递归和动态规划
文章目录
-
- 斐波那契数列问题的递归和动态规划
- 矩阵的最小路径和
- 换钱的最少货币数
- 机器人达到指定位置方法数
- 换钱的方法数
- 打气球的最大分数
- 最长递增子序列
- 信封嵌套问题
- 汉诺塔问题
- 最长公共子序列问题
- 最长公共子串问题
- 子数组异或和为 0 的最多划分
- 最小编辑代价
- 字符串的交错组成
- 龙与地下城游戏问题
- 数字字符串转换为字母组合的种数
- 表达式得到期望结果的组成种数
- 排成一条线的纸牌博弈问题
- 跳跃游戏
- 数组中的最长连续序列
- N 皇后问题
斐波那契数列问题的递归和动态规划
【题目】
给定整数 N,返回斐波那契数列的第 N 项。
补充问题 1:给定整数 N,代表台阶数,一次可以跨 2 个或者 1 个台阶,返回有多少种走法。
例如:
N=3,可以三次都跨 1 个台阶;也可以先跨 2 个台阶,再跨 1 个台阶;还可以先跨 1 个台阶,再跨 2 个台阶。所以有三种走法,返回 3。
补充问题 2:假设农场中成熟的母牛每年只会生 1 头小母牛,并且永远不会死。第一年农场有 1 只成熟的母牛,从第二年开始,母牛开始生小母牛。每只小母牛 3 年之后成熟又可以生小母牛。给定整数 N,求出 N 年后牛的数量。
例如:
N=6,第 1 年 1 头成熟母牛记为 a;第 2 年 a 生了新的小母牛,记为 b,总牛数为 2;第 3 年 a 生了新的小母牛,记为 c,总牛数为 3;第 4 年 a 生了新的小母牛,记为 d,总牛数为 4。第 5 年 b 成熟了,a 和 b 分别生了新的小母牛,总牛数为 6;第 6 年 c 也成熟了,a、b 和 c 分别生了新的小母牛,总牛数为 9,返回 9。
【解答】
-
矩阵乘法求递推(动态规划)
对于原问题,斐波那契数列为 1,1,2,3,5,8,…,也就是除第 1 项和第 2 项为 1 以外,对于第 N 项,有 F(N)=F(N-1)+F(N-2),于是可以很轻松地写出暴力递归的代码。
斐波那契数列可以从左到右依次求出每一项的值,那么通过顺序计算也可以求到第 N 项。
下面介绍一种不同的方法。
如果递归式严格遵循 F(N)=F(N-1)+F(N-2),对于求第 N 项的值,可以用矩阵乘法的方法。F(n)=F(n-1)+F(n-2)是一个二阶递推数列,状态矩阵为 2×2 的矩阵:
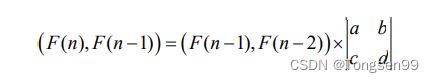
把斐波那契数列的前 4 项 F(1)=1,F(2)=1,F(3)=2,F(4)=3 代入,可以求出状态矩阵:

求矩阵之后,当 n>2 时,原来的公式可化简为:

所以,求斐波那契数列第 N 项的问题就变成了如何用最快的方法求一个矩阵 N 次方的问题。为了表述方便,现在用求一个整数 N 次方的例子来说明,因为只要理解了如何求整数 N 次方的问题,对于求矩阵 N 次方的问题是同理的,区别是矩阵乘法和整数乘法在细节上有些不一样,但对于怎么乘更快,两者的道理相同。
假设一个整数是 10,如何最快地求解 10 的 75 次方。
1.75 的二进制数形式为 1001011。
2.10 的 75 次方= 1 0 64 × 1 0 8 × 1 0 2 × 1 0 1 10^{64}×10^8 ×10^2 ×10^1 1064×108×102×101 。 在这个过程中,我们先求出 1 0 1 10^1 101 ,然后根据 1 0 1 10^1 101 求出 1 0 2 10^2 102 ,再根据 1 0 2 10^2 102 求出 1 0 4 10^4 104 ,……,最后根据 1 0 32 10^{32} 1032 求出 1 0 64 10^{64} 1064,即 75 的二进制数形式总共有多少位,我们就使用了几次乘法。
3.在步骤 2 进行的过程中,把应该累乘的值相乘即可,比如 1 0 64 10^{64} 1064、 1 0 8 10^8 108 、 1 0 2 10^2 102 、 1 0 1 10^1 101 应该累乘,因为 64、8、2、1 对应到 75 的二进制数中,相应的位上是 1;而 1 0 32 10^{32} 1032、 1 0 16 10^{16} 1016、 1 0 4 10^4 104 不应该累乘,因为 32、16、4 对应到 75 的二进制数中,相应的位上是 0。 对矩阵来说同理。
【代码】
#include 补充问题 1:如果台阶只有 1 级,方法只有 1 种。如果台阶有 2 级,方法有 2 种。如果台 阶有 N 级,最后跳上第 N 级的情况,要么是从 N-2 级台阶直接跨 2 级台阶,要么是从 N-1 级台阶跨 1 级台阶,所以台阶有 N 级的方法数为跨到 N-2 级台阶的方法数加上跨到 N-1 级台阶的方法数,即 S(N)=S(N-1)+S(N-2),初始项 S(1)=1,S(2)=2。所以,类似斐波那契数列,唯一的不同就是初始项不同。
