mysql curd_mysql 基础之CURD
原文:mysql 基础之CURD
增删改查基本语法学习
增: insert
Insert 3问:
1: 插入哪张表?
2: 插入哪几列?
3: 这几列分别插入什么值?
Insert into TableName
(列1,列2....列n)
Values
(值1,值2,....值n)
值 与 列,按顺序,一一对应
特殊: insert语句 允不允许不写列名
答:允许.
如果没有声明列明,则默认插入所有列.
因此,值应该与全部列,按顺序一一对应.
例:建一张工资登记表
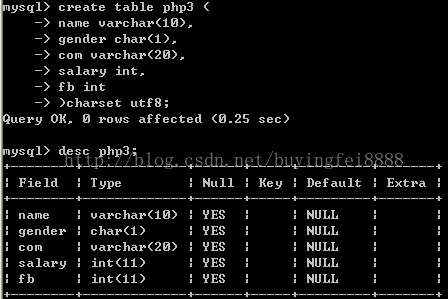
2:插入部分列
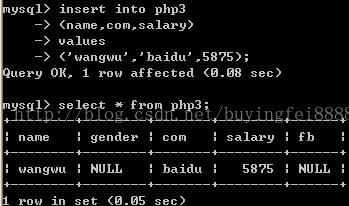
注:文中的set names gbk;是为了告诉服务器,客户端用的GBK编码,防止乱码.
4:插入所有的列的简单写法.
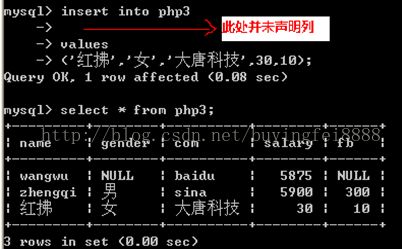
insert 中数字不需要加单引号,会降低解析速度,字符窜必须加单引号,不然会报错!
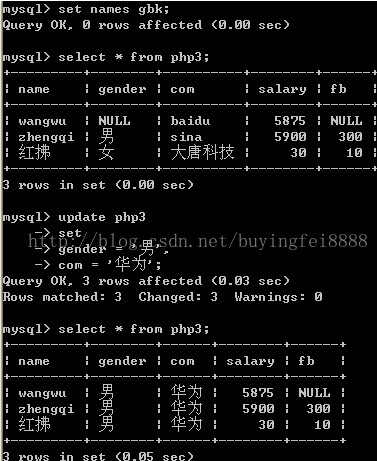
改: Update语句
Update 4问
改哪张表?
改哪几列的值?
分别改为什么值?
在哪些行生效?
语法:
Update 表名
Set
列1 =新值1,
列2 =新值2,
列n =新值n.....
Where expr
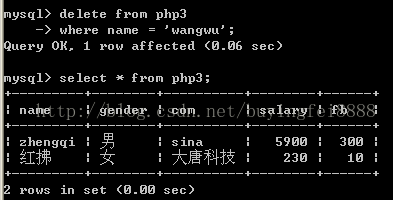
删除: delete
Delete 2问
从哪张表删除数据?
要删除哪些行?
语法:
Delete from 表名where expr
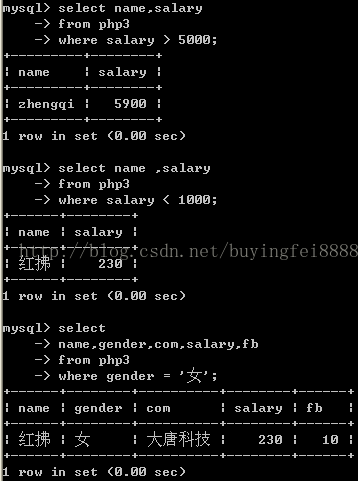
查: select
查询3问
1:查哪张表的数据?
2:查哪些列的数据?
3:查哪些行的数据?
语法:
Select 列1,列2,列3,...列n
From 表名
Where expr;
排序:
磁盘里的数据可能排好序,也可能没排序,就需要到内存里面进行排序,这就比较浪费时间了。
当最终结果集出来后,可以进行排序.
排序的语法:
Order by 结果集中的列名desc/asc
例:order by shop_price desc ,按价格降序排列
Order by add_time asc ,按发布时间升序排列.
多字段排序也很容易
Order by 列1 desc/asc, 列2 desc/asc, 列3 desc,asc
Limit 在语句的最后,起到限制条目的作用,在分页类中发挥很大作用
Limit [offset,] N
Offset: 偏移量,----跳过几行
N: 取出条目
Offset,如果不写,则相当于limit 0,N
子查询
Where型子查询:指把内层查询的结果作为外层查询的比较条件.
典型题:查询最大商品,最贵商品
Where型子查询
如果 where列=(内层sql),则内层sql返回的必是单行单列,单个值
如果 where列in (内层sql),则内层sql只返回单列,可以多行.
From 型子查询:把内层的查询结果当成临时表,供外层sql再次查询
典型题:查询每个栏目下的最新/最贵商品
Exists子查询:把外层的查询结果,拿到内层,看内层的查询是否成立.
典型题:查询有商品的栏目
模糊查询:
案例:想查找"诺基亚"开头的所有商品
Like->像
% --> 通配任意字符
'_' --> 单个字符
查询模型(重要)
列就是变量,在每一行上,列的值都在变化.
Where条件是表达式,在哪一行上表达式为真,
哪一行就取出来
比如下面的条件, shop_price在不同的行,有不同的值.
在哪一行时,shop_price>5000如果为真,则这行取出来.
查询结果集--在结构上可以当成表看
select count(*) from 表名,查询的就是绝对的行数,哪怕某一行所有字段全为NULL,也计算在内.
而select couht(列名) from表名,
查询的是该列不为null的所有行的行数.
用count(*),count(1),谁好呢?
其实,对于myisam引擎的表,没有区别的.
这种引擎内部有一计数器在维护着行数.
Innodb的表,用count(*)直接读行数,效率很低,因为innodb真的要去数一遍.

