吴恩达深度学习笔记-Logistic Regression(第1课)
深度学习笔记
- 第一课 深度学习介绍
-
- 1、什么是神经网络?
- 2、用神经网络进行监督学习
- 3、深度学习为什么会兴起?
- 第二课 神经网络基础知识
-
- 1、二分分类
- 2、Logistic Regression
- 3、Logistic Regression损失函数
- 4、Logistic Regression梯度下降
- 5、向量化Logistic Regression
- 6、向量化Logistic Regression的梯度输出
- 7、Python中的广播
- 8、关于Python中numpy的说明
- 9、Logistic损失函数的解释
第一课 深度学习介绍
1、什么是神经网络?
以房价预测为例子:
希望通过房子大小预测房价,最直接的想法就是用一条直线去拟合数据,当然房价不可能为负数,因此你可能会得到下图的函数图像:
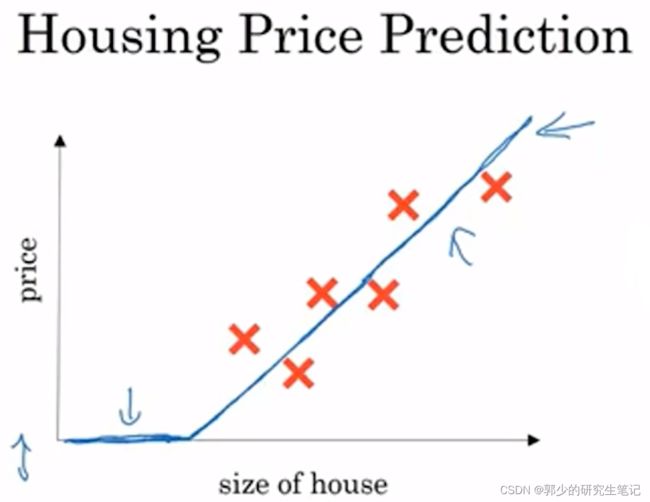
这个函数可以看作是一个最简单的神经网络:

将房子尺寸输入神经节点(上图中的小圆圈)后得到房子的价格。这个圆圈就是一个单独的神经元,这个圆圈构成的神经网络实现了房价预测的功能。
当你考虑的因素多了之后,可以使用更大的神经网络来预测房价。
如:
基于房子尺寸和房间数量,可以估算容纳的家庭成员大小,基于邮政编码会估测附近的交通能力,基于邮编和福语程度可以估测当地的学校质量。
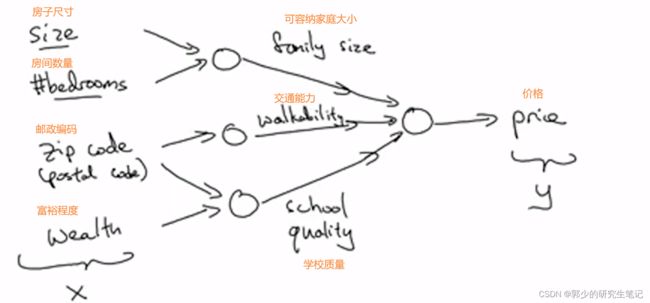
在这里只输入了四个因素,但考虑了很多混合不同的因素,最后给出预测的房价。这正是神经网络的神奇之处,我们需要做的仅仅是输入4个考虑因素,所以中间的过程,它都会自己完成。
2、用神经网络进行监督学习
神经网络在监督学习方面的应用:
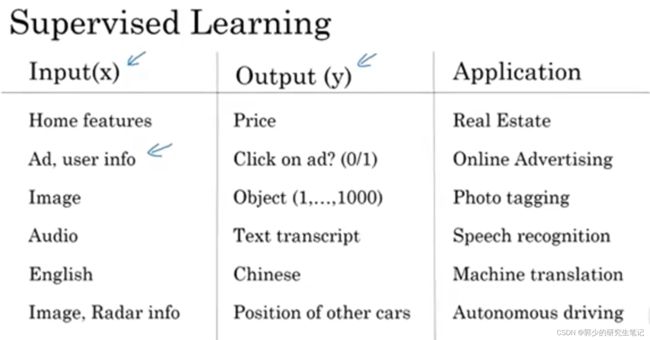
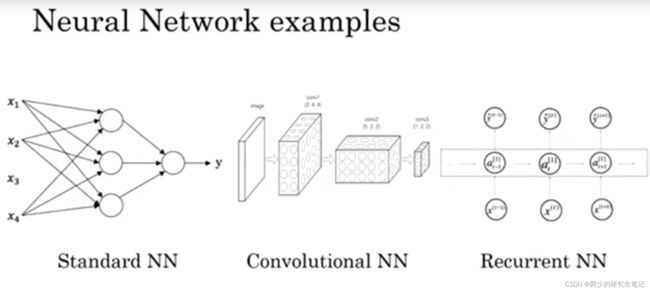
房价预测和用户广告分析一般采用的是标准的神经网络;对于图像来说,采用的一般是卷积神经网络(CNN);对于含有时间成分的音频可以表示成时间序列,对于序列数据通常采用递归神经网络(RNN);英文翻译中单词都是逐个出现的,所以语言最自然的表示方式也是序列数据,通常采用更复杂的RNN。
下图为三种神经网络的图例表示,今后的学习会深入了解这三种神经网络。
机器学习被应用于结构化数据和非结构化数据:
结构化数据是数据的数据库。
例如在房价预测中,你可能有一个数据库,有专门的几列数据告诉你卧室的大小和数量。【数据的含有定义很清晰】

