机器学习笔记(一)
目录
Introduction | Welcome
Introduction | What is machine learning
Machine Learning definition 机器学习的定义
Introduction | Supervised Learning 监督学习
Supervised Learning definition 监督学习定义
回归
分类
Introduction | Welcome
实际上机器学习是从AI 即人工智能发展出来的一个领域。我们想建造智能机器,然后发现我们可以通过编程,让机器做一些基本的事情,比如如何找到从A到B的最短路径。但大多数情况下,我们不知道如何编写AI程序来做更有趣的事情,如网页搜索、相片标记、反垃圾邮件。人们认识到做到这些事情唯一的方法,就是使机器学习如何自己去做。
因此,机器学习是为计算机开发的一项新功能,如今它涉及工业和基础科学中的许多领域。机器学习的范围非常广泛,包括自主机器人,计算生物学...
Machine Learning
介绍:
- Grew out of work in AI #在AI领域运作
- New capability for computers #计算机开发的一项新功能 capability-功能
Examples:
- Database mining #数据挖掘
- Applications can't program by hand #我们无法手动编写的程序
- Self-customizing programs #私人订制程序
- Understanding human learning(brain,real AI) #理解人类的学习过程和大脑
Database mining, 数据挖掘领域
Large datasets from growth of automation/web.
#机器学习如此普遍的原因之一,就是网络和自动化技术的发展。这意味着我们拥有了前所未有的大量的数据集。
例如:
web click data,网络点击数据, 或者说点击流数据,可以通过收集这些数据,并试图采用机器学习算法来挖掘数据,更好地理解用户且能更好的为用户服务。
medical records,医疗记录,现在我们都有了电子医疗记录,假如我们能将医疗记录转换为医疗知识,也许就能更好地理解疾病。
biology,计算生物学,因为自动化,生物学家收集了关于基因序列,DNA序列等的大量数据,机器学习算法让我们更好地理解人类基因组....
engineering,工程学所有领域,我们也可以设法采用学习算法,来理解越来越大的数据集。
Applications can't program by hand 我们无法手动编写的程序
例如:
Autonomous helicopter,自动直升机飞行领域。我们不知道如何编写程序使直升机自己飞行,唯一可行的就是让计算机自己学习驾驶直升机。
handwriting recognition,手写识别。
most of Natural Language Processing,自然语言处理/Computer Vision,计算机视觉。可利用机器学习让AI理解语言或图像。
Self-customizing programs 私人订制程序