补充问题 2:所有的牛都不会死,所以第 N-1 年的牛会毫无损失地活到第 N 年。同时所有 成熟的牛都会生 1 头新的牛,那么成熟牛的数量如何估计?就是第 N-3 年的所有牛,到第 N 年肯定都是成熟的牛,其间出生的牛肯定都没有成熟。所以 C(n)=C(n-1)+C(n-3),初始项为 C(1)=1,C(2)=2,C(3)=3。这个和斐波那契数列又十分类似,只不过 C(n)依赖 C(n-1)和 C(n-3)的值,而斐波那契数列 F(n)依赖 F(n-1)和 F(n-2)的值。而且C(n)=C(n-1)+C(n-3)是一个三阶递推数列,状态矩阵为 3×3 的矩阵:

附:如果递归式严格符合 F(n)=a×F(n-1)+b×F(n-2)+…+k×F(n-i),那么它就是一个 i 阶的递推式,必然有与 i×i 的状态矩阵有关的矩阵乘法的表达。一律可以用加速矩阵乘法的动态规划解决。
矩阵的最小路径和
【题目】
给定一个矩阵 m,从左上角开始每次只能向右或者向下走,最后到达右下角的位置,路径 上所有的数字累加起来就是路径和,返回所有的路径中最小的路径和。
例如:
如果给定的 m 如下:
1 3 5 9
8 1 3 4
5 0 6 1
8 8 4 0
路径 1,3,1,0,6,1,0 是所有路径中路径和最小的,所以返回 12。
【解答】
-
动态规划+空间压缩
假设矩阵 m 的大小为 M×N,行数为 M,列数为 N。先生成大小和 m 一样的矩阵 dp,dp[i] [j]的值表示从左上角(即(0,0))位置走到(i,j)位置的最小路径和。对 m 的第一行的所有位置来说,即(0,j)(0≤j
1 4 9 18
9
14
22
除第一行和第一列的其他位置(i,j),都有左边位置(i-1,j)和上边位置(i,j-1)。从(0,0)到(i,j)的路径必然经过位置(i-1,j)或位置(i,j-1),所以,dp[i] [j]=min{dp[i-1] [j],dp[i] [j-1]}+m[i] [j],含义是比较从(0,0)位置开始,经过(i-1,j)位置最终到达(i,j)的最小路径和经过(i,j-1)位置最终到达(i,j)的最小路径之间,哪条路径的路径和更小。那么更小的路径和就是 dp[i] [j]的值。以题目的例子来说,最终生成的 dp 矩阵如下:
1 4 9 18
9 5 8 12
14 5 11 12
22 13 15 12
除第一行和第一列外,每一个位置都考虑从左边到达自己的路径和更小还是从上边达到自己的路径和更小。最右下角的值就是整个问题的答案。
这里可以对空间进行优化。
矩阵中一共有 M×N 个位置,每个位置都计算一次从(0,0)位置达到自己的最小路径和,计算的时候只是比较上边位置的最小路径和与左边位置的最小路径和哪个更小。
空间压缩的方法为不使用大小为 M×N 的 dp 矩阵,而仅仅使用大小为 min{M,N}的 arr 数组。具体过程如下(以题目的例子来举例说明)。
1.生成长度为 4 的数组 arr,初始时 arr=[0,0,0,0],我们知道从(0,0)位置到达 m 中第一行的每个位置,最小路径和就是从(0,0)位置的值开始依次累加的结果,所以依次把 arr 设置为 arr=[1,4,9,18],此时 arr[j]的值代表从(0,0)位置达到(0,j)位置的最小路径和。
2.步骤 1 中 arr[j]的值代表从(0,0)位置达到(0,j)位置的最小路径和,在这一步中想把arr[j]的值更新成从(0,0)位置达到(1,j)位置的最小路径和。首先来看 arr[0],更新之前 arr[0]的值代表(0,0)位置到达(0,0)位置的最小路径和(dp[0] [0]),如果想把 arr[0]更新成从(0,0)位置达到(1,0)位置的最小路径和(dp[1] [0]),令 arr[0]=arr[0]+m[1] [0]=9 即可。然后来看 arr[1],更新之前 arr[1]的值代表(0,0)位置到达(0,1)位置的最小路径和(dp[0] [1]),更新之后想让arr[1]代表(0,0)位置到达(1,1)位置的最小路径和(dp[1] [1])。根据动态规划的求解过程,到达(1,1)位置有两种选择,一种是从(1,0)位置到达(1,1)位置(dp[1] [0]+m[1] [1]),另一种是从(0,1)位置到达(1,1)位置(dp[0] [1]+m[1] [1])),应该选择路径和最小的那个。此时 arr[0]的值已经更新成 dp[1] [0],arr[1]目前还没有更新,所以,arr[1]还是 dp[0] [1],则arr[1]=min{arr[0],arr[1]}+m[1] [1]=5。更新之后,arr[1]的值变为 dp[1] [1]的值。同理,arr[2]=min{arr[1],arr[2]}+m[1] [2],……最终 arr 可以更新成[9,5,8,12]。
3.重复步骤 2 的更新过程,一直到 arr 彻底变成 dp 矩阵的最后一行。整个过程其实就是不断滚动更新 arr 数组,让 arr 依次变成 dp 矩阵每一行的值,最终变成 dp 矩阵最后一行的值。