非结构化数据通常指音频、图像或文本中的内容,这里的特征可能是图像的像素值或者文本中的单词

描述非结构化数据通常很难,但深度学习和神经网络的兴起让计算机能够更好的描述非结构化数据。
3、深度学习为什么会兴起?
传统的机器学习很难处理海量的数据,随着数据集的大量增加,传统机器学习系统的性能表现会进入平台期。但现在我们很容易获得海量的数据,远超传统机器学习能发挥作用的规模。深度学习和神经网络可以突破这个平台期;例如可以通过更加复杂的神经网络和海量的数据去提高系统的性能表现。

第二课 神经网络基础知识
1、二分分类
这里有一个二分类问题(Binary Classification):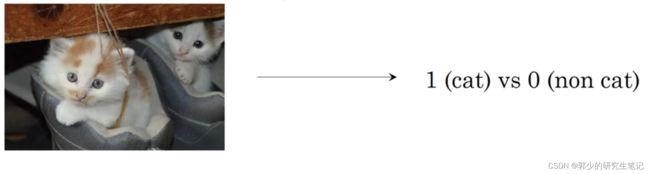
输入一张图片,判断是否是猫,即输出只有0或1两种。
下面介绍一些接下来会用到的符号:
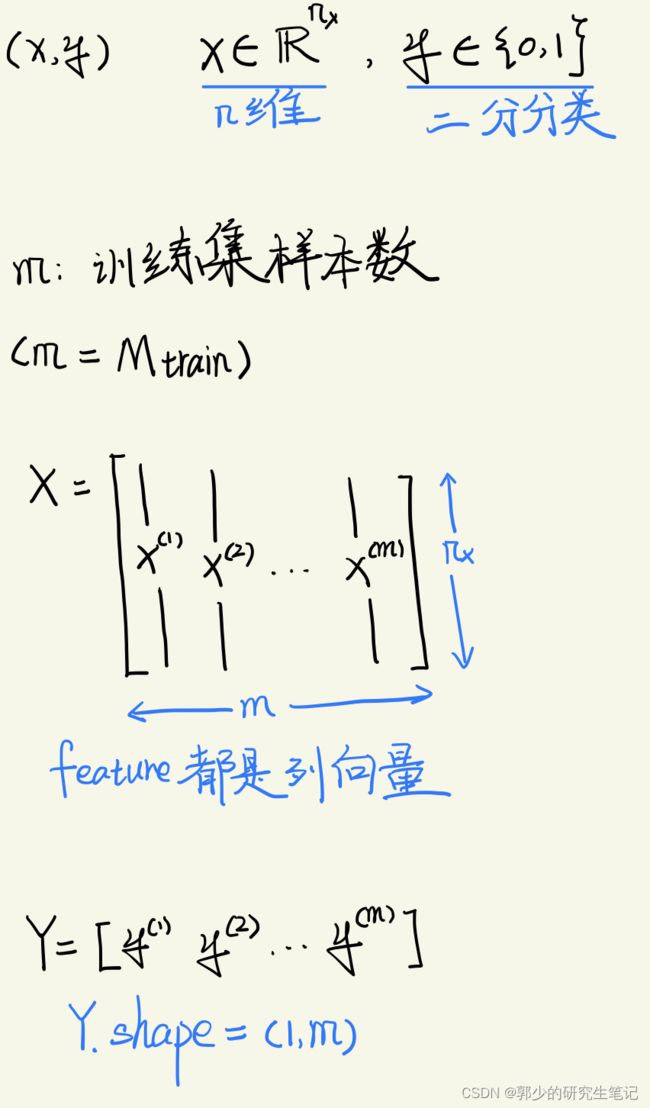
2、Logistic Regression
Logistic Regression适用于二分类问题;对于二分类问题,给出features,我们想要知道y=1的概率,即P(y=1|x)在x的情况下y=1的概率。
对于传统的线性拟合,我们需要找到参数w和偏置b,拟合一条曲线y = wx+b来进行分类,但是结果会有正有负,但我们想得到的概率是0~1之间的数;因此Logistic Regression将wx+b输入到sigmoid函数中去,将线性函数转换为非线性函数,且输出结果在0~1之间。

