Pandas分组运算(groupby)
原文:https://www.cnblogs.com/lemonbit/p/6810972.html
侵删。
Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚。
今天,我们一起来领略下groupby()的魅力吧。
首先,引入相关package:
import pandas as pd
import numpy as np
groupby的基础操作
In [2]: df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'],
...: 'B': [2, 8, 1, 4, 3, 2, 5, 9],
...: 'C': [102, 98, 107, 104, 115, 87, 92, 123]})
...: df
...:
Out[2]:
A B C
0 a 2 102
1 b 8 98
2 a 1 107
3 c 4 104
4 a 3 115
5 c 2 87
6 b 5 92
7 c 9 123
按A列分组(groupby),获取其他列的均值
df.groupby('A').mean()
Out[3]:
B C
A
a 2.0 108.000000
b 6.5 95.000000
c 5.0 104.666667
按多列进行分组(groupby)
df.groupby(['A','B']).mean()
Out[4]:
C
A B
a 1 107
2 102
3 115
b 5 92
8 98
c 2 87
4 104
9 123
分组后选择列进行运算
分组后,可以选取单列数据,或者多个列组成的列表(list)进行运算
In [5]: df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"])
...: df
...:
Out[5]:
A B C
0 1 1 2
1 1 2 3
2 2 3 4
In [6]: g = df.groupby("A")
In [7]: g['B'].mean() # 仅选择B列
Out[7]:
A
1 1.5
2 3.0
Name: B, dtype: float64
In [8]: g[['B', 'C']].mean() # 选择B、C列
Out[8]:
B C
A
1 1.5 2.5
2 3.0 4.0
可以针对不同的列选用不同的聚合方法
In [9]: g.agg({'B':'mean', 'C':'sum'})
Out[9]:
B C
A
1 1.5 5
2 3.0 4
聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
In [10]: df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
...: "City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
...: "Val":[4,3,3,np.nan,np.nan,4]})
...:
...: df
...:
Out[10]:
City Name Val
0 Seattle Alice 4.0
1 Seattle Bob 3.0
2 Portland Mallory 3.0
3 Seattle Mallory NaN
4 Seattle Bob NaN
5 Portland Mallory 4.0
count()
In [11]: df.groupby(["Name", "City"], as_index=False)['Val'].count()
Out[11]:
Name City Val
0 Alice Seattle 1
1 Bob Seattle 1
2 Mallory Portland 2
3 Mallory Seattle 0
size()
In [12]: df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
Out[12]:
Name City Size
0 Alice Seattle 1
1 Bob Seattle 2
2 Mallory Portland 2
3 Mallory Seattle 1
分组运算方法 agg()
针对某列使用agg()时进行不同的统计运算
In [13]: df = pd.DataFrame({'A': list('XYZXYZXYZX'), 'B': [1, 2, 1, 3, 1, 2, 3, 3, 1, 2],
...: 'C': [12, 14, 11, 12, 13, 14, 16, 12, 10, 19]})
...: df
...:
Out[13]:
A B C
0 X 1 12
1 Y 2 14
2 Z 1 11
3 X 3 12
4 Y 1 13
5 Z 2 14
6 X 3 16
7 Y 3 12
8 Z 1 10
9 X 2 19
In [14]: df.groupby('A')['B'].agg({'mean':np.mean, 'standard deviation': np.std})
Out[14]:
mean standard deviation
A
X 2.250000 0.957427
Y 2.000000 1.000000
Z 1.333333 0.577350
针对不同的列应用多种不同的统计方法
In [15]: df.groupby('A').agg({'B':[np.mean, 'sum'], 'C':['count',np.std]})
Out[15]:
B C
mean sum count std
A
X 2.250000 9 4 3.403430
Y 2.000000 6 3 1.000000
Z 1.333333 4 3 2.081666
分组运算方法 apply()
In [16]: df = pd.DataFrame({'A': list('XYZXYZXYZX'), 'B': [1, 2, 1, 3, 1, 2, 3, 3, 1, 2],