本题的例子是矩阵 m 的行数等于列数,如果给定的矩阵列数小于行数(N
【代码】
#include 附:本题压缩空间的方法几乎可以应用到所有需要二维动态规划表的题目中,通过一个数组滚动更新的方式无疑节省了大量的空间。但是空间压缩的方法是有局限性的,本题如果改成“打印具有最小路径和的路径”,那么就不能使用空间压缩的方法。如果类似本题这种需要二维表的动态规划题目,最终目的是想求最优解的具体路径,往往需要完整的动态规划表,但如果只是想求最优解的值,则可以使用空间压缩的方法。因为空间压缩的方法是滚动更新的,会覆盖之前求解的值,让求解轨迹变得不可回溯。
换钱的最少货币数
【题目】
给定数组 arr,arr 中所有的值都为正数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个整数 aim,代表要找的钱数,求组成 aim 的最少货币数。
例如:
arr=[5,2,3],aim=20。4 张 5 元可以组成 20 元,其他的找钱方案都要使用更多张的货币,所以返回 4。
arr=[5,2,3],aim=0。不用任何货币就可以组成 0 元,返回 0。
arr=[3,5],aim=2。根本无法组成 2 元,钱不能找开的情况下默认返回-1。
【解答】
-
法一:暴力递归
每一种面值都尝试不同的张数,尝试是从哪里开始的?是从 arr[0]开始依次往右考虑所有面值。
-
法二:动态规划(可空间压缩)
前提:尝试过程是无后效性的。上面的尝试其实明显是无后效性的,但是为了方便理解,我们还是举个例子,arr = {5,2,3,1},aim=100,那么 process(arr,0,100)的返回值就是最终答案。如果使用 2 张 5 元,0 张 2 元,那么后续的过程是 process(arr,2,90);但如果使用 0 张 5 元,5 张 2元,那么后续的过程还是 process(arr,2,90)。这个状态的返回值肯定是一样的,说明一个状态最终的返回值与怎么达到这个状态的过程无关。
1)可变参数 i 和 rest 一旦确定,返回值就确定了。
2)如果可变参数 i 和 rest 组合的所有情况组成一张二维表,这张表一定可以装下所有的返回值。i 的含义是 arr 中的位置,又因为 process 中允许 i 来到 arr 的终止位置,所以 i 的范围是[0,N]。rest 代表剩余的钱数,剩余的钱不可能大于 aim,所以 rest 的范围是[0,aim]。所以这张二维表是一个 N+1 行 aim+1 列的表,记为 dp[][]。
3)最终状态是 process(arr,0,aim),也就是 dp[0] [aim]的值,位于 dp 表 0 行最后一列。
4)填写初始的位置,根据 process(arr,i,rest)函数的 base case:
if (i == arr.size()) { return rest == 0 ? 0 : -1; }i=arr.size(),就是 dp 表中最后一行 dp[N] […],这最后一行只有 dp[N] [0]是 0,其他位置都是-1。
5)base case 之外的情况都是普遍位置,在 process (arr,i,rest)函数中如下:
// 最少张数,初始时为-1,因为还没找到有效解 int res = -1; // 依次尝试使用当前面值(arr[i])0 张、1 张、k 张,但不能超过 rest int next = 0; for (int k = 0; k * arr[i] <= rest; k++) { // 使用了 k 张 arr[i],剩下的钱为 rest - k * arr[i] // 交给剩下的面值去搞定(arr[i+1..N-1]) next = process(arr, i + 1, rest - k * arr[i]); if (next != -1) { res = res == -1 ? next + k : min(res, next + k); } } return res;process (arr,i,rest)的返回值就是 dp[i] [rest],这个位置依赖哪些位置呢?请看下表。
…… …… …… …… …… …… …… i行 …… dp[i] [rest-2*arr[i]] …… dp[i] [rest-arr[i]] …… dp[i] [rest] i+1 行 …… dp[i+1] [rest-2*arr[i]] …… dp[i+1] [rest-1*arr[i]] …… dp[i+1] [rest-0*arr[i]] 表中右上角的位置就是 dp[i] [rest],根据 process (arr,i,rest)函数可知,dp[i] [rest]的值就是以下这些值中最小的一个:dp[i+1] [rest-0 * arr[i]] + 0、dp[i+1] [rest-1 * arr[i]] + 1、dp[i+1] [rest-2 * arr[i]] + 2、…dp[i+1] [rest-k * arr[i]] + k、……直到越界。在表中已经标出了这些位置。也就是说,要想得到dp[i] [rest]的值,必须枚举 i+1 行的这些值。
但其实这个枚举过程是可以优化的。请看表中 dp[i] [rest-arr[i]]这个位置。如果在求 dp[i] [rest]之前,dp[i] [rest-arr[i]]已经求过了。那么我们看看 dp[i] [rest-arr[i]]是怎么求出来的,同样,根据 process (arr,i,rest)函数可知,dp[i] [rest-arr[i]]的值就是以下这些值中最小的一个:dp[i+1] [rest-arr[i]] + 0、dp[i+1] [rest-2 * arr[i]] + 1、… dp[i+1] [rest-k * arr[i]] + k - 1、……直到越界。可以对比一下 dp[i] [rest]和 dp[i] [rest-arr[i]]各自依赖的位置就可以得到,dp[i] [rest] = min{ dp[i] [rest-arr[i]] + 1, dp[i+1] [rest] }。也就是说,求 dp[i] [rest]只依赖下面的一个位置(dp[i+1] [rest])和左边的一个位置(dp[i] [rest-arr[i]] + 1)即可。
现在 dp 表中最后一排的值已经有了,既然剩下的位置都只依赖下面和左边的位置,那么只要从左往右求出倒数第二排、从左往右求出倒数第三排……从左往右求出第一排即可。
6)最后返回 dp[0] [aim]位置的值就是答案。
【代码】
- 法一
#include - 法二
#include 机器人达到指定位置方法数
【题目】
假设有排成一行的 N 个位置,记为 1~N,N 一定大于或等于 2。开始时机器人在其中的 M 位置上(M 一定是 1~N 中的一个),机器人可以往左走或者往右走,如果机器人来到 1 位置,那么下一步只能往右来到 2 位置;如果机器人来到 N 位置,那么下一步只能往左来到 N-1 位置。规定机器人必须走 K 步,最终能来到 P 位置(P 也一定是 1~N 中的一个)的方法有多少种。给 定四个参数 N、M、K、P,返回方法数。
例如:
N=5,M=2,K=3,P=3
上面的参数代表所有位置为 1 2 3 4 5。机器人最开始在 2 位置上,必须经过 3 步,最后到达 3 位置。走的方法只有如下 3 种:
1)从 2 到 1,从 1 到 2,从 2 到 3
2)从 2 到 3,从 3 到 2,从 2 到 3
3)从 2 到 3,从 3 到 4,从 4 到 3
所以返回方法数 3。
N=3,M=1,K=3,P=3
上面的参数代表所有位置为 1 2 3。机器人最开始在 1 位置上,必须经过 3 步,最后到达 3 位置。怎么走也不可能,所以返回方法数 0。
【解答】
-
法一:暴力递归
想想怎么去尝试走所有的路。如果当前来到 cur 位置,还剩 rest 步要走,那么下一步该怎么走呢?如果当前 cur=1,下一步只能走到 2,后续还剩下 rest-1 步;如果当前 cur=N,下一步只能走到 N-1,后续还剩 rest-1 步;如果 cur 是 1~N 中间的位置,下一步可以走到 cur-1 或者 cur+1,后续还剩 rest-1 步。每一种能走的可能都尝试一遍,每一次尝试怎么算结束?所有步数都走完了,尝试就可以结束了。如果走完了所有的步数,最后的位置停在了 P,说明这次尝试有效,即找到了 1 种;如果最后的位置没有停在 P,说明这次尝试无效,即找到了 0 种。
-
法二:动态规划(可空间压缩)
解决一个问题,如果没有想到显而易见的求解策略(比如数学公式、贪心策略等,都是显而易见的求解策略),那么就想如何通过尝试的方式找到答案,一旦写出了好的尝试函数,后面的优化过程全是固定套路。下面介绍本题如何从暴力递归优化成动态规划的解法。暴力递归优化成动态规划时,首先根据 walk 函数的含义结合题意,分析整个递归过程是不是无后效性的。分析一个递归过程是不是无后效性非常重要,可以帮我们确定这个暴力递归能不能改成动态规划。所谓无后效性,是指一个递归状态的返回值与怎么到达这个状态的路径无关。
比如本题,walk 函数有两个固定参数 N 和 P,任何时候都不变,说明 N 和 P 与具体的递归状态无关,忽略它们。只需要关注可变参数 cur 和 rest。walk(cur, rest)表示的含义是,当前来到cur 位置,还剩 rest 步,有效方法有多少种。比如 cur=5,rest=7,代表当前来到 5 位置,还剩 7步,有效方法有多少种。下图画出了如果想求出 walk(5, 7),状态的依赖关系。

图中walk(5,5)状态出现了两次,含义是当前来到 5 位置,还剩 5 步,有效方法有多少种。那么最终的返回值与怎么到达这个状态的路径有关系吗?没有。不管是从 walk(4,6)来到walk(5,5),还是从 walk(6,6)来到 walk(5,5),只要是“当前来到 5 位置,还剩 5 步”这个问题,返回值都是不变的。所以这是一个无后效性问题。接下来的分析与原始题意已经没有关系了,某个无后效性的递归过程(尝试过程)一旦确定,怎么优化成动态规划是有固定套路的。