当z趋向于正无穷大时,e-z≈0,σ(z)=1;
当z趋向于负无穷大时,e-z≈+∞,σ(z)=0。

逻辑回归数学描述如下图:

3、Logistic Regression损失函数
可以将损失函数定义为最小二乘法,但是得到的损失函数图像是非凸的,会得到很多个局部最优解。
为了将损失函数转换成凸函数,使用下面的loss function损失函数函数式子:
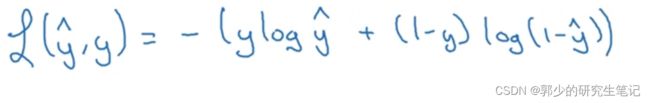
为什么这个损失函数能够起效呢?
看下面这两个例子:
【y表示真实分类,y’表示预测结果】
(1)当y=1时,损失函数为L(y’,y) = -log(y’)
想要使损失函数值小,其实就是让log(y’)尽可能的大;log(y’)尽可能的大,其实就是让y’尽可能的大,而y’∈[0,1],其实就是想让预测结果更接近1。
(2)当y=0时,损失函数为L(y’,y) = -log(1-y’)
想要使损失函数值小,其实就是让log(1-y’)尽可能的大;log(1-y’)尽可能的大,其实就是让y’尽可能的小,而y’∈[0,1],其实就是想让预测结果更接近0。

cost function成本函数为:
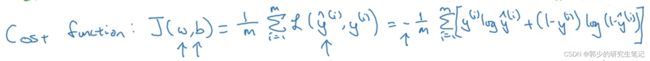
损失函数Loss function一般是基于当个样本,成本函数cost function是基于参数的总成本。所以Logistic Regression要做的事就是找到合适的w和b使cost function尽可能的小
4、Logistic Regression梯度下降
下图是Logistic Regression算法:

梯度下降下降做的就是不断的调整w和b,使成本函数J(w,b)达到最小值。
因为逻辑回归代价函数的特性,我们定义其成本函数J(w,b)为凸函数,如下图所示。
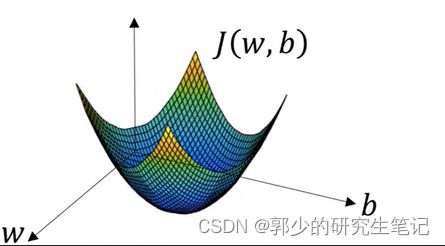
因为成本函数J(w,b)是凸函数,只有一个局部(全局)最优解,因此可以将w和b定义为任何数,即从上图得任意一个点开始进行梯度下降,最后都能走到局部最优解。
如下图,每过一轮迭代调整w和b,J(w,b)就会变小一些,逐步达到局部最优或者接近局部最优.

