreduce计算标准差
许多计算问题需要多次规约才能解决。该类问题的一个例子是找到分布的一组数字的标准差。也许有人已经忘记了,标准差是衡量数字与他们平均数之间的分散程度。较低的标准偏差意味着数字间更接近,反之亦然。
要找到标准偏差,首先必须计算所有数字的平均值。在计算平均值之后,计算与平均值的平方差的和。平方差的和的平方根是最终结果。鉴于问题描述,我们知道至少会有两个所有数的和,转化为两个规约。课程代码中的reduce_stddev.c节选显示了MPI中的实现方法。
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Reduce all of the local sums into the global sum in order to
// calculate the mean
float global_sum;
MPI_Allreduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM,
MPI_COMM_WORLD);
float mean = global_sum / (num_elements_per_proc * world_size);
// Compute the local sum of the squared differences from the mean
float local_sq_diff = 0;
for (i = 0; i < num_elements_per_proc; i++) {
local_sq_diff += (rand_nums[i] - mean) * (rand_nums[i] - mean);
}
// Reduce the global sum of the squared differences to the root
// process and print off the answer
float global_sq_diff;
MPI_Reduce(&local_sq_diff, &global_sq_diff, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// The standard deviation is the square root of the mean of the
// squared differences.
if (world_rank == 0) {
float stddev = sqrt(global_sq_diff /
(num_elements_per_proc * world_size));
printf("Mean - %f, Standard deviation = %f\n", mean, stddev);
}
在上面的代码中,每个进程计算元素的local_sum并使用MPI_Allreduce对它们进行求和。每个进程都获得全局和之后,计算平均值以便计算local_sq_diff。一旦计算出所有局部平方差,就可以使用MPI_Reduce找到global_sq_diff。然后,根进程可以通过取全局平方差的平均值的平方根来计算标准差。
使用运行脚本运行示例代码会生成如下所示的输出:
>>> ./run.py reduce_stddev
mpirun -n 4 ./reduce_stddev 100
Mean - 0.501100, Standard deviation = 0.301126
接下来
现在您已经熟悉了所有常见集合——MPI_Bcast、MPI_Scatter、MPI_Gather和MPI_Reduce,我们可以利用它们构建复杂的并行应用程序。在下一课中,我们将开始MPI组和通信者。
对于所有课程,请参阅MPI教程章节。
想贡献?
这个网站完全托管在 GitHub上。本网站不再由原作者(Wes Kendall)积极贡献,但它放在GitHub上,希望其他人可以编写高质量的MPI教程。点击这里获取更多关于如何贡献的信息。