套路大体步骤如下。
前提:你的尝试过程是无后效性的。
1)找到什么可变参数可以代表一个递归状态,也就是哪些参数一旦确定,返回值就确定了。
2)把可变参数的所有组合映射成一张表,有 1 个可变参数就是一维表,2 个可变参数就是二维表……
3)最终答案要的是表中的哪个位置,在表中标出。
4)根据递归过程的 base case,把这张表最简单、不需要依赖其他位置的那些位置填好值。
5)根据递归过程非 base case 的部分,也就是分析表中的普遍位置需要怎么计算得到,那么这张表的填写顺序也就确定了。
6)填好表,返回最终答案在表中位置的值。
下面以本题为例来使用这个套路。假设想求,N=7,M=4,K=9,P=5 的答案。
前提:walk 方法是无后效性的,满足前提。
1)walk 函数中,可变参数 cur 和 rest 一旦确定,返回值就确定了。
2)如果可变参数 cur 和 rest 组合的所有情况组成一张表,这张表一定可以装下所有的返回值。cur 变量的含义是当前来到的位置,例子给的 N 代表一共有 1~7 这些位置,所以 cur 一定不会在 1~7 的范围之外;rest 变量的含义是还剩多少步,例子给的 K 代表最开始走的时候的剩余步数,走的过程中剩余步数一定是减小的,所以 rest 一定不会在 0~9 范围之外。那么 cur 和rest 组合的所有情况如下图所示,这是一张二维表。

图中列对应的是 cur(范围为 1~7),行对应的是 rest(范围为 0~9),其实谁做行对应,谁做列对应是无所谓的,只要能枚举所有的组合即可。任何一个状态 walk(cur,rest)都一定可以放在这张表中。这张表是一个二维数组,记为 dp[][],那么 walk(cur,rest)的返回值就是dp[rest] [cur]。
3)N=7,M=4,K=9,P=5 的最终答案,就是 dp[9] [4]位置的值,在图中已经用星号标出。那么如何求出这个值呢?
4)递归过程的 base case 是指问题的规模小到什么程度,就不需要再划分子问题,答案就可以直接得到了。walk 函数中的 base case 如下:
if (rest == 0) { return cur == P ? 1 : 0; }当 rest=0 时,如果 cur=P,返回 1;否则返回 0。本题中 P=5。所以可以把表的第一行填好,表中第一行的所有状态都是最简单且不需要依赖其他位置的。

5)base case 之外的情况都是普遍位置,在 walk 函数中如下:
if (cur == 1) { return walk(N, cur + 1, rest - 1, P); } if (cur == N) { return walk(N, cur - 1, rest - 1, P); } return walk(N, cur - 1, rest - 1, P) + walk(N, cur + 1, rest - 1, P);如下图,如果 cur 在 1 位置,最终返回值 dp[rest] [cur]=dp[rest-1] [cur+1](图中 A 点依赖 B 点);如果cur 在 N 位置,最终返回值 dp[rest] [cur]=dp[rest-1] [cur-1](图中 C 点依赖 D 点);如果 cur 在中间位置,dp[rest] [cur]=dp[rest-1] [cur-1]+dp[rest-1] [cur+1](图中 E 点依赖 F 点和 G 点)。
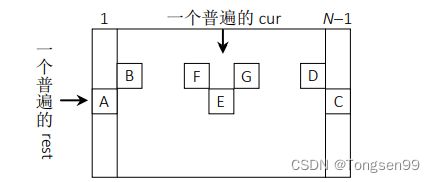
这说明每一行的值都只依赖上一行的值,那么如果有了第一行的值,就可以推出整张表。 整张表的值如下图所示。

6)返回 dp[9] [4]的值,答案是 116。
【代码】
- 法一
#include - 法二
#include 换钱的方法数
【题目】
给定数组 arr,arr 中所有的值都为正数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个整数 aim,代表要找的钱数,求换钱有多少种方法。
例如:
arr=[5,10,25,1],aim=0。
组成 0 元的方法有 1 种,就是所有面值的货币都不用。所以返回 1。
arr=[5,10,25,1],aim=15。
组成 15 元的方法有 6 种,分别为 3 张 5 元、1 张 10 元+1 张 5 元、1 张 10 元+5 张 1 元、10张 1 元+1 张 5 元、2 张 5 元+5 张 1 元和 15 张 1 元。所以返回 6。
arr=[3,5],aim=2。
任何方法都无法组成 2 元。所以返回 0。
【解答】
-
法一:暴力递归
如果 arr=[5,10,25,1],aim=1000,分析过程如下:
1.用 0 张 5 元的货币,让[10,25,1]组成剩下的 1000,最终方法数记为 res1。
2.用 1 张 5 元的货币,让[10,25,1]组成剩下的 995,最终方法数记为 res2。
3.用 2 张 5 元的货币,让[10,25,1]组成剩下的 990,最终方法数记为 res3。
……
201.用 200 张 5 元的货币,让[10,25,1]组成剩下的 0,最终方法数记为 res201。
那么 res1+res2+…+res201 的值就是总的方法数。根据如上的分析过程定义递归函数process(arr,index,aim),它的含义是如果用 arr[index…N-1]这些面值的钱组成 aim,返回总的方法数。
-
法二:记忆化搜索
接下来介绍基于暴力递归初步优化的方法,也就是记忆搜索的方法。暴力递归之所以暴力,是因为存在大量的重复计算。比如上面的例子,当已经使用 0 张 5 元+1 张 10 元的情况下,后续应该求[25,1]组成剩下的 990 的方法总数。当已经使用 2 张 5 元+0 张 10 元的情况下,后续还是求[25,1]组成剩下的 990 的方法总数。两种情况下都需要求 process(arr,2,990)。类似这样的重复计算在暴力递归的过程中大量发生。
记忆化搜索的优化方式。process(arr,index,aim)中 arr 是始终不变的,变化的只有 index 和aim,所以可以用 p(index,aim)表示一个递归过程。重复计算之所以大量发生,是因为每一个递归过程的结果都没记下来,所以下次还要重复去求。我们可以事先准备好一个 map,每计算完一个递归过程,都将结果记录到 map 中。当下次进行同样的递归过程之前,先在 map 中查询这个递归过程是否已经计算过,如果已经计算过,就把值拿出来直接用,如果没计算过,需要再进入递归过程。因为本题的递归过程可由两个变量表示,所以 map 是一张二维表。map[i] [j]表示递归过程 p(i,j)的返回值。另外有一些特殊值,map[i] [j]=0 表示递归过程 p(i,j)从来没有计算过。map[i] [j]=-1 表示递归过程 p(i,j)计算过,但返回值是 0。如果 map[i] [j]的值既不等于 0,也不等于-1,记为 a,则表示递归过程 p(i,j)的返回值为 a。
-
法三:动态规划(可空间压缩)
生成行数为 N、列数为 aim+1 的矩阵 dp,dp[i] [j]的含义是在使用 arr[0…i]货币的情况下,组成钱数 j 有多少种方法。dp[i] [j]的值求法如下:
1.对于矩阵 dp 第一列的值 dp[…] [0],表示组成钱数为 0 的方法数,很明显是 1 种,也就是不使用任何货币。所以 dp 第一列的值统一设置为 1。
2.对于矩阵 dp 第一行的值 dp[0] […],表示只能使用 arr[0]这一种货币的情况下,组成钱的方法数,比如,arr[0]==5 时,能组成的钱数只有 0,5,10,15,…。所以,令 dp[0] [k * arr[0]]=1(0≤k×arr[0]≤aim,k 为非负整数)。
3.除第一行和第一列的其他位置,记为位置(i,j)。dp[i] [j]的值是以下几个值的累加。
-
完全不用 arr[i]货币,只使用 arr[0…i-1]货币时,方法数为 dp[i-1] [j]
-
用 1 张 arr[i]货币,剩下的钱用 arr[0…i-1]货币组成时,方法数为 dp[i-1] [j-arr[i]]。
-
用 2 张 arr[i]货币,剩下的钱用 arr[0…i-1]货币组成时,方法数为 dp[i-1] [j-2 * arr[i]]。
……
-
用 k 张 arr[i]货币,剩下的钱用 arr[0…i-1]货币组成时,方法数为 dp[i-1] [j-k * arr[i]]。j-k * arr[i]>=0,k 为非负整数。
4.最终 dp[N-1] [aim]的值就是最终结果。
这里的步骤 3 可以有一个优化,即步骤 3 中第 1 种情况的方法数为 dp[i-1] [j],而第 2 种情况一直到第 k 种情况的方法数累加值其实就是 dp[i] [j-arr[i]]的值。所以步骤 3 可以简化为 dp[i] [j]=dp[i-1] [j]+dp[i] [j-arr[i]]。一下省去了枚举的过程。
-
【代码】
- 法一
#include - 法二
#include - 法三
#include 附:
1.记忆化搜索和动态规划各有优劣。如果将暴力递归过程简单地优化成记忆搜索的方法,递归函数依然在使用,这在工程上的开销较大。而动态规划方法严格规定了计算顺序,可以将递归计算变成顺序计算,这是动态规划方法具有的优势。其实记忆搜索的方法也有优势,本题就很好地体现了。比如,arr=[20000,10000,1000],aim=2000000000。如果是动态规划的计算方法,要严格计算 3×2000000001 个位置。而对于记忆搜索来说,因为面值最小的钱为 1000,所以百位为(1 ~ 9)、十位为(1 ~ 9)或个位为(1 ~ 9)的钱数是不可能出现的,当然也就没必要计算。而且记忆化搜索是对必须要计算的递归过程才去计算并记录的。
2.一旦想到暴力递归的过程,其实之后的优化过程是水到渠成的。首先看写出来的暴力递归函数,找出有哪些参数是不发生变化的,忽略这些变量。只看那些变化并且可以表示递归过程的参数,找出这些参数之后,记忆搜索的方法其实可以很轻易地写出来,因为只是简单的修改,计算完就记录到 map 中,并在下次直接拿来使用,没计算过则依然进行递归计算。接下来观察记忆搜索过程中使用的 map 结构,看看该结构某一个具体位置的值是通过哪些位置的值求出的,被依赖的位置先求,就能改出动态规划的方法。改出的动态规划方法中,如果有枚举的过程,看看枚举过程是否可以继续优化。
打气球的最大分数
【题目】
给定一个数组 arr,代表一排有分数的气球。每打爆一个气球都能获得分数,假设打爆气球的分数为 X,获得分数的规则如下:
1)如果被打爆气球的左边有没被打爆的气球,找到离被打爆气球最近的气球,假设分数为L;如果被打爆气球的右边有没被打爆的气球,找到离被打爆气球最近的气球,假设分数为 R。获得分数为 L×X×R。
2)如果被打爆气球的左边有没被打爆的气球,找到离被打爆气球最近的气球,假设分数为L;如果被打爆气球的右边所有气球都已经被打爆。获得分数为 L×X。
3)如果被打爆气球的左边所有的气球都已经被打爆;如果被打爆气球的右边有没被打爆的气球,找到离被打爆气球最近的气球,假设分数为 R;如果被打爆气球的右边所有气球都已经被打爆。获得分数为 X×R。
4)如果被打爆气球的左边和右边所有的气球都已经被打爆。获得分数为 X。
目标是打爆所有气球,获得每次打爆的分数。通过选择打爆气球的顺序,可以得到不同的总分,请返回能获得的最大分数。
例如:
arr = {3,2,5}
如果先打爆 3,获得 3×2;再打爆 2,获得 2×5;最后打爆 5,获得 5。最后总分 21。
如果先打爆 3,获得 3×2;再打爆 5,获得 2×5;最后打爆 2,获得 2。最后总分 18。
如果先打爆 2,获得 3×2×5;再打爆 3,获得 3×5;最后打爆 5,获得 5。最后总分 50。
如果先打爆 2,获得 3×2×5;再打爆 5,获得 3×5;最后打爆 3,获得 3。最后总分 48。
如果先打爆 5,获得 2×5;再打爆 3,获得 3×2;最后打爆 2,获得 2。最后总分 18。
如果先打爆 5,获得 2×5;再打爆 2,获得 3×2;最后打爆 3,获得 3。最后总分 19。
能获得的最大分数为 50。
【解答】
-
法一:暴力递归
假设要打爆 arr[L…R]这个范围上所有的气球,并且假设 arr[L-1]和 arr[R+1]的气球都没有被打爆,尝试的过程为 process 函数,最后获得的最大分数为 process(L,R)。依次尝试,如果每个气球最后被打爆,具体为:
如果 arr[L]是最后被打爆的,也就是先把 arr[L+1…R]范围上的气球都打完之后,再打爆 arr[L]。先把 arr[L+1…R]范围上的气球都打完能够获得的最大分数为 process(L+1,R)。因为此时 arr[L+1…R]的气球都打完了,所以 arr[L]的左边为 arr[L-1],右边为 arr[R+1],最后打爆 arr[L]获得的分数为arr[L-1] * arr[L] * arr[R+1],总分为 arr[L-1] * arr[L] * arr [R+1]+process(L+1,R)。
如果 arr[L+1]是最后被打爆的,也就是先把 arr[L…L]和 arr[L+2…R]范围上的气球都打完之后,再打爆 arr[L+1]。把 arr[L…L]范围上的气球都打完能够获得的最大分数为 process(L,L),把 arr[L+2…R]范围上的气球都打完能够获得的最大分数为 process(L+2,R)。因为此时 arr[L…L]和 arr[L+2…R]的气球都打完了,所以 arr[L+1]的左边为 arr[L-1],右边为 arr[R+1],最后打爆 arr[L]获得的分数为arr[L-1] * arr[L+1] * arr[R+1],总分为 process(L,L)+process (L+2,R)+arr[L-1] * arr[L] * arr[R+1]。
……
如果 arr[i]是最后被打爆的(L
……
如果 arr[R]是最后被打爆的,也就是先把 arr[L…R-1]范围上的气球都打完之后,再打爆 arr[R]。先把 arr[L…R-1]范围上的气球都打完能够获得的最大分数为 process(L,R-1)。因为此时 arr[L…R-1]的气球都打完了,所以 arr[R]的左边为 arr[L-1],右边为 arr[R+1],最后打爆 arr[R]获得的分数为arr[L-1] * arr[R] * arr[R+1],总分为 process(L,R-1)+arr[L-1] * arr[R] * arr[R+1]。
