
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
from tqdm.notebook import tqdm
from matplotlib import pyplot as plt
import seaborn as sns
import lightgbm as lgb
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, StandardScaler
from sklearn.model_selection import KFold, ShuffleSplit, StratifiedKFold
from sklearn.metrics import roc_auc_score, log_loss
baselines
1.数据处理
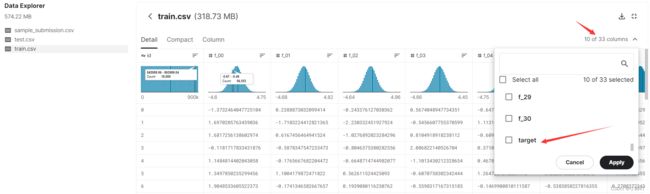
train_df = pd.read_csv('/kaggle/input/tabular-playground-series-may-2022/train.csv')
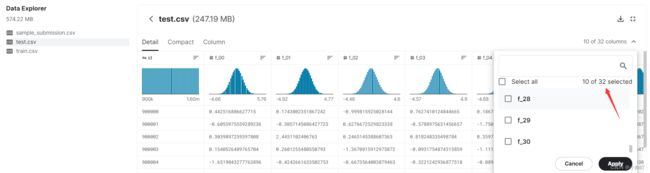
test_df = pd.read_csv('/kaggle/input/tabular-playground-series-may-2022/test.csv')
df = pd.concat([train_df, test_df],axis=0).reset_index(drop=True)
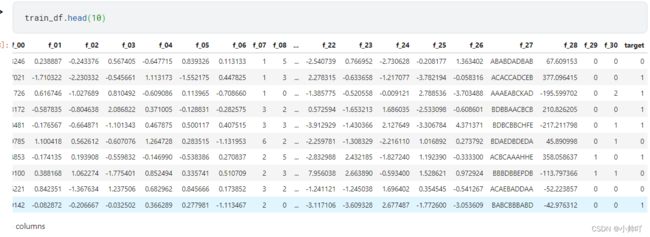
train_df.head(10)
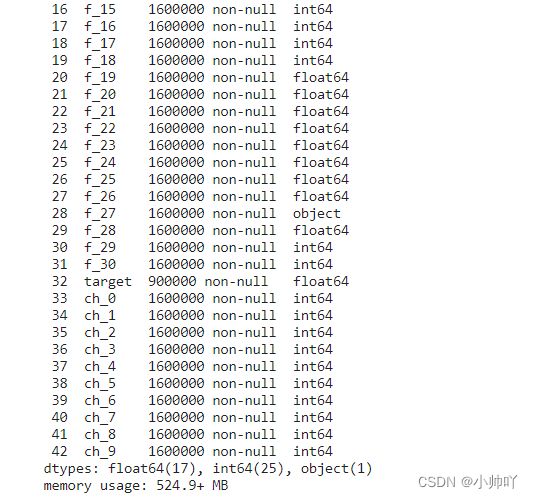
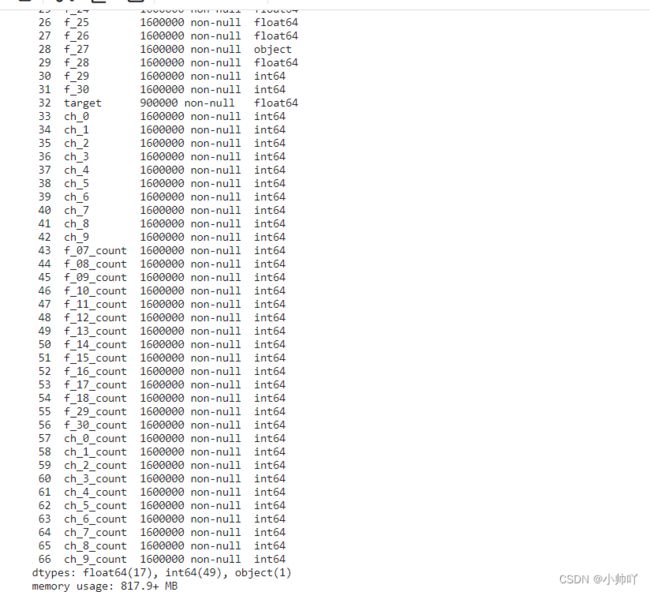
df.info(verbose=True, null_counts=True)

for i in range(10):
df[f'ch_{i}'] = df['f_27'].str.get(i).apply(ord) - ord('A')
df.info(verbose=True, null_counts=True)
num_cols = ['f_00',
'f_01',
'f_02',
'f_03',
'f_04',
'f_05',
'f_06',
'f_19',
'f_20',
'f_21',
'f_22',
'f_23',
'f_24',
'f_25',
'f_26',
'f_28',]
cate_cols = ['f_07',
'f_08',
'f_09',
'f_10',
'f_11',
'f_12',
'f_13',
'f_14',
'f_15',
'f_16',
'f_17',
'f_18',
'f_29',
'f_30'] + [f'ch_{i}' for i in range(10)]
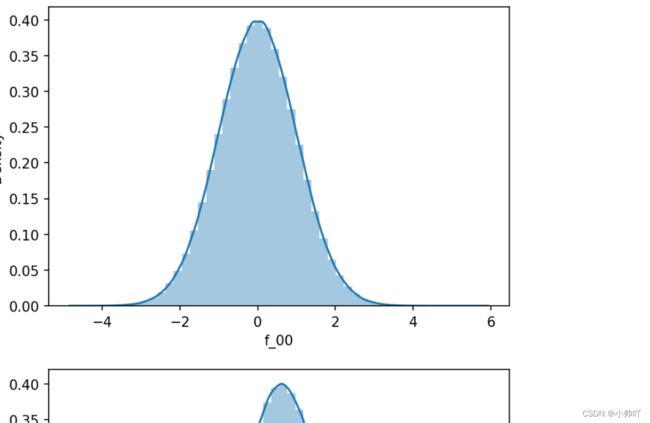
for col in tqdm(num_cols):
plt.figure(dpi=150)
sns.distplot(df[col])
for col in tqdm(num_cols):
df[col] = (df[col] - df[col].mean()) / df[col].std()
# # sklearn 数据编码
# scaler = StandardScaler()
# # scaler = MinMaxScaler()
# df[num_cols] = scaler.fit_transform(df[num_cols])
df.describe()

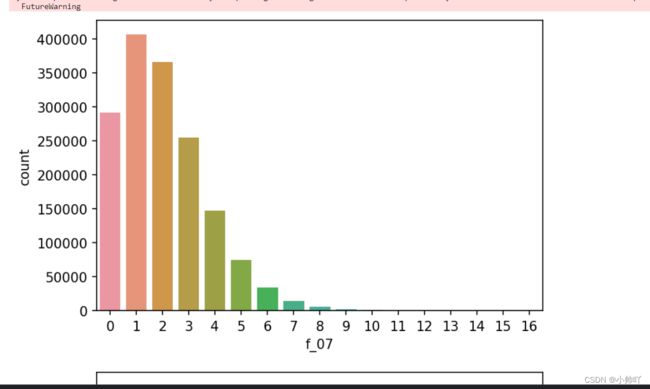
for col in tqdm(cate_cols):
plt.figure(dpi=150)
sns.countplot(df[col])
for col in tqdm(cate_cols):
map_dict = dict(zip(df[col].unique(), range(df[col].nunique())))
df[col] = df[col].map(map_dict)
df[f'{col}_count'] = df[col].map(df[col].value_counts())

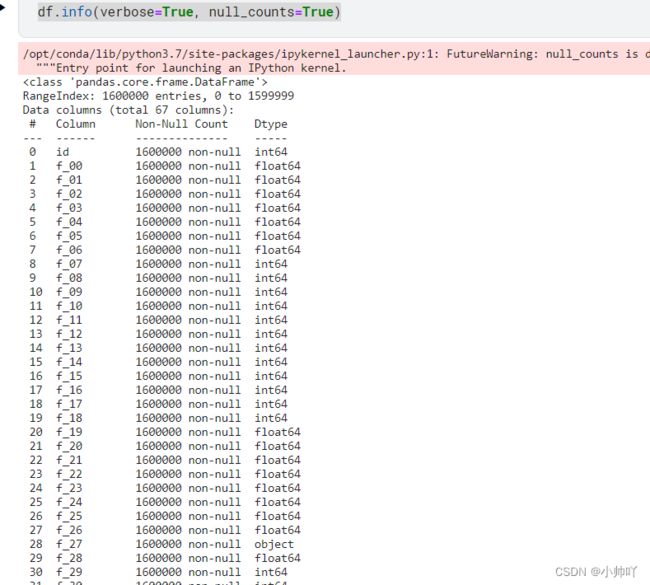
df.info(verbose=True, null_counts=True)
train_df = df[df['target'].notna()].reset_index(drop=True)
test_df = df[df['target'].isna()].reset_index(drop=True)
drop_feature = ['id','target', 'f_27']
feature = [x for x in train_df.columns if x not in drop_feature]
print(len(feature),feature)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5OS77lKN-1663293223185)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220914165149751.png)]](http://img.e-com-net.com/image/info8/aa638dc50160434b8cf2cc189fe52992.jpg)
2.模型调用
'''
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
model.predict(X_test)
# 输出概率(分类任务)
model.predict_proba(X_test)
# 获得这个模型的参数
model.get_params()
'''
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(train_df[feature], train_df['target'], random_state=666)
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import BernoulliNB, MultinomialNB, GaussianNB
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_valid_pre = model.predict_proba(X_valid)[:,1]
print(f'{str(model)} AUC :{roc_auc_score(y_valid, y_valid_pre)}')
print(f'{str(model)} LogLoss :{log_loss(y_valid, y_valid_pre)}')
y_pre = model.predict(test_df[feature])
- lightgbm/xgboost/catboost模型使用
3.模型验证
params = {'num_leaves': 60,
'min_data_in_leaf': 30,
'objective': 'binary',
'max_depth': -1,
'learning_rate': 0.1,
"min_sum_hessian_in_leaf": 6,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.8,
"bagging_seed": 11,
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": -1,
'metric': {'binary_logloss', 'auc'},
"random_state": 2019,
}
n_fold = 5
oof_pre = np.zeros(len(train_df))
y_pre = np.zeros(len(test_df))
kf = KFold(n_splits=n_fold)
for fold_, (trn_idx, val_idx) in enumerate(kf.split(train_df)):
trn_data = lgb.Dataset(train_df[feature].iloc[trn_idx], label=train_df['target'].iloc[trn_idx])
val_data = lgb.Dataset(train_df[feature].iloc[val_idx], label=train_df['target'].iloc[val_idx])
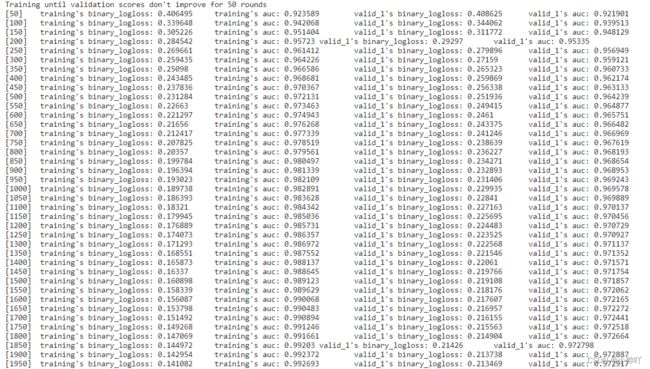
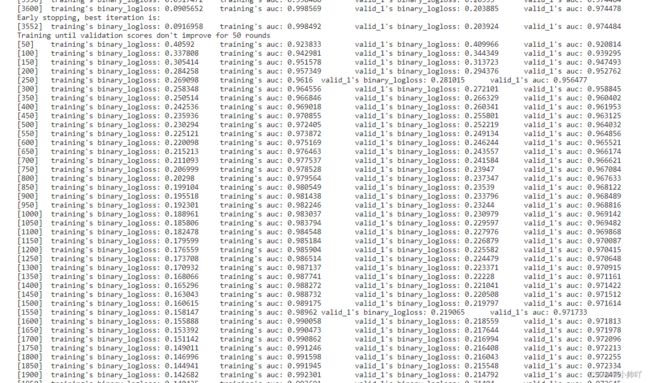
clf = lgb.train(params,
trn_data,
100000,
valid_sets=[trn_data, val_data],
verbose_eval=50,
early_stopping_rounds=50)
oof_pre[val_idx] = clf.predict(train_df[feature].iloc[val_idx], num_iteration=clf.best_iteration)
y_pre += clf.predict(test_df[feature], num_iteration=clf.best_iteration) / n_fold

res_df = pd.DataFrame()
res_df['id'] = test_df['id']
res_df['target'] = y_pre
res_df.to_csv('/kaggle/working/baseline.csv',index=False)