...: 'C': [12, 14, 11, 12, 13, 14, 16, 12, 10, 19]})
...: df
...:
Out[16]:
A B C
0 X 1 12
1 Y 2 14
2 Z 1 11
3 X 3 12
4 Y 1 13
5 Z 2 14
6 X 3 16
7 Y 3 12
8 Z 1 10
9 X 2 19
In [17]: df.groupby('A').apply(np.mean)
...: # 跟下面的方法的运行结果是一致的
...: # df.groupby('A').mean()
Out[17]:
B C
A
X 2.250000 14.750000
Y 2.000000 13.000000
Z 1.333333 11.666667
apply()方法可以应用lambda函数,举例如下:
In [18]: df.groupby('A').apply(lambda x: x['C']-x['B'])
Out[18]:
A
X 0 11
3 9
6 13
9 17
Y 1 12
4 12
7 9
Z 2 10
5 12
8 9
dtype: int64
In [19]: df.groupby('A').apply(lambda x: (x['C']-x['B']).mean())
Out[19]:
A
X 12.500000
Y 11.000000
Z 10.333333
dtype: float64
分组运算方法 transform()
前面进行聚合运算的时候,得到的结果是一个以分组名为 index 的结果对象。如果我们想使用原数组的 index 的话,就需要进行 merge 转换。transform(func, args, *kwargs) 方法简化了这个过程,它会把 func 参数应用到所有分组,然后把结果放置到原数组的 index 上(如果结果是一个标量,就进行广播):
In [20]: df = pd.DataFrame({'group1' : ['A', 'A', 'A', 'A',
...: 'B', 'B', 'B', 'B'],
...: 'group2' : ['C', 'C', 'C', 'D',
...: 'E', 'E', 'F', 'F'],
...: 'B' : ['one', np.NaN, np.NaN, np.NaN,
...: np.NaN, 'two', np.NaN, np.NaN],
...: 'C' : [np.NaN, 1, np.NaN, np.NaN,
...: np.NaN, np.NaN, np.NaN, 4]})
...: df
...:
Out[20]:
B C group1 group2
0 one NaN A C
1 NaN 1.0 A C
2 NaN NaN A C
3 NaN NaN A D
4 NaN NaN B E
5 two NaN B E
6 NaN NaN B F
7 NaN 4.0 B F
In [21]: df.groupby(['group1', 'group2'])['B'].transform('count')
Out[21]:
0 1
1 1
2 1
3 0
4 1
5 1
6 0
7 0
Name: B, dtype: int64
In [22]: df['count_B']=df.groupby(['group1', 'group2'])['B'].transform('count')
...: df
...:
Out[22]:
B C group1 group2 count_B
0 one NaN A C 1
1 NaN 1.0 A C 1
2 NaN NaN A C 1
3 NaN NaN A D 0
4 NaN NaN B E 1
5 two NaN B E 1
6 NaN NaN B F 0
7 NaN 4.0 B F 0
上面运算的结果分析: {‘group1’:’A’, ‘group2’:’C’}的组合共出现3次,即index为0,1,2。对应”B”列的值分别是”one”,”NaN”,”NaN”,由于count()计数时不包括Nan值,因此{‘group1’:’A’, ‘group2’:’C’}的count计数值为1。
transform()方法会将该计数值在dataframe中所有涉及的rows都显示出来(我理解应该就进行广播)
将某列数据按数据值分成不同范围段进行分组(groupby)运算
In [23]: np.random.seed(0)
...: df = pd.DataFrame({'Age': np.random.randint(20, 70, 100),
...: 'Sex': np.random.choice(['Male', 'Female'], 100),
...: 'number_of_foo': np.random.randint(1, 20, 100)})
...: df.head()
...:
Out[23]:
Age Sex number_of_foo
0 64 Female 14
1 67 Female 14
2 20 Female 12
3 23 Male 17
4 23 Female 15
这里将“Age”列分成三类,有两种方法可以实现:
(a)bins=4
(b)bins=[19, 40, 65, np.inf]
In [24]: pd.cut(df['Age'], bins=4)
Out[24]:
...
In [25]: pd.cut(df['Age'], bins=[19,40,65,np.inf])
分组结果范围结果如下:

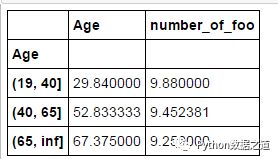
In [26]: age_groups = pd.cut(df['Age'], bins=[19,40,65,np.inf])
...: df.groupby(age_groups).mean()
运行结果如下:
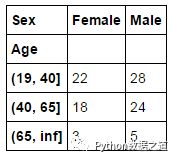
按‘Age’分组范围和性别(sex)进行制作交叉表
In [27]: pd.crosstab(age_groups, df['Sex'])
运行结果如下: