HDFS java api
一、HDFS 概述
Hadoop 分布式文件系统( HDFS )是指被设计成适合运行在通用硬件(commodity hardware)上的分 布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和 其他的分布式文件系统的区别也是很明显的。 HDFS 是一个高度容错性的系统,适合部署在廉价的机器 上。 HDFS 能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。 HDFS 放宽了一部分POSIX 约束,来实现流式读取文件系统数据的目的。 HDFS 在最开始是作为Apache Nutch搜索引擎项目的基础 架构而开发的。 HDFS 是Apache Hadoop Core项目的一部分。
HDFS 有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。 而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。 HDFS 放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式 访问(streaming access)文件系统中的数据。
HDFS 的优点
- 高容错性 数据保存多个副本 数据丢的失后自动恢复 适合批处理 移动计算而非移动数据
- 数据位置暴露给计算框架 适合大数据处理 GB、TB、甚至 PB 级的数据处理 百万规模以上的文件数据
- 10000+ 的节点 可构建在廉价的机器上 通过多副本存储,提高可靠性 提供了容错和恢复机制
HDFS 的缺点
- 低延迟数据访问处理较弱
- 毫秒级别的访问响应较慢
- 低延迟和高吞吐率的请求处理较弱
- 大量小文件存取处理较弱
- 会占用大量NameNode的内存 寻道时间超过读取时间 不支持并发写入、文件随机修改 一个文件仅有一个写者 仅支持Append写入。
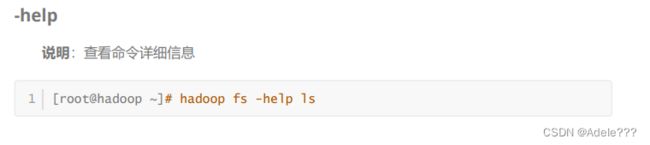
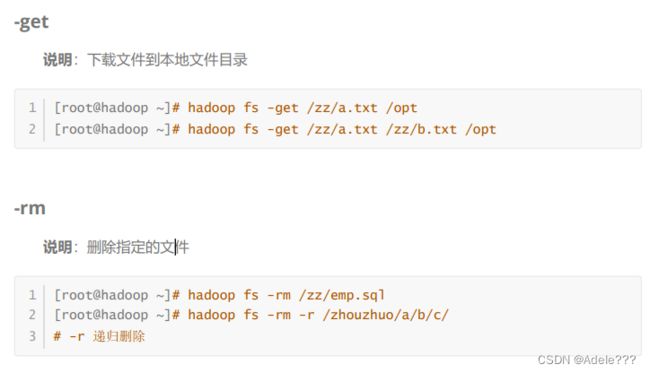
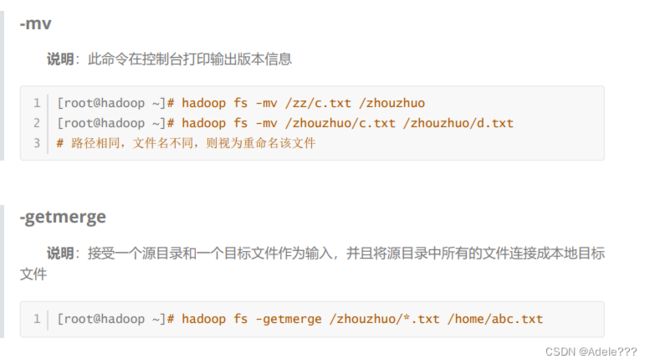
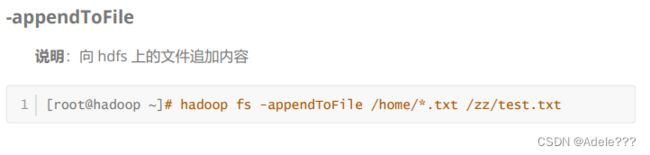
二.HDFS SHELL


三、java api

pom.xml
org.apache.hadoop
hadoop-hdfs
2.9.2
org.apache.hadoop
hadoop-client
2.9.2
org.apache.hadoop
hadoop-common
2.9.2
API
package com.iss.cloud.disk.configure;
import org.apache.hadoop.fs.FileSystem;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Lazy;
import java.net.URI;
@Configuration
public class HDFSConfiguration {
@Value("${hadoop.hdfs.uri}")
private String hdfs_uri;
/**
* 获取 HDFS 文件系统对象
*/
@Bean
public FileSystem getFileSystem() {
System.setProperty("HADOOP_USER_NAME", "root");
FileSystem fs = null;
try {
fs = FileSystem.get(URI.create(hdfs_uri), new
org.apache.hadoop.conf.Configuration());
} catch (Exception e) {
System.out.println(e.getMessage());
}
return fs;
}
}
package com.iss.cloud.disk.service.impl;
import com.iss.cloud.disk.service.HDFSService;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
@Service
public class HDFSServiceImpl implements HDFSService {
@Autowired
private FileSystem fileSystem;
/**
* 创建文件夹
*
* @param path /zz/a/b/c
* @return
*/
@Override
public boolean mkdir(String path) {
boolean flag = false;
try {
flag = this.fileSystem.mkdirs(new Path(path));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 创建文件
*
* @param path = currentPath + filename
*/
@Override
public boolean upload(String path, InputStream input) {
boolean flag = false;
FSDataOutputStream fos = null;
try {
fos = this.fileSystem.create(new Path(path));
byte[] buffer = new byte[1024];
int len = 0;
while ((len = input.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
IOUtils.closeStream(fos);
flag = true;
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 删除文件夹 or 文件
*/
@Override
public boolean delete(String filePath) {
boolean flag = false;
try {
flag = this.fileSystem.delete(new Path(filePath), true);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 重命名文件夹 or 文件
*/
@Override
public boolean rename(String oldPath, String newPath) {
boolean flag = false;
try {
flag = this.fileSystem.rename(new Path(oldPath), new
Path(newPath));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 文件复制
*/
@Override
public boolean copy(String src, String dst) {
boolean flag = false;
try {
flag = this.upload(src,this.download(dst));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 文件是否存在
*
* @param path = currentPath + filename
*/
@Override
public boolean exists(String path) {
boolean flag = false;
try {