例如:
Amazon,Netflix product recommendations...当你使用这些软件时,它就会推荐电影、产品或音乐给你,且每个用户喜好不一样,让她自我学习,并根据你的喜好为你量身定制推荐。
Introduction | What is machine learning
Machine Learning definition 机器学习的定义
- Arthur Samuel:Field of study that gives computers the ability to learn without being explicitly programmed.(他将机器学习定义为在没有明确设置的情况下,使计算机具有学习能力的研究领域;explicitly—明确地)
- Tom Mitchell:A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. 【计算机程序从经验E中学习,解决某一任务T,进行某一性能度量P(我的理解是机器学习算法后操作某一任务所表现出的性能好坏),通过P测定在T上的表现因经验E而提高(我的理解是E-经验越多,计算机学习的越好,完成任务的变现就越好)】
Introduction | Supervised Learning 监督学习
目前有各种不同类型的学习算法,最主要的两类是监督学习和无监督学习。
- 监督学习和无监督学习很好区分:是否有监督(supervised),就看输入数据是否有标签(label),输入数据有标签,则为有监督学习,没标签则为无监督学习。举个例子:你小时候见到了狗和猫两种动物,有人告诉你这个样子的是狗、那个样子的是猫,你学会了辨别,这是监督学习;你小时候见到了狗和猫两种动物,没人告诉你哪个是狗、哪个是猫,但你根据他们样子、体型等特征的不同鉴别出这是两种不同的生物,并对特征归类,这是无监督学习。

Supervised Learning definition 监督学习的定义
利用一组已知类别的样本调整分类器的参数 ,使其达到所要求性能的过程。监督学习是从标记的训练数据来推断一个功能的机器学习任务。
我的理解:我们给算法一个数据集,其中包含了“正确答案”,比如我们有一个房价数据集,在这个数据集中的每个样本,我们都给出正确的价格(即房子的实际卖价),那么根据样本的数据集进行拟合就可以得到一条直线或曲线,现在我们为一个已知大小的房子给出估价,不同的函数我们就能得到不同的结果,算法的目的就是给出更多的正确答案。但无论选择哪个函数,都不能让这套房子的价格升高。
理解监督学习,首先要理解「标签」与「特征」。例如我们希望机器能判断一颗樱桃是酸还是甜。如果颜色鲜红、果实较小的樱桃是酸的,颜色紫红、果实较大的樱桃是甜的,这里的「酸」和「甜」就属于标签,「颜色」和「果实大小」则属于特征。监督学习,就是让机器掌握「标签」与「特征」之间的关系,以便预测新的樱桃是「甜」还是「酸」。
一个训练得较好的模型便能够较为准确的判断新的樱桃是酸是甜,对数据进行标注是监督学习的核心前提。
训练过程
要想让机器学会判断樱桃是酸还是甜,我们需要先准备几组原始数据。
- 训练集:一组打上标签的樱桃样本数据,用来让机器学习,以得到若干个模型;
