STM32运行深度学习指南基础篇(3)(STM32CubeMX.AI+Tensorflow)
STM32运行深度学习指南基础篇(3)(STM32CubeMX.AI+Tensorflow)
在上一篇文章中我们已经有训练好的tflite模型,接下来我们要在Clion中实现,如果是Keil的朋友可以跳转至这篇文章
STM32运行深度学习指南基础篇(4)(STM32CubeMX.AI+Tensorflow)
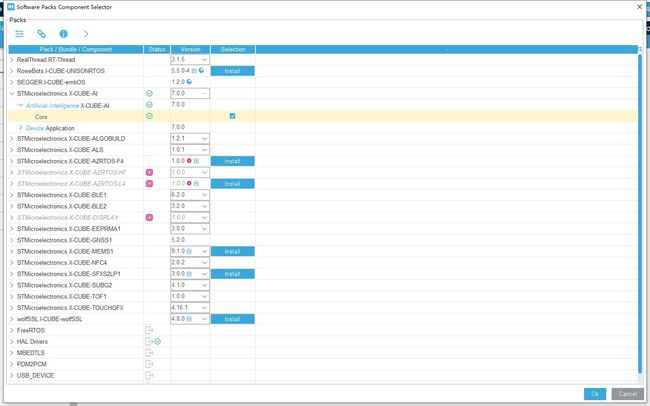
在我们新建好的STM32CubeMX中勾选,我们的AI包:
打开串口:

激活AI模块,载入模型,点击analyze
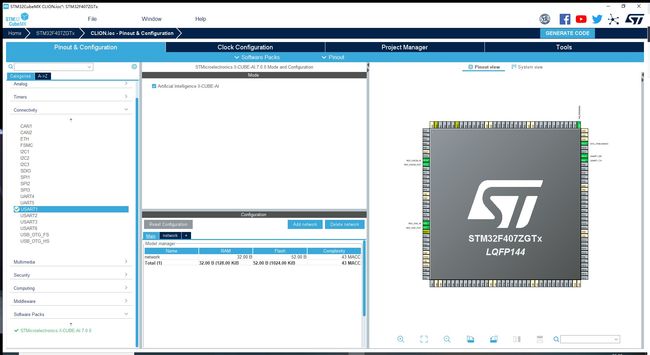

我们修改生成的main代码
在/* USER CODE BEGIN Includes / …/ USER CODE END Includes */中添加需要的头文件
/* USER CODE BEGIN Includes */
#include "ai_platform.h"
#include "network.h"
#include "network_data.h"
#include "stdio.h"
/* USER CODE END Includes */
在/* USER CODE BEGIN PTD /…/ USER CODE END PTD */,添加printf相关函数
/* USER CODE BEGIN PTD */
#ifdef __GNUC__
#define PUTCHAR_PROTOTYPE int __io_putchar(int ch)
#else
#define PUTCHAR_PROTOTYPE int fputc(int ch, FILE *f)
#endif
PUTCHAR_PROTOTYPE
{
HAL_UART_Transmit(&huart1,(uint8_t*)&ch, 1, 0xFFFF);
return ch;
}
/* USER CODE END PTD */
在/* USER CODE BEGIN PV /…/ USER CODE END PV */中添加需要的相关变量
/* USER CODE BEGIN PV */
/* 输入数据 */
float aiInData[16][AI_NETWORK_IN_1_SIZE] = {
{1, 1, 1, 0},
{1, 1, 0, 1},
{1, 1, 1, 1},
{1, 1, 0, 0},
{1, 0, 1, 0},
{1, 0, 0, 1},
{1, 0, 1, 1},
{1, 0, 0, 0},
{0, 1, 1, 0},
{0, 1, 0, 1},
{0, 1, 1, 1},
{0, 1, 0, 0},
{0, 0, 1, 0},
{0, 0, 0, 1},
{0, 0, 1, 1},
{0, 0, 0, 0},
};
/* 正确值 */
uint8_t test_data[16] = {
1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0
};
ai_handle network;
float aiOutData[AI_NETWORK_OUT_1_SIZE];
uint8_t activations[AI_NETWORK_DATA_ACTIVATIONS_SIZE];
/* USER CODE END PV */
在/* USER CODE BEGIN 0 /…/ USER CODE END 0 */中添加初始化和运行模型的代码
/* USER CODE BEGIN 0 */
/* 初始化函数 */
void Init(ai_handle w_addr, ai_handle act_addr)
{
ai_error err;
err = ai_network_create(&network, AI_NETWORK_DATA_CONFIG);
if (err.type != AI_ERROR_NONE) {
printf("创建失败 - code=%d code=%d\r\n", err.type, err.code);
Error_Handler();
}
