《深度学习:算法到实战》【第一周】深度学习基础笔记
深度学习基础
代码练习
代码来源1
代码来源2
1、登录谷歌云盘,创建好工作区域,执行Colab语句,创建张量成功
2、torch创建n维全1张量

3、dtype指定张量内部的数据类型

4、new_ones基于现有的张量,创建一个新张量,利用dtype,device,size之类的属性信息

5、randn_like利用原有的张量大小,创建一个新的张量,并且填充的为均值为 0,方差为 1的浮点数。

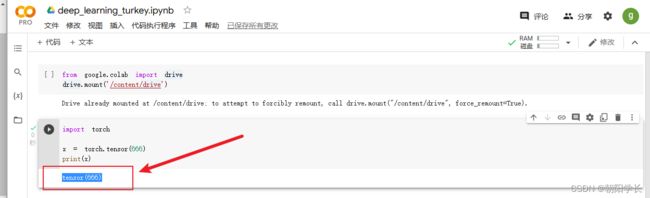
6、size用于返回张量维度大小的方法,未指定维度,则返回保存该维度的int
7、tensor支持下标索引
8、tensor支持切片,注意逗号的用法!

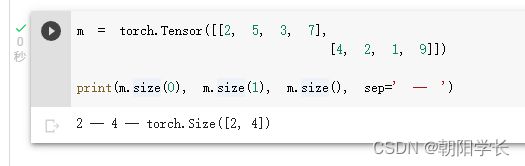
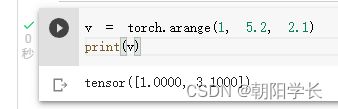
9、arange用于生成[start,end)的1*n张量
10、@符号表示矩阵乘法

11、linspace创建一个指定个数的步长均匀的一维张量

12、cat用于拼接两个tensor

13、获取plot_lib工具函数,构建螺旋型数点
我修改了样本类别数量,改为了4

14、Linear用于构建线性变换,第一个参数为输入样本的大小,第二个参数为输出样本的大小
nn.Linear(D, H)
nn.Linear(H, C) #最后变为想要的种类数
15、构建线性模型并且使用SGD进行梯度下降算法得到的结果图如下,ACCURACY=0.507

16、构建两层神经网络分类并且使用Adam进行梯度下降算法得到的结果图如下,ACCURACY=0.944

问题总结
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
AlexNet相较于LeNet, 网络更深。
AlexNet使用ReLu替换了LeNet的Sigmoid作为激活函数,验证了其效果在较深的网络中超过了Sigmoid,
成功解决了Sigmoid在网络较深时的梯度消失问题。
AlexNet引入了Dropout用于防止过拟合。保证了在训练数据和测试数据的准确率都较高。
2、激活函数有哪些作用?
激活函数最主要的作用就是用来增加非线性因素的.
如果不使用激活函数, 我们每一层的输入只是在上一层的输出做线性变换, 无论神经网络的深度有多深, 输出都是线性组合,
引入非线性因素之后就可以使得神经网络逼近任何非线性函数, 这样神经网络就可以应用到非线性模型中.
3、梯度消失现象是什么?
梯队消失是指随着隐藏层深度的增加, 神经网络的分类准确率反而下降.
在以梯度下降和反向传播训练人工神经网络中, 每次迭代权重的更新会与损失函数的偏导成正比, 但层数增加时最后一层的变化难以传递在前面的层,
前层不变又会导致后层无法更新, 最后导致神经网络失去调整能力, 甚至可能完全无法训练.
4、神经网络是更宽好还是更深好?
当节点数一致的时候, 忽略梯度消失带来的前提下, 神经网络越深越好.
随着深度提升带来的效益也不是线性的, 应该找到效率最好的深度.
5、为什么要使用Softmax?
Softmax的公式表示如下: S i = e z i ∑ j = 1 K e z j , i = 1 , 2 , . . . , K S_i=\frac{e^{z_i}}{\sum_{j=1}^{K}e^{z_j}},i=1,2,...,K Si=∑j=1Kezjezi,i=1,2,...,K
Softmax主要用于深度学习中的多分类, 它的主要作用是将输出层的数值映射成概率, 各项数值概率和为1.
求解概率为e的指数, 可以把输入的负数变为正数, e的函数曲线呈现递增趋势, x轴很小的变化反映到y轴可以看到明显变化, 它可以把差值大的值拉的更大.
6、SGD 和 Adam 哪个更有效?
SGD和Adam都是用于梯度下降的优化算法, SGD没有动量的概念, 它是从样本中随机抽出一组,训练后按梯度更新一次,
然后再抽取一组,再更新一次, 保持一个单一的学习速率. Adam集成了SGDM的一阶动量以及RMSProp的二阶动量, 做到了计算不同参数的自适应学习速率.
在前期Adam的效率更高, 它适用于解决包含很高噪声或稀疏梯度的问题, 超参数可以很直观地解释,并且基本上只需极少量的调参.
SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点.