flag = this.fileSystem.exists(new Path(path));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return flag;
}
/**
* 下载
*/
@Override
public InputStream download(String filePath) {
FSDataInputStream fis = null;
try {
fis = this.fileSystem.open(new Path(filePath));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return fis;
}
/**
* 遍历指定路径下的文件
*/
@Override
public List list(String path) {
List list = new ArrayList();
try {
// 方式一
RemoteIterator iterator =
this.fileSystem.listFiles(new Path(path), true);
while (iterator.hasNext()) {
LocatedFileStatus ls = iterator.next();
list.add(ls.getPath().getName());
}
// 方式二
FileStatus[] fileStatus = this.fileSystem.listStatus(new
Path(path));
for (int i = 0; i < fileStatus.length; i++) {
System.out.println(fileStatus[i].getPath().toString());
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
return list;
}
/**
* 查找某个文件在集群中的位置
*/
@Override
public void getFileLocation(String fileName) {
try {
FileStatus fileStatus = this.fileSystem.getFileStatus(new
Path(fileName));
BlockLocation[] blockLocation =
this.fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for (int i = 0; i < blockLocation.length; i++) {
String[] hosts = blockLocation[i].getHosts();
System.out.println("block_" + i + "_location:" + hosts[0]);
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
} test
package com.iss.hadoop.controller;
import com.iss.hadoop.common.ApiResult;
import com.iss.hadoop.hdfs.HDFSService;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.http.HttpServletRequest;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLEncoder;
@RestController
@RequestMapping("/hdfs")
public class HDFSController {
@Autowired
private HDFSService hdfsService;
// http://localhost:8080/hdfs/mkdirs?dirs=/hdfs/a/b/c/
@GetMapping("/mkdirs")
public ApiResult mkdirs(@RequestParam("dirs") String dirs) {
return this.hdfsService.mkdirs(dirs);
}
// http://localhost:8080/hdfs/upload
@PostMapping("/upload")
public ApiResult upload(@RequestParam("file") MultipartFile file) {
ApiResult apiResult = null;
try {
apiResult = this.hdfsService.upload(file.getOriginalFilename(),
file.getInputStream());
} catch (IOException e) {
e.printStackTrace();
apiResult = ApiResult.failure("Operate Failure !");
}
return apiResult;
}
// http://localhost:8080/hdfs/delete?fileName=
@GetMapping("/delete")
public ApiResult delete(@RequestParam("fileName") String fileName) {
return this.hdfsService.delete(fileName);
}
// http://localhost:8080/hdfs/rename?oldStr= &newStr=
@GetMapping("/rename")
public ApiResult rename(@RequestParam("oldStr") String oldStr,
@RequestParam("newStr") String newStr) {
return this.hdfsService.rename(oldStr, newStr);
}
// http://localhost:8080/hdfs/exists?fileName=
@GetMapping("/exists")
public ApiResult exists(@RequestParam("fileName") String fileName) {
return this.hdfsService.exists(fileName);
}
// http://localhost:8080/hdfs/download?fileName=
@GetMapping(value = "/download")
public ResponseEntity download(@RequestParam("fileName") String
fileName)
throws Exception {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
headers.setContentDispositionFormData("attachment",
URLEncoder.encode(fileName, "UTF-8"));
InputStream input = this.hdfsService.download(fileName);
return new ResponseEntity(IOUtils.toByteArray(input),
headers, HttpStatus.OK);
}
// http://localhost:8080/hdfs/list?path=
@GetMapping("/list")
public ApiResult list(@RequestParam("path") String path) {
return this.hdfsService.list(path);
}
}