const ai_network_params params = AI_NETWORK_PARAMS_INIT(
AI_NETWORK_DATA_WEIGHTS(w_addr),
AI_NETWORK_DATA_ACTIVATIONS(act_addr)
);
if (!ai_network_init(network, ¶ms)) {
err = ai_network_get_error(network);
printf("初始化失败 - code=%d code=%d\r\n", err.type, err.code);
Error_Handler();
}
}
/* 运行函数 */
void Run(float *pIn, float *pOut)
{
ai_i32 batch;
ai_error err;
ai_buffer ai_input[AI_NETWORK_IN_NUM] = AI_NETWORK_IN;
ai_buffer ai_output[AI_NETWORK_OUT_NUM] = AI_NETWORK_OUT;
ai_input[0].n_batches = 1;
ai_input[0].data = AI_HANDLE_PTR(pIn);
ai_output[0].n_batches = 1;
ai_output[0].data = AI_HANDLE_PTR(pOut);
batch = ai_network_run(network, ai_input, ai_output);
if (batch != 1) {
err = ai_network_get_error(network);
printf("运行失败 - code=%d code=%d\r\n", err.type, err.code);
Error_Handler();
}
}
/* USER CODE END 0 */
在/* USER CODE BEGIN 2 /…/ USER CODE END 2 */中添加运行函数
/* USER CODE BEGIN 2 */
printf("测试开始: \r\n");
uint8_t correct = 0;
Init(ai_network_data_weights_get(), activations);
printf("===========\r\n");
for (int i = 0; i < 16; ++i) {
Run(aiInData[i], aiOutData);
if ((int)(aiOutData[0]+0.5f)==test_data[i]){
printf("%d | %d 相符\r\n",(int)(aiOutData[0]+0.5f),test_data[i]);
correct++;
}
else{
printf("%d | %d 不符\r\n",(int)(aiOutData[0]+0.5f),test_data[i]);
}
printf("===========\r\n");
}
printf("测试完成: 准确率 %d %%\r\n",correct*100/16);
/* USER CODE END 2 */
更改CMakeLists和CMakeLists_template,主要是把文件中的那个.a的静态库文件文件引入,在“add_executable…“语句后加入
target_link_libraries(${PROJECT_NAME}.elf ${PROJECT_SOURCE_DIR}/Middlewares/ST/AI/Lib/NetworkRuntime700_CM4_GCC.a)
最后编译即可
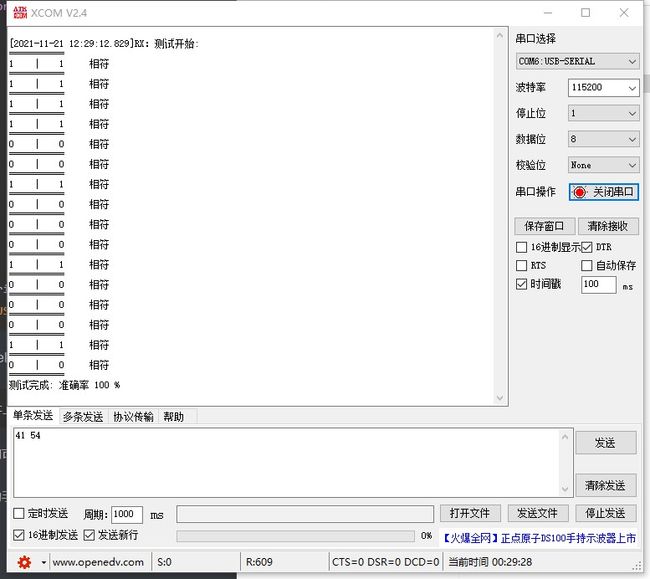
在串口助手可以看到结果:
这篇文章的代码在Gitee上
https://gitee.com/shibwoen/stm32_tensorflow/tree/master/CLION
同时我也参考了文章
https://wiki.stmicroelectronics.cn/stm32mcu/wiki/AI:How_to_perform_motion_sensing_on_STM32L4_IoTnode#Real-time_scheduling_considerations