分享 | 物体检测和数据集
因为最近学习任务比较紧(但也不妨碍元旦摆烂三天),所以中间有几个实战Kaggle比赛就跳过了,等以后有时间再回头来看看。物体检测和数据集这一节花了有一天的时间,一直有一个bug困扰,后来改了代码把box画到了图上,途中还是挺崩溃的,总的来说这一课收获还挺大的。
物体检测
在前⾯的⼀些章节中,主要学习了诸多⽤于图像分类的模型。在图像分类任务⾥,我们假设图像⾥只有⼀个主体⽬标,并关注如何识别该⽬标的类别。然⽽,很多时候图像⾥有多个我们感兴趣的⽬标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉⾥,我们将这类任务称为⽬标检测(object detection)或物体检测。
说起来,大学里面第一个接触的深度学习-计算机视觉相关的内容应该就是目标检测了(YOLO),也自己训练过,读过论文,但对于目标检测的了解还是少之又少。
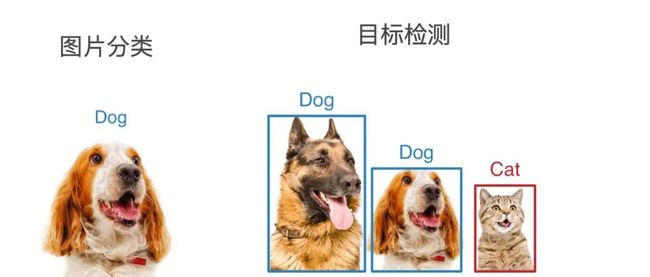
首先加载本节将使⽤的示例图像。可以看到左边是⼀只狗,右边是⼀只猫。它们是这张图像⾥的两个主要目标。
%matplotlib inline
from PIL import Image
from IPython import display
from matplotlib import pyplot as plt
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
def use_svg_display():
"""Use svg format to display plot in jupyter"""
display.set_matplotlib_formats('svg')
set_figsize()
img = Image.open('/Users/lihao/Desktop/dogcat.jpg')
plt.imshow(img); # 加分号只显示图
示例图像
边缘框的实现
在目标检测里,我们通常使⽤边界框(bounding box)来描述⽬标位置。边界框是⼀个矩形框,可以由矩形左上⻆的x和y轴坐标与右下⻆的x和y轴坐标确定。
我们根据上⾯的图的坐标信息来定义图中狗和猫的边界框。图中的坐标原点在图像的左上⻆,原点往右和往下分别为x轴和y轴的正方向。
dog_bbox, cat_bbox = [60, 45, 378, 516], [400, 112, 655, 493]我们可以在图中将边界框画出来,以检查其是否准确。画之前,我们定义⼀个辅助函数 bbox_to_rect 。它将边界框表示成matplotlib的边界框格式。(plt.Rectangle要用到matplotlib的边界框格式)
def bbox_to_rect(bbox, color):
# 将边界框(左上x, 左上y, 右下x, 右下y)格式转换成matplotlib格式:((左上x, 左上y), 宽, 高)
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)这里加一个关于fig和axes的说明(figure/fig 空白画布;ax单个坐标系 / axes 复数坐标系;axis 坐标轴; subplot是ax+ 对应的那部分fig)

将边界框加载在图像上,可以看到⽬标的主要轮廓基本在框内(这边一张图只有一个坐标系ax)
fig = plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));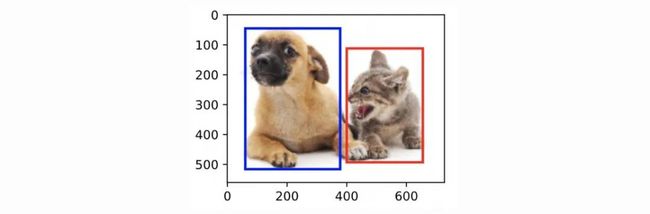
数据集
为了快速测试目标检测模型,‘我们’收集并标记了一个小型数据集。首先,‘我们’拍摄了一组香蕉的照片,并生成了1000张不同角度和大小的香蕉图像。然后,‘我们’在一些背景图片的随机位置上放一张香蕉的图像。最后,在图片上为这些香蕉标记了边界框。
3.1 下载数据集
-
包含所有图像和CSV标签文件的香蕉检测数据集可以直接从互联网下载 ,复制这个链接:d2l-data.s3-accelerate.amazonaws.com
-
下载完成后我手动进行解压,目录结构如下所示:
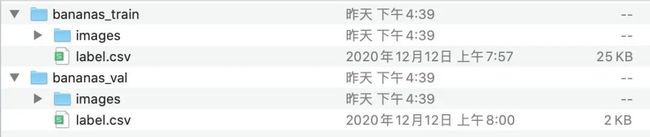
banana-detection目录结构

.csv文件内部
3.2 读取数据集
由于现在我们这个数据集比较小,所以就直接全部一下子读到了cpu内存里面;在实际操作中,会有一些规范的表示方式:会在文章的最后举个例子。
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
import matplotlib
import matplotlib.pyplot as plt
from PIL import Image
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = '/Users/lihao/Downloads/banana-detection'
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val', 'label.csv') # 拿出csv
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name') #以‘img_name'这一列作为索引
images, targets = [], []
for img_name, target in csv_data.iterrows(): #.iterrows()是遍历的意思
images.append(
torchvision.io.read_image( # 将图片都读到内存中
os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val',
'images', f'{img_name}')))
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256 # 返回所有读出来的图片和标号对应的tensor-
set_index('img_name'):是以‘img_name'这一列作为索引的意思;set_index()更多具体的用法参考:侦探L:如何在pandas中使用set_index( )与reset_index( )设置索引
-
iterrows():是遍历的意思
-
for img_name, target in csv_data.iterrows():使得img_name属于images这一块,剩下的所有列属于另一块
-
torch.tensor(targets).unsqueeze(1):这边需要添加一个维度,不加的话就是torch.Size([batch_size, 5]),加了变为torch.Size([batch_size, 1, 5]);不加的话后面就会报错:slice()函数不能作用于0维的数据
这边可以看一下读出来的images和labels到底是什么样
print(images),整个images的类型为list

print(targets),整个targets的类型为list;每个target包含(类别,左上角x,左上角y,右下角x,右下角y)

创建一个自定义Dataset实例来加载香蕉检测数据集
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集实例"""
# 将所有的数据读进来
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read' + str(len(self.features)) + (f'training examples' if is_train else f'validation examples'))
# 将第i个图片转为float返回回去,将第i个物体的label返回
#看了一下以往用Datalodar的时候,image_tensor 里面的数字都是浮点数,所以这边估计也需要转换一下
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
# 一个数据集的长度有多长
def __len__(self):
return len(self.features)最后,定义load_data_bananas函数,来为训练集和测试集返回两个数据加载器实例。
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True), batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False), batch_size)
return train_iter, val_iter读取一个小批量,并打印其中的图像和标签的形状。
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape # batch[0]图像;batch[1]标签
3.3 演示
先上一些需要用到的函数
def show_images(imgs, num_rows, num_cols, scale=2):
figsize = (num_cols * scale, num_rows * scale)
_,axes = plt.subplots(num_rows, num_cols, figsize=figsize) #创建画布
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j]) #把图像画上去
#下面是不需要显示坐标轴的意思
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axes
def bbox_to_rect(bbox, color):
# 将边界框(左上x, 左上y, 右下x, 右下y)格式转换成matplotlib格式:((左上x, 左上y), 宽, 高)
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
def show_bboxes(axes, bboxes, labels=None, colors=None):
for i, bbox in enumerate(bboxes):
rect = bbox_to_rect(bbox.detach().cpu().numpy(),'w')
axes.add_patch(rect)下面到了踩坑的地方,原来的代码是:
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
show_bboxes(ax, [label[0][1:5] * edge_size])这样会一直报错AttributeError: 'numpy.ndarray' object has no attribute 'add_patch',print了一下ax,发现它还是numpy.ndarray类型,并不是

我修改了一下show_bboxes,把ax里面的dax再一个个拿出来(此时dax是
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
# permute的作用就是将这几个维度换一换,这里就是将维度为1的换到维度3,维度为2,3的往前来一个
axes = show_images(imgs, 2, 5, scale=2)
for dax,bbox in zip(axes[0],batch[1][0:5]): #for … in zip是并行遍历的意思
show_bboxes(dax, [bbox[0][1:5] * edge_size])
for dax,bbox in zip(axes[1],batch[1][5:10]):
show_bboxes(dax, [bbox[0][1:5] * edge_size])
这边补充一个数据集规范的表示方式
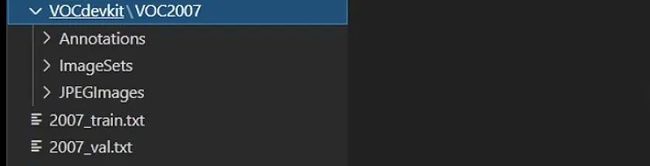
JPEGImages下面存放的是原图片文件;Annotations下面放的是.xml标签文件,如下图所示:

.xml标签文件
ImageSets里面存放.txt文件
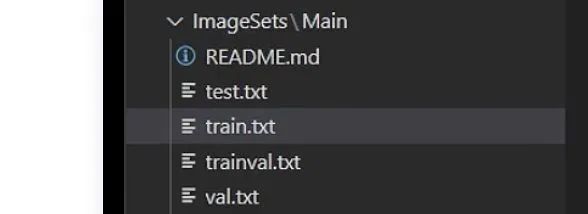
最初只有JPEGImages下面存放图片文件;Annotations下存放.xml标签文件;ImageSets下面是没有文件的,我们要通过voc_annotation.py文件去数据集划分的.txt文件,以及最后根目录下的2007_train.txt和2007_val.txt(路径+标签,和我们上面手写的简单版是一个意思,只不过上面我们一个图中只有一个目标,而实际中是多个目标)

2007_train.txt
参考文献
【1】关于matplotlib中的fig/axes/axis/subplot的区别_yyhhlancelot的博客-CSDN博客_fig,axes
【2】动手深度学习|目标检测数据集
【3】Pytorch 搭建自己的YoloX目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
作者:修仙
|关于深延科技|
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。