左连接的语法:
假设A表在左,不动,B表在A表的右边滑动.
A表与B表通过一个关系来筛选B表的行.
语法:
A left join B on 条件 条件为真,则B表对应的行,取出
A left join B on 条件
这一块,形成的也是一个结果集,可以看成一张表 设为C
既如此,可以对C表作查询,自然where,group ,having ,order by ,limit照常使用
问:C表的可以查询的列有哪些列?
答: A B的列都可以查
/*
左连接 右连接,内连接的区别在哪儿?
*/

主持人大声说:
所有的男士,站到舞台上,带上自己的配偶,(没有的拿块牌子,上写NULL)
思考:张三上不上舞台呢?
答:上,
问:张三没有对应的行怎么办?
答:用NULL补齐
结果如下

这种情况就是 男生 left join女生.
主持人说:所有女生请上舞台,有配偶的带着,没有的,写个NULL补齐.
Select 女生left join男生on条件
左右连接是可以互换的
A left join B, 就等价于B right join A
注意:既然左右连接可以互换,尽量用左连接,出于移植时兼容性方面的考虑.
内连接的特点
主持人说: 所有有配偶的男生/女生,走到舞台上来
这种情况下: 屌丝和宝钗都出局

如果从集合的角度
A inner join B
和 left join /rightjoin的关系
答: 内连接是左右连接的交集
主持人说:所有男生/女生,走上舞台.
有配偶的,带着配偶;
没配偶的,拿牌子写NULL
即:结果是左右连接的并集
这种叫做外连接,但是,在mysql中不支持外连接
Union:合并2条或多条语句的结果
语法:
Sql1 union sql2
能否从2张表查询再union呢?
答:可以,union合并的是"结果集",不区分在自于哪一张表.
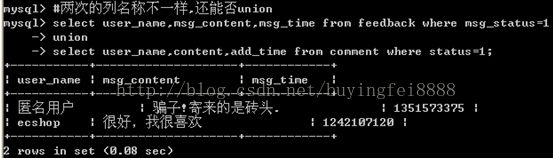
问:取自于2张表,通过"别名"让2个结果集的列一致.
那么,如果取出的结果集,列名字不一样,还能否union.
答:可以,如下图,而且取出的最终列名,以第1条sql为准
问:union满足什么条件就可以用了?
答:只要结果集中的列数一致就可以.
问: union后结果集,可否再排序呢?
答:可以的.
Sql1 union sql2 order by 字段
注意: order by是针对合并后的结果集排的序.
思考如下语句:
(SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE cat_id = 4 ORDER BY shop_price DESC)
UNION
(SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE cat_id = 5 ORDER BY shop_price DESC)
order by shop_price asc;
外层语句还要对最终结果,再次排序.
因此,内层的语句的排序,就没有意义.
因此:内层的order by语句单独使用,不会影响结果集,仅排序,
在执行期间,就被Mysql的代码分析器给优化掉了.
内层的order by必须能够影响结果集时,才有意义.
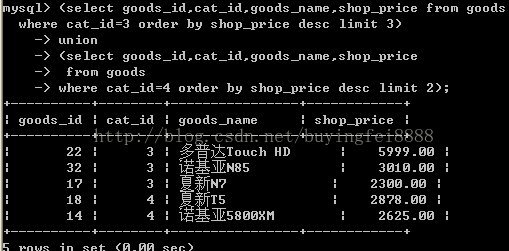
这一次:内层的order by发挥了作用,因为有limit ,order会实际影响结果集,有意义.
如果Union后的结果有重复(即某2行,或N行,所有的列,值都一样),怎么办?
答:这种情况是比较常见的,默认会去重.
问:如果不想去重怎么办?
答: union all