dicom格式文件 界定标识符的处理
说到底无非几个事情 :
1传输语法确定
2数据元素读取
3 7fe0,0010元素 也就是图像数据处理。
关于这整个过程已经不想多说了 在我的上上一篇博客里已经基本实现了。 当然还很有问题比如图像调窗就有bug 这个以后再说吧。众所周知dicom格式文件是由一个接一个连续的“数据元素”组成的。
这次我们只讲怎样去处理文件里一种特殊的数据元素:那就是VR为SQ类型的元素 还有delimited 也就是界定标识付 我们暂且把它归为一类。 为什么特殊呢?因为其他元素都很简单 ,根据传输语法:-> tag_有无显式VR_len_VF 这样的结构。 len是数据长度, VF是固定字节数的字节流数据。 而遇到SQ类型的数据元素就麻烦了 首先他的len是FFFFFFFF 就是无长度。然后是VF 他是一种“文件夹”结构 ,就是里面嵌套其他数据元素,可能嵌套一层 可能嵌套几层 处理是很棘手的问题。
说了这么多我们先来直观的看一下 找到我们上一篇文章《Dicom格式文件解析器》打开测试数据IM-0001-0002.dcm 看到tag数据里有很多类似这样的:
0040,0275SQ
0040,0275(SQ):00
--fffe,e000(**):
--0040,0007(LO):CT2 t阾e, face, sinus
----0040,0008(SQ):00
------fffe,e000(**):
------0008,0100(SH):CTTETE
------0008,0102(SH):XPLORE
------0008,0104(LO):CT2 T蔜E, FACE, SINUS
------fffe,e00d(**):
----fffe,e0dd(**):
----0040,0009(SH):A10011234815
----0040,1001(SH):A10011234814
--fffe,e00d(**):
fffe,e0dd(**):
事先已经知道VR是显式方式的explicit VR 字节序是little edition,这里只是测试 那么我们直接就在处理代码class的变量里写死了:
1 class Reader 2 { 3 4 WarpedStream.byteOrder bytOrder = WarpedStream.byteOrder.littleEdition; 5 bool ExplicitVR = true; 6 7 }
然后我们把组号=0002开头的元素都剔除了 然后把7fe0,0010 也就是图像数据去掉了。这里我们已经有根据上述方式从IM-0001-0002.dcm分离出来的数据元素内容IM-0001-0002.bin 我们来看下IM-0001-0002.bin的二进制流数据组织方式:

对应元素0040,0275看
通过观察有如下规律,tag的VR类型如果等于SQ len=ffffffff 那么它必定以fffe,e0dd len=00000000结尾。 如果tag=fffe,e000 len=ffffffff 必定以fffe,e00d len=00000000 结尾 但是tag=fffe,e000 并不能称之为为节点下的元素。通过dicom标识我们知道 元素同一节点下只能出现一次,而tag=fffe,e000 可以出现多次。这称之为界定标识符 即Delimiter,并且他们是成对的, 有DelimiterStart 就有DelimiterEnd 就是通过这种一个包一个的嵌套方式实现了一个树状目录结构 。 简而言之我们要做的就是解析他。 但是在《Dicom格式文件解析器》里不是已经实现了么,他的关键代码 是这样做的:
1 if ((VR == "SQ" && Len == UInt32.MaxValue) || (tag == "fffe,e000" && Len == UInt32.MaxValue))// 遇到文件夹开始标签了 2 { 3 if (enDir == false) 4 { 5 enDir = true; 6 folderData.Remove(0, folderData.Length); 7 folderTag = tag; 8 } 9 else 10 { 11 leve++;//VF不赋值 12 } 13 } 14 else if ((tag == "fffe,e00d" && Len == UInt32.MinValue) || (tag == "fffe,e0dd" && Len == UInt32.MinValue))//文件夹结束标签 15 { 16 if (enDir == true) 17 { 18 enDir = false; 19 } 20 else 21 { 22 leve--; 23 } 24 } 25 else 26 VF = dicomFile.ReadBytes((int)Len); 27 28 string VFStr; 29 30 VFStr = getVF(VR, VF); 31 32 for (int i = 1; i <= leve; i++) 33 tag = "--" + tag; 34 //------------------------------------数据搜集代码 35 if ((VR == "SQ" && Len == UInt32.MaxValue) || (tag == "fffe,e000" && Len == UInt32.MaxValue) || leve > 0)//文件夹标签代码 36 { 37 folderData.AppendLine(tag + "(" + VR + "):" + VFStr); 38 } 39 else if (((tag == "fffe,e00d" && Len == UInt32.MinValue) || (tag == "fffe,e0dd" && Len == UInt32.MinValue)) && leve == 0)//文件夹结束标签 40 { 41 folderData.AppendLine(tag + "(" + VR + "):" + VFStr); 42 tags.Add(folderTag + "SQ", folderData.ToString()); 43 } 44 else 45 tags.Add(tag, "(" + VR + "):" + VFStr);
看得出基本逻辑就是 遇见DelimiterStart 则level++,遇见DelimiterEnd 则level-- 直至根节点VR=SQ的元素结束,把所有同一节点下的数据全都append到一个stringBuilder下。看得出来当时只是为了实现功能 代码比较简单 并没有用到递归 ,并且dataelement的“数据模型”也没有实现。
现在我们就用递归算法来重新实现这个解析过程:
首先应当把数据元素封装成一个结构体,为了他能够实现层级目录结构 ,通过观察windows文件系统的结构 那么它应该是这样的:一个目录下有很多项 有的是文件夹 有的是文件,如果是文件夹那么它下面可能又包括有文件,就是说如果是文件夹则递归 否则结束。
dataelement的struct代码:
1 struct DataElement 2 { 3 public uint _tag; 4 public WarpedStream.byteOrder bytOrder; 5 public bool explicitVR;//是显式VR的 否则隐式VR 6 public uint tag 7 { 8 get { return _tag; } 9 set 10 { 11 _tag = value; 12 VR = VRs.GetVR(value); 13 uint _len = VRs.getLen(VR); 14 if (_len != 0) 15 len = _len; 16 } 17 } 18 public ushort VR; 19 //虽然长度为uint 但要看情况隐式时都是4字节 显式时除ow那几个外都是2字节 20 //如果为ow 显示不但长度为4 在之前还要跳过2字节,除ow那几个之外不用跳过 21 public uint len; 22 public byte[] value; 23 public IList<DataElement> items; 24 public bool haveItems; 25 26 public string showValue() 27 { 28 if (haveItems) 29 return null; 30 31 if (value != null) 32 return Tags.VFdecoding(VR, value, bytOrder); 33 else 34 return null; 35 } 36 public void setValue(string valStr) 37 { 38 if (haveItems) 39 return; 40 41 if (len != 0) 42 value = Tags.VFencoding(VR, valStr, bytOrder, len); 43 else 44 { 45 value = Tags.VFencoding(VR, valStr, bytOrder); 46 if (VRs.IsStringValue(VR)) 47 len = (uint)value.Length; 48 } 49 } 50 51 }
haveItems 代表是否是Delimiter ,items则代表它里面的项。母项 跟子项之间用haveItems 和Delimiter 来产生联系 。为了实现解析我们先得做些前期处理 以供方便调用。就是itemHeader的读取 ,itemHeader指的是一个数据元素除VF部分的所有 详细请看《Dicom格式文件解析器》。上面第一段那句话 普通dataelement跟 “文件夹”dataelement的区别 ,前面部分一样的 主要区别于VF部分 所以我们才写了这个itemHeader读取的函数(潜意识的是说通过header去确定VF部分是否包含子元素)。
贴出代码:
1 public DataElement readItemHeader(WarpedStream pdv_stream) 2 { 3 //bool ExplicitVR = true; 4 //WarpedStream.byteOrder bytOrder = WarpedStream.byteOrder.littleEdition; 5 6 DataElement item_tmp = new DataElement(); 7 item_tmp.bytOrder = bytOrder; 8 9 #region tag 和len 处理部分 10 item_tmp.tag = pdv_stream.readTag(); 11 12 if (item_tmp.tag == 0xfffee000)//针对界定标识符的处理 delimited 13 { 14 item_tmp.len = 0xffffffff; 15 pdv_stream.skip(4); 16 } 17 else if (item_tmp.tag == 0xfffee00d || item_tmp.tag == 0xfffee0dd) 18 { 19 item_tmp.len = 0x00000000; 20 pdv_stream.skip(4); 21 } 22 else if (ExplicitVR)//显示VR 23 { 24 byte[] vrData = pdv_stream.readBytes(2); 25 Array.Reverse(vrData); 26 item_tmp.VR = BitConverter.ToUInt16(vrData, 0); 27 //ow情况 length=4字节 5个不是 OB OW OF UT SQ UN 外加NONE 28 if (item_tmp.VR == VRs.OB || item_tmp.VR == VRs.OW || item_tmp.VR == VRs.OF || 29 item_tmp.VR == VRs.UT || item_tmp.VR == VRs.SQ || item_tmp.VR == VRs.UN) 30 { 31 pdv_stream.skip(2); 32 item_tmp.len = pdv_stream.readUint(); 33 } 34 else 35 { //非ow情况 length=2字节 36 item_tmp.len = pdv_stream.readUshort(); 37 } 38 } 39 else//隐式VR 自己通过tag找 40 { 41 item_tmp.VR = VRs.GetVR(item_tmp.tag);//调用根据tag找寻vr的函数 42 if (item_tmp.tag == 0xfffee000) 43 item_tmp.len = 0xffffffff; 44 else if (item_tmp.tag == 0xfffee00d || item_tmp.tag == 0xfffee0dd) 45 item_tmp.len = 0x00000000; 46 else 47 item_tmp.len = pdv_stream.readUint(); 48 } 49 #endregion 50 return item_tmp; 51 }
没啥特殊的 就是读取数据 只要遵循dicom标准就行了 。看代码的时候留意下。如果不熟悉请看《Dicom格式文件解析器》一章。解析的递归算法代码实现, 说着挺简单的实际上还是比较复杂的 但是中心思想还是跟上面一样遇见DelimiterStart 则level++,遇见DelimiterEnd 则level--。
看上面那句话“主要区别与VF部分 ”,为什么呢 因为VF部分涉及到递归调用 把header跟VF部分区分开 ,如果VF类型是文件夹 则递归否则结束。遇见DelimiterStart 则陷入递归调用,遇见DelimiterEnd 则从递归调用中退出一级。
贴出代码:
1 public void readItem(ref DataElement item, WarpedStream pdv_stream) 2 { 3 //bool ExplicitVR = true; 4 //WarpedStream.byteOrder bytOrder = WarpedStream.byteOrder.littleEdition; 5 6 #region value 处理部分 7 //文件夹标签情况 8 if ((item.VR == VRs.SQ && item.len == UInt32.MaxValue) || (item.tag == 0xfffee000 && item.len == UInt32.MaxValue)) 9 { 10 item.haveItems = true; 11 item.items = new List<DataElement>(); 12 13 while (true) //读取所有item 直到根据文件夹结尾标识 不断的退出所有的递归循环; 14 { 15 16 DataElement item_tmp = readItemHeader(pdv_stream);//读取tag的头部 即 tag VR Len 17 if (item_tmp.tag == 0xfffee00d || item_tmp.tag == 0xfffee0dd) 18 { 19 //检查是否文件夹结尾标识的代码 如果遇到文件夹结尾标识 立即break 别忘了把读到的tag 字节偏移退回去; 20 //即从已经陷入的递归循环里退一级 21 pdv_stream.seek(-item_tmp.getHeaderLen(), SeekOrigin.Current); 22 break; 23 } 24 else if ((item_tmp.VR == VRs.SQ && item_tmp.len == UInt32.MaxValue) || (item_tmp.tag == 0xfffee000 && item_tmp.len == UInt32.MaxValue)) 25 { 26 //pdv_stream.seek(-item_tmp.getHeaderLen(), SeekOrigin.Current);//字节偏移退回去;貌似不用偏移 27 //文件夹标签起始标识 递归 28 //即往递归循环里陷入一级 29 readItem(ref item_tmp, pdv_stream); 30 item.items.Add(item_tmp);//items.add代码(文件夹元素) 31 } 32 else 33 { 34 //普通tag及数据读取代码 35 item_tmp.value = pdv_stream.readBytes((int)item_tmp.len); 36 item.items.Add(item_tmp);//items.add代码(普通元素) 37 } 38 } 39 40 //针对文件夹结束标签的处理 //读取文件夹结尾标签 以跟开始标签相呼应 41 if (item.VR == VRs.SQ && item.len == UInt32.MaxValue) 42 { 43 //0xfffee0dd len=00000000//(item_tmp.tag == 0xfffee0dd && item_tmp.len == UInt32.MinValue) 44 pdv_stream.skip(4 + 4); 45 } 46 else if (item.tag == 0xfffee000 && item.len == UInt32.MaxValue) 47 { 48 //0xfffee00d len=00000000 49 pdv_stream.skip(4 + 4); 50 } 51 }//普通元素情况 52 else 53 { 54 item.value = pdv_stream.readBytes((int)item.len); 55 } 56 #endregion 57 58 }
代码没什么好解释的 看就是了 有注释。 最后说下源文件里 VRs.cs 跟Tags.cs 是根据dicom标准编写的 。里面实现的是几千个tag跟VR的对应关系。 这当然不是我写的。 用的别人的成果,几千个啊你想想不把我整疯么。
大功告成 我们来调用试下结果:
1 public IDictionary<uint, DataElement> pdvDecoding() 2 { 3 4 //pdvBuffer.Seek(0, SeekOrigin.Begin);//把读取偏移点设置到开始处 5 6 FileStream fs = new FileStream("IM-0001-0002.bin", FileMode.Open); 7 WarpedStream ws = new WarpedStream(fs, bytOrder); 8 9 IDictionary<uint, DataElement> ds = new Dictionary<uint, DataElement>(); 10 //int indx = 0; 11 while (ws.getPostion() < fs.Length) 12 { 13 DataElement item = readItemHeader(ws); 14 //Console.WriteLine(Tags.ToHexString(item.tag)); 15 readItem(ref item, ws); 16 ds.Add(item.tag, item); 17 //indx++; 18 //if (indx >= 22) 19 // break; 20 21 showItem(item); 22 } 23 24 ws.close(); 25 return ds; 26 } 27 28 int level = 0; 29 public void showItem(DataElement element) 30 { 31 for (int i = 0; i < level; i++) 32 { 33 Console.Write("-"); 34 } 35 if (element.haveItems) 36 { 37 level++; 38 39 Console.WriteLine(Tags.ToHexString(element.tag)); 40 foreach (DataElement item in element.items) 41 { 42 showItem(item); 43 } 44 level--; 45 } 46 else 47 { 48 Console.WriteLine(Tags.ToHexString(element.tag)); 49 } 50 }
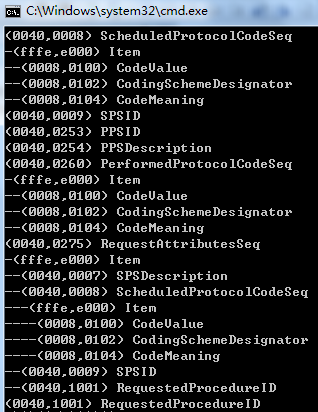
这种解析跟数据组织方式 更方便了dicom数据对象的处理 。我这讲讲当然很简单 看上去很容易的样子 ,因为我已经亲手一行代码一行代码的实现了。 代码很多请同学们 仔细阅读每一个细节 他们之间的调用关系及逻辑。很多地方我没讲到 为了限制篇幅其实有很多与重点部分无关的代码贴出来的时候我已经删除了,但是源码文件里有。
源码及测试数据下载猛击此处
做一个好的程序员是要有缜密的思维跟耐心的