- 验证集:另一组打上标签的樱桃样本数据,通常比训练集的数据量要少。我们用这组数据来验证训练出的几个模型,是否能够准确判断樱桃的酸甜,并保留其中判断最准确的模型;
- 测试集:一些未打上标签的樱桃样本数据,用来验证这个模型是否可以稳定且准确地判断樱桃的酸甜。例如,当我们给到这个最优模型一组车厘子樱桃(颜色紫红,果实较大)的数据,机器会告诉我们,它属于「甜」的樱桃。
我们可以根据标签是连续值还是离散值,将监督学习问题分为分类问题和回归问题,其中分类问题的标签是离散值,回归问题的标签是连续值。
回归
在前面的预测房价的例子中,房子的价格就属于标签,房子的面积就属于特征。监督学习让机器掌握标签与特征之间的关系,以便预测别的房子的价格。
它也被称为回归问题,预测出一个连续的数值输出。
分类
它也是一个分类问题,分类是指,我们设法预测一个离散值输出。
例:
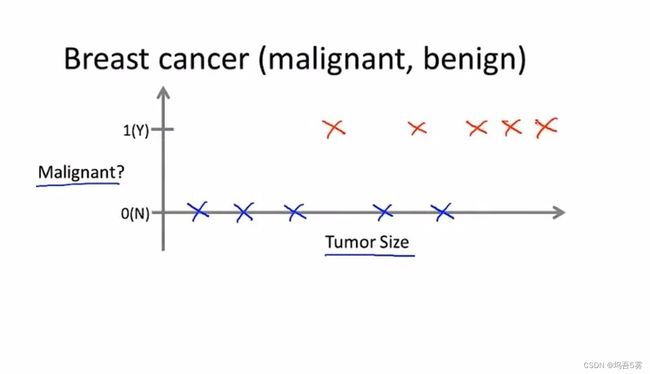
假如我们观察医疗记录,并且设法预测乳腺癌是恶性还是良性。假设某人发现了一个乳腺肿瘤,我们通过收集的数据集,横轴设定为肿瘤的尺寸,纵轴即0或1,代表良性或恶性。
如上图所示 ,假设现在有一个已知尺寸的乳腺肿瘤,机器学习的问题就是,能否估计出肿瘤是良性的还是恶性的概率。(实际例子中可能会不止两个离散值,肿瘤也分很多种,不止有良性和恶性两种;也不会只有肿瘤尺寸这一个特征属性)
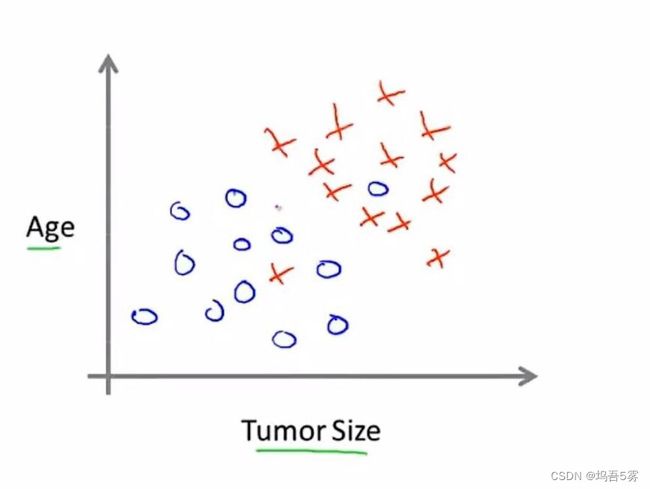
假设现在有两个特征,肿瘤尺寸和病人年龄,有这样一组数据集:
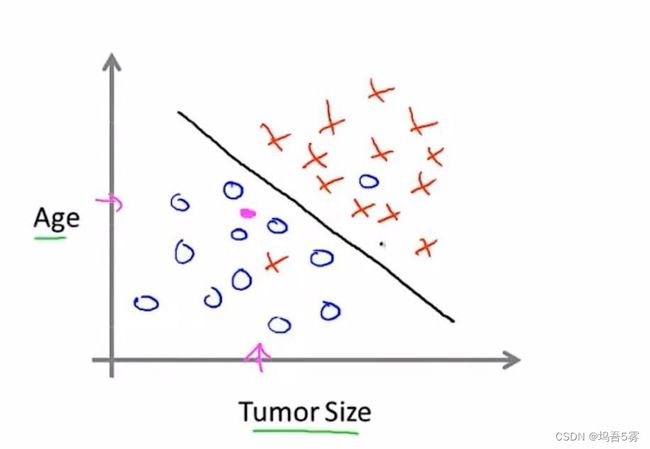
现在已知一个病人的年龄和肿瘤尺寸,学习算法能做的就是在数据上画一条直线,设法将恶性肿瘤和良性肿瘤分开。
我们就可以通过这个预测这位病人的肿瘤处于良性区域的可能性比恶性的大。
算法可以用无穷多的属性或特征来做预测,但我们不可能在计算机中存储无穷多数量的事物,因为计算机内存会溢出。(...这地方有点没懂当想用无穷多特征是该怎么做先不写了)
分类方法的定义:分类分析的是根据已知类别的训练集数据,建立分类模型,并利用该分类模型预测未知类别数据对象所属的类别。
现实应用案例:
- 行为分析
- 物品识别、图像检测
- 电子邮件的分类(垃圾邮件和非垃圾邮件等)
- 新闻稿件的分类、手写数字识别、个性化营销中的客户群分类、图像/视频的场景分类等
分类器
- 分类的实现方法是创建一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。
- 创建分类的过程中与机器学习的一般过程一致。
分类器的构建
参考学习:
- https://www.zhihu.com/question/304499904/answer/551154375(作者:KnowingAI知智)
- b站吴恩达机器学习系列课程
- 机器学习 · 监督学习篇 I 监督学习是什么 - 知乎 (zhihu.com)
- 离散量和连续量的理解:数学与生活 -1离散量与连续量 - 知乎 (zhihu.com)
感悟:学习视频看的是吴恩达的课程,因为是全英文授课,每个up主的翻译又有点不同,翻译的也不算特别准确,有的概念就是只意会了写不出来,感觉这门课算是这学期最困难的一门了,多花时间吧。