bash shell学习-实践 (自己实现一些小工具)
The poor starve while the rich feast.
"穷人饥肠辘辘,富人大吃大喝"
一、简易单词管理程序
简介: 本程序主要用于记录和查询英文单词信息,可能没有什么实际用途,也可能代码中有一些不太简洁的实现,主要是因为编写本程序的目的是为了熟练一下shell script编程的基础知识
功能: ①单词查询; ②单个单词导入词库; ③从文件导入词库;④统计词库信息;
程序结构: 一个Bash shell程序 explain (解释), 一个词库文件: .word_lib.txt , 保存在用户家目录下的 .word_manager 目录中
文件内容: .word_lib.txt 是词库文件,保存所有单词信息, 每行一个单词, 包括: 原型, 中文意思。所有单词信息已经过排序去重处理;
程序执行流程: 解析命令选项-->根据解析结果执行对应的操作-->退出程序
程序介绍:
1 用法: explain [-afcb] [单词|文件名] [单词信息] 2 选项: 3 不带选项: 查询单词并打印出查询结果,结果格式: word 中文意思 4 -a : 将单词信息导入词库,后跟单词和单词信息 5 -f : 从文件导入词库,后跟文件名 6 -c : 统计词库中的单词总数 7 -b : 浏览词库的单词信息(通过more命令打开)
8 所有正确的命令格式: 9 explain word #查询word指定的单词 10 explain -c #打印出词库当前共有多少个单词 11 explain -b #浏览词库的单词信息 12 explain -a word wordinfo #添加单词信息至词库 13 explain -f filename #将文件导入词库,要求格式一致 14 15 说明:word可以为英文单词,也可以为中文,只要词库中某一行包含word,就会打印出该行,所以查询结果可能包含多行
16 退出码: 17 0 :程序执行成功 18 1 :没有输入选项和参数 19 2 :输入了未知的选项 20 3 :-a后面没有跟着单词和解释 21 4 :-f后面没有文件名或者是不存在的文件
源码如下:


1 #/bin/bash - 2 #=============================================================================== 3 # 4 # FILE: explain.sh 5 # 6 # USAGE: ./explain.sh 7 # 8 # DESCRIPTION: 简易单词管理程序 9 # 10 # OPTIONS: --- 11 # REQUIREMENTS: --- 12 # BUGS: --- 13 # NOTES: --- 14 # AUTHOR: Aut (yinjing), autyinjing@126.com 15 # ORGANIZATION: 16 # CREATED: 2015年06月29日 16:23 17 # REVISION: --- 18 #=============================================================================== 19 20 # 1 可执行文件的查找路径设置 21 PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin 22 export PATH 23 24 # 2 相关的全局变量声明和设置 25 home_path=~/.word_manager #相关文件的主目录 26 lib_path=$home_path/.word_lib.txt #词库文件的路径 27 28 # 3 相关目录和文件的设置 29 if [ ! -d "$home_path" ]; then 30 mkdir $home_path #~/.word_manager 31 touch $lib_path #~/.word_manager/.word_lib.txt 32 fi 33 34 # 4 相关函数实现 35 function query() #直接查询单词信息 36 { 37 ret=$(cat $lib_path | grep "$1") 38 if [ -z "$ret" ]; then 39 echo "$1 not be found!" 40 else 41 echo "$ret" 42 fi 43 } 44 45 function update_lib() #对词库进行排序去重,目前还没有想到更好的方法,只能利用临时文件 46 { 47 cat $lib_path | sort -fb | uniq > ~/.word_manager/._word_lib.txt 48 rm $lib_path 49 mv ~/.word_manager/._word_lib.txt $lib_path 50 } 51 52 function print_count() 53 { 54 ret=$(wc -l $lib_path | cut -d ' ' -f1 | grep '[[:digit:]]') 55 echo "当前词库共有$ret个单词" 56 } 57 58 function add_to_lib() #添加单词到词库 59 { 60 word=$1\ $2 #将新的单词信息保存为一整行 61 echo "$word" >> $lib_path #~/.word_manager/.word_lib.txt 62 update_lib 63 echo "成功将 $word 导入词库!" 64 print_count 65 } 66 67 function add_from_file() #通过文件导入词库 68 { 69 cat $1 >> $lib_path #~/.word_manager/.word_lib.txt 70 update_lib 71 echo "成功将 $1 内的单词导入词库!" 