qiuzitao深度学习之PyTorch实战(十三)
史上最简单、实际、通俗易懂的PyTorch实战系列教程!(新手友好、小白请进、建议收藏)
GAN对抗生成网络
一、GAN对抗生成网络通俗介绍
通俗来说,对抗生成网络就是你给计算机一些地球人的人脸数据去训练,然后它就可以生成一些新的地球人的人脸图片。
它也可以对图像进行超分辨率重构,把模糊的图片变清晰,你只需要给它模糊图片的数据和清晰图片的数据,在它遇到新的需要处理的模糊的图片时,它就可以生成清晰的图片。

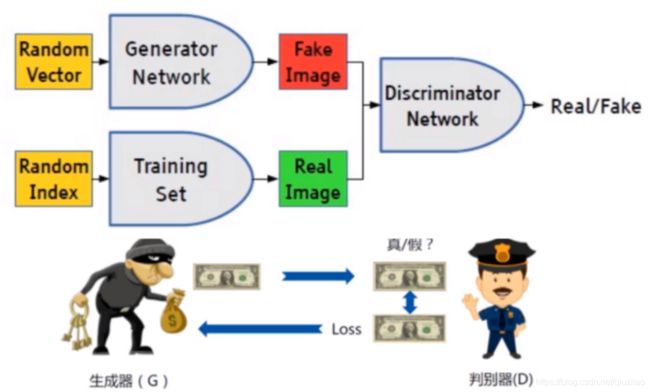
何为对抗?如下图。
例如真伪钞票,贼人要造接近真钞的伪钞,我们把它比作生成器;警察要帮助银行辨别这些伪钞,我们把它比作判别器。
可想而知,生成器要越真越好,越接近真的钞票越好,从而可以骗过判别器,但是判别器也要越来越厉害,像孙悟空在炼丹炉里越炼越火眼金睛,才能分辨出真伪钞。把它们放在一起,所以这就矛盾了,互相对抗。
生成器就是要生成 Fake Image(假的图片),判别器就是把 Fake Image 和 Real Image 进行判别。说到底判别器可以看做一个二分类网络。要生成什么由 loss 损失函数决定,loss损失函数决定了整个网络的走向。
二、GAN对抗生成网络实战
数据集和代码的百度云下载链接:
百度云链接:pan.baidu.com/s/1yv0a687D1yixxozwlCKLyg
提取码:rhwk
这里我们选择MNIST数据集,因为它的输入比较小,28×28×1,也方便我们个人电脑无论有没有GPU也可以在CPU跑。
1、BCEloss
我们先来看下GAN对抗生成网络最重要的损失函数。
import torch
from torch import autograd
input = autograd.Variable(torch.tensor([[ 1.9072, 1.1079, 1.4906],
[-0.6584, -0.0512, 0.7608],
[-0.0614, 0.6583, 0.1095]]), requires_grad=True)
print(input)
print('-'*100)
from torch import nn
m = nn.Sigmoid()
print(m(input))
print('-'*100)
target = torch.FloatTensor([[0, 1, 1], [1, 1, 1], [0, 0, 0]])
print(target)
print('-'*100)
import math
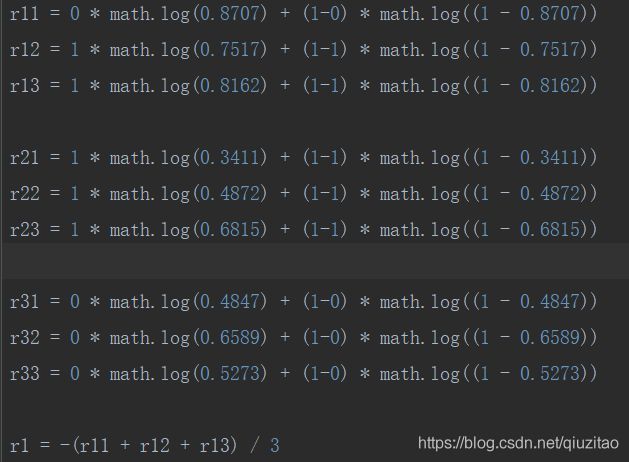
r11 = 0 * math.log(0.8707) + (1-0) * math.log((1 - 0.8707))
r12 = 1 * math.log(0.7517) + (1-1) * math.log((1 - 0.7517))
r13 = 1 * math.log(0.8162) + (1-1) * math.log((1 - 0.8162))
r21 = 1 * math.log(0.3411) + (1-1) * math.log((1 - 0.3411))
r22 = 1 * math.log(0.4872) + (1-1) * math.log((1 - 0.4872))
r23 = 1 * math.log(0.6815) + (1-1) * math.log((1 - 0.6815))
r31 = 0 * math.log(0.4847) + (1-0) * math.log((1 - 0.4847))
r32 = 0 * math.log(0.6589) + (1-0) * math.log((1 - 0.6589))
r33 = 0 * math.log(0.5273) + (1-0) * math.log((1 - 0.5273))
r1 = -(r11 + r12 + r13) / 3
#0.8447112733378236
r2 = -(r21 + r22 + r23) / 3
#0.7260397266631787
r3 = -(r31 + r32 + r33) / 3
#0.8292933181294807
bceloss = (r1 + r2 + r3) / 3
print(bceloss)
print('-'*100)
loss = nn.BCELoss()
print(loss(m(input), target))
print('-'*100)
loss = nn.BCEWithLogitsLoss()
print(loss(input, target))
其实 BCEloss 有点类似交叉熵损失函数,所有的预测结果映示到 0 - 1 范围之中。

t[i] 概率值 × 对数log(o[i]) + (1 - 概率值t[i] × 对数log(1-o[i]))
t[i]概率值也就是我们的target值,0就是0,1就是1,这样去算的。
loss = nn.BCEloss() #这个函数没有帮你做映示变换,你要自己做
loss = nn.BCEWithLogitsLoss() #这个就有帮你做了Sigmoid。
2、生成器、判别器
生成器(G网络):
generator = Generator()
输入是 28 × 28 × 1 = 784 个像素点
这里我们用全连接层来做。
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
判别器(D网络):
discriminator = Discriminator()
来判别一张图像是真的还是假的,所以输入也是784。
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
3、数据读取模块
读数据:
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
选择优化器:
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
生成器训练模块:
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
valid 就是真数据,标签就是1,fake 得到的假数据打上的标签就是0。
real_imgs = Variable(imgs.type(Tensor))
转换得到的输入数据为tensor格式。
optimizer_G.zero_grad()
梯度清零。
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
随机初始化一个batch的向量。
gen_imgs = generator(z)
得到一个输出的所有结果,把100维的随机向量生成一个实际的784维向量。
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
生成器的loss,希望越真越好,传入的 valid 是1。
g_loss.backward()
optimizer_G.step()
更新梯度,梯度清零。
判别器训练模块:
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
判别器有两个输入,一个是生成的伪数据的输入,一个是真实的标签的输入,希望判别器能把真的判别成1,假的判别成0。
然后就更新,打印epoch结果,用pytorch自带的函数保存训练结果。
我们可以看到上面有100个epoch后得到的结果,基于最简单的方法,最基础的全连接层去跑的。