如何调整w和b呢?需要通过J(w,b)对w和b的偏导进行调整,如下图:

【α表示学习率】
接下来需要做的是对J(w,b)分别对w和b求偏导:

扩:
可以使用向量化代替for循环,向量化能够加速你的代码;能不用for就不要用for,多用numpy进行数据处理
5、向量化Logistic Regression

关于z:
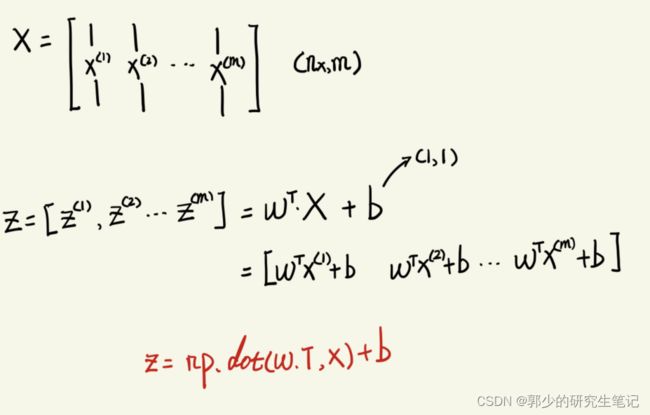
即:z = np.dot(w.T,X)+b
关于a:

即:A = sigmoid(z)
6、向量化Logistic Regression的梯度输出
梯度下降公式如下图:

向量化如下图:

完整的逻辑回归梯度下降:
未向量化版:

向量化版本:
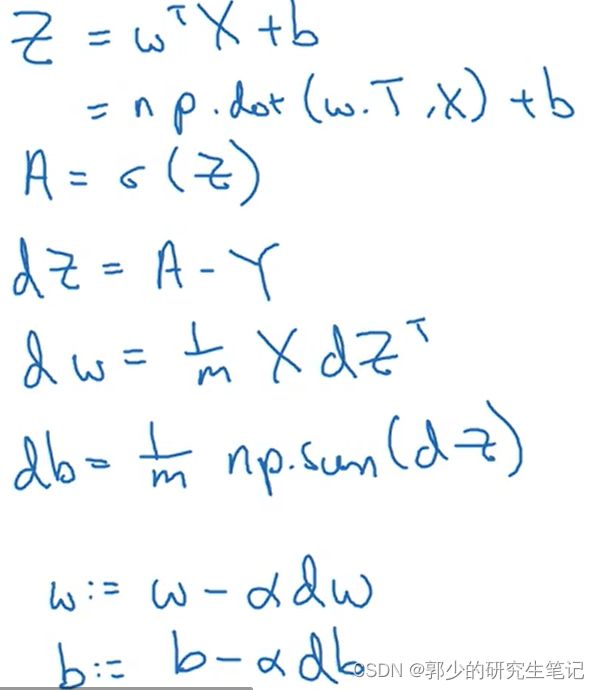
7、Python中的广播
下图给出了各种食物中,碳水、蛋白质和脂肪中的卡路里含量,想计算下列各食物中碳水在碳水、蛋白质和脂肪中的占比。

最直接的想法就是先按列求和,在for循环遍历数组除于卡路里各食物卡路里总量。
for循环十分繁琐且耗时,
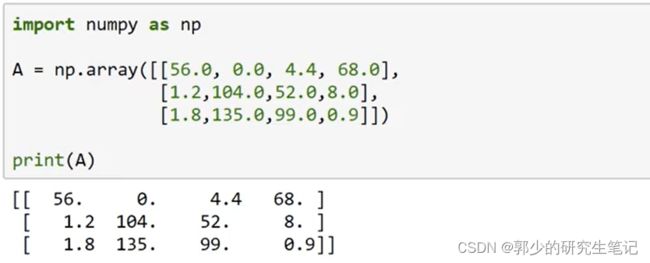
可以使用python两行代码搞定他,令上述数组为A,下面编写代码:
第一步,按列求和:

第二步,计算百分比:
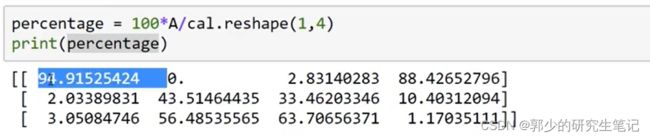
核心代码:
#按列求和
cal = A.sum(axis=0)
#除于一个1x4的矩阵
percentage = 100*A/(cal.reshape(1,4))
如何让一个3x4的矩阵除于1x4的矩阵?
Python中的广播:
对于(m,n)和(1,n)的运算,python会将(1,n)的矩阵按行复制m次,展开成(m,n)大小再进行运算。
如:

对于(m,n)和(m,1)的运算,python会将(m,1)的矩阵按列复制n次,展开成(m,n)大小再进行运算。
如:

8、关于Python中numpy的说明
(5,)既不是行向量也不是列向量,其为秩为1的数组,在向量/矩阵运算时应避免这种表示方式。
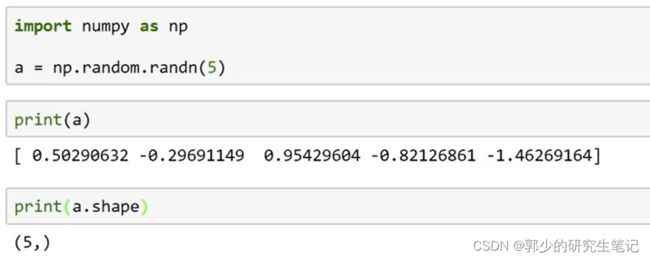
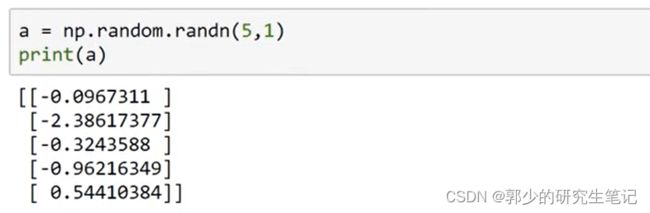
应采用下图的方式,区别是在内层多了方括号,这才是5x1的矩阵
在我们不确定数据的维度时,使用断言assert()去判断数据的维度。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况

总之,消除秩为1的数组的使用可以减少很多bug!
9、Logistic损失函数的解释
逻辑回归输出的是y=1的概率值,因此可以得到:

上述就是一个0-1分布,将其合并成一个式子(0-1分布的表示):

上图是P(y|x)的正确定义。因为log函数是单调递增的,所以最大化P(y|x),也是最大化logP(y|x)。logP(y|x)可以推导成下图:
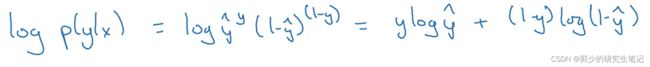
上图正好是Loss function的相反数。当训练学习算法时需要算法输出值的概率是最大的,然而在逻辑回归中需要最小化损失函数,因此最小化损失函数就是最大化logP(y|x) ,因此这就是单个训练样本的损失函数表达式。
训练学习算法时需要算法输出值的概率是最大的:
我们是假设了数据符合某种分布后计算出y=1的概率的,因此对于训练集中y=1的所以样本,希望他们输出的概率相乘后的值越大越好,越大就越符合假设的分布。
对于m个样本来说:

接下来就是通过极大使然估计去寻找w和b使这个函数式得到最小,这个式子就是cost function。