72 print_count 73 } 74 75 function browse_lib() 76 { 77 echo "" 78 more $lib_path 79 echo "" 80 print_count 81 } 82 83 function print_help() 84 { 85 echo "" 86 echo "用法: explain [选项] [单词|文件名] [单词信息]" 87 echo "" 88 echo "选项:" 89 echo " 不带选项: 查询单词并打印出查询结果" 90 echo " -a : 将单词信息导入词库,后跟单词和单词信息" 91 echo " -f : 从文件导入词库,后跟要导入的文件名" 92 echo " -c : 统计词库中的单词总数" 93 echo " -b : 浏览词库中单词信息" 94 echo " --help : 显示帮助信息" 95 echo "" 96 } 97 98 # 5 主程序部分 99 if [ "$#" -lt 1 ]; then #首先判断命令格式是否正确 100 print_help 101 exit 1 102 fi 103 104 opt=$(echo $* | cut -d ' ' -f1 | grep '^-') #解析选项 105 case $opt in 106 "") 107 query $1 108 ;; 109 "-a") 110 if [ "$#" -eq "3" ]; then 111 add_to_lib $2 $3 112 else 113 echo "正确格式:explain -a word wordinfo" 114 exit 3 115 fi 116 ;; 117 "-f") 118 if [ -f "$2" ]; then 119 add_from_file $2 120 else 121 echo "不存在的文件 $2" 122 exit 4 123 fi 124 ;; 125 "-c") 126 print_count 127 ;; 128 "-b") 129 browse_lib 130 ;; 131 "--help") 132 print_help 133 ;; 134 *) 135 echo "未知的选项,输入 explain --help 查看帮助信息" 136 exit 2 137 esac 138 139 exit 0
使用截图如下,笔者已增加了文件的可执行权限并复制到/usr/bin/,所以可以直接输入程序名来执行命令
空的词库:(不知道为什么图片和文字之间的间隔那么大,并没有空行~~)
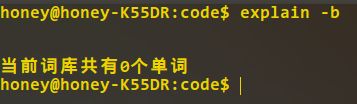
添加单个单词:
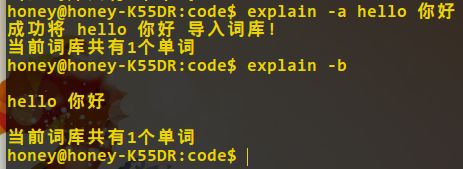
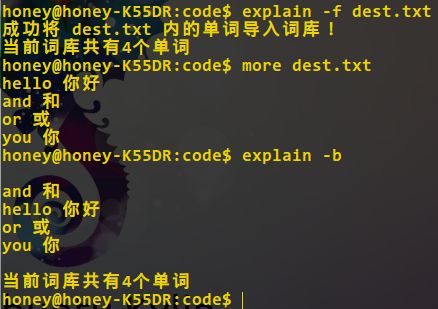
从文件导入词库:
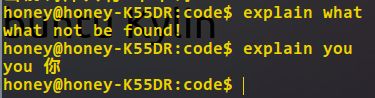
查询:
篇幅有限,错误的命令提示就不发图了
二、回文串检测程序
程序说明:本程序用于检测一个文件内的回文单词,并将所有回文单词按照每个一行的格式打印出来
1 用法:match_plalindrome filename 2 输出:按照单词长度递增的顺序打印出所有的回文单词(默认检测长度在3~20之间的单词) 3 核心思想:用正则表达式中的'(.)'匹配任意字符,再用反向引用 '...\2\1' 匹配前面的任意字符达到检测回文串的目的,详细内容参见下面源码 4 说明:程序默认将 空格、,、.、?、:、! 作为单词分隔符
程序源码:
1 #!/bin/bash - 2 #=============================================================================== 3 # 4 # FILE: match_plalindrome.sh 5 # 6 # USAGE: ./match_plalindrome.sh 7 # 8 # DESCRIPTION: 9 # 10 # OPTIONS: --- 11 # REQUIREMENTS: --- 12 # BUGS: --- 13 # NOTES: --- 14 # AUTHOR: Aut (yinjing), autyinjing@126.com 15 # ORGANIZATION: 16 # CREATED: 2015年06月30日 19:13 17 # REVISION: --- 18 #=============================================================================== 19 20 # 1 判断命令格式是否正确 21 if [ "$#" -ne 1 ]; 22 then 23 echo "Usage: $0 filename" 24 exit 1 25 fi 26 27 # 2 全局变量的声明和设置 28 filename=$1 #要查找的文件名 29 tmpfile=tmp.txt #临时文件的文件名 30 declare -i count #回文串的重复部分长度 31 32 # 3 由于原文件中的内容可能不是每行一个单词,所以这里要使用一个临时文件将原文件的信息转换为每行一个单词 33 cat $filename | tr '[ ,.?:!]' '\n' > $tmpfile #将所有的标点符号及空格替换为换行符 34 sed -i '/^$/d' $tmpfile #删除所有空行 35 36 # 4 默认查找长度为3到20的回文串 37 for ((len=3; len<=20; len++)) #循环查找各个长度的回文串 38 do 39 basepattern='/^\(.\)' #基础模式 40 count=$(( $len / 2 )) #计算重复部分的长度 41 42 for ((i=1; i<$count; i++)) #设置正则表达式 43 do 44 basepattern=$basepattern'\(.\)' 45 done 46 47 if [ $(( $len % 2 )) -ne 0 ]; #判断字符串长度是奇数还是偶数并设置对称轴 48 then 49 basepattern=$basepattern'.' 50 fi 51 52 for ((count; count>0; count--)) #设置反向引用 53 do 54 basepattern=$basepattern'\'"$count" 55 done 56 57 basepattern=$basepattern'$/p' #添加打印参数 58 59 sed -n "$basepattern" $tmpfile 60 done 61 62 # 5 删除临时文件 63 rm $tmpfile 64 65 exit 0
运行截图:

三、其他命令(持续更新...)
1、用awk实现head
1 $ awk 'NR <= 10' filename 2 说明:打印行号小于等于10的行
2、用awk实现tail
1 $ awk '{ buffer[NR % 10] = $0; } END { for (i=1;i<11;i++) { print buffer[i%10] } }' filename 2 说明:用数组保存文件的最后10行,然后打印
3、用awk实现tac
1 $ awk '{ buffer[NR] = $0; } END { for (i=NR; i>0; i--) { print buffer[i] } }' 2 说明:顺序保存,然后逆序打印
总结:刚开始学写脚本,感觉一切好神奇,实现一点简单的功能都好牛X,呵呵~~以后一定多多加油