以上所有的尝试方案中,哪个方案的总分最大,哪个就是 process(L,R)的返回值。
注意,把 arr 的开头和结尾补上 1,然后打爆除两头的 1 还剩下的位置,就是答案(这样避免了判断边界问题)。
-
法二:动态规划
假设 arr={4,2,3,5,1,6},生成的 help={1,4,2,3,5,1,6,1},求的是打爆help[1…6]上的所有气球获得的最大分数。利用优化套路过程如下。
前提:尝试过程是无后效性的。process(L,R)解决的问题就是打爆 help[L…R]上所有的气球获得的最大分数,不管如何到达的 process(L,R),返回值一定是固定的。
1)可变参数 L 和 R 一旦确定,返回值就确定了。
2)如果可变参数 L 和 R 组合的所有情况组成一张表,这张表一定可以装下所有的返回值。L 变量的含义是 help 中的位置,所以 L 一定不会在 1~6 的范围之外;R 变量的含义是 help 中的位置,所以 L 一定不会在 1~6 范围之外。那么 L 和 R 组合的所有情况如下图所示,这是一个正方形矩阵。

在图中,行对应 L,列对应 R,枚举了 L 和 R 所有的组合即可,其中第 0 行、第 7 行、第 0 列和第 7 列是永远不会用到的,这些位置在图中已经用叉号标出。因为 process(L,R)表达的含义是在 help[L…R]这个范围上做尝试,所以 L 不可能大于 R。也就是说,这张表中不含对角线的下半区(L>R)是永远不会用到的,这些位置在图中已经用圆圈标出。任何一个状态 process(L,R)都一定可以放在剩下的位置中,这张表记为 dp[] []。
3)我们要的最终状态是 process(1,6),也就是 dp[1] [6]的值,在表中已经用星号标出。如何求出这个值呢?
4)根据 process(L,R)函数的 base case,填写初始的位置:
if (L == R) { return arr[L - 1] * arr[L] * arr[R + 1]; }
5)base case 之外的情况都是普遍位置,在 process(L,R)函数中如下:
int maxValue = max(arr[L - 1] * arr[L] * arr[R + 1] + process(arr, L + 1, R), arr[L - 1] * arr[R] * arr[R + 1] + process(arr, L, R - 1)); // 尝试中间位置的气球最后被打爆的每一种方案 for (int i = L + 1; i < R; i++) { maxValue = max(maxValue, arr[L - 1] * arr[i] * arr[R + 1] + process(arr, L, i - 1) + process(arr, i + 1, R)); }如果用看代码的方式分析状态依赖不直观,可以用分析 dp 表的方式。比如 dp[1] [6]这个位置(星号),依赖哪些位置呢?根据 process(L,R)的代码,分析出 process(1,6)依赖的位置有:
1)process(2,6),最后打爆 help[1]时的依赖,下图中的 A。
2)process(1,5),最后打爆 help[6]时的依赖,下图中的 B。
3)process(1,1),最后打爆 help[2]时的依赖,下图中的 C。
4)process(3,6),最后打爆 help[2]时的依赖,下图中的 D。
5)process(1,2),最后打爆 help[3]时的依赖,下图中的 E。
6)process(4,6),最后打爆 help[3]时的依赖,下图中的 F。
7)process(1,3),最后打爆 help[4]时的依赖,下图中的 G。
8)process(5,6),最后打爆 help[4]时的依赖,下图中的 H。
9)process(1,4),最后打爆 help[5]时的依赖,下图中的 I。
10)process(6,6),最后打爆 help[5]时的依赖,下图中的 J。

这说明 dp[L] [R]值都只依赖同一行左边和同一列下边的有效位置,已经标为无效的位置依然不需要。所以,除去对角线,剩下的位置应该怎么填呢?先填最下面的行,从左往右进行填写;填好一行之后,再从左往右填写上一行。最终填写到有效部分的最上面一行,最右的有效位置就是答案。按照这种顺序求解任何一个位置的值时,这个位置左边和下面的位置一定已经被填写过了。
6)返回 dp[1] [6]的值就是答案。
【代码】
- 法一
#include - 法二
#include 附:本题有个巧妙之处在于把 arr 的开头和结尾补上 1,然后打爆除两头的 1 还剩下的位置,这样可以避免判断越界所带来的烦恼,同时也保持乘积不变。
最长递增子序列
【题目】
给定数组 arr,返回 arr 的最长递增子序列。
例如:
arr=[2,1,5,3,6,4,8,9,7],返回的最长递增子序列为[1,3,4,8,9]。
【解答】
-
法一:动态规划
1.生成长度为 N 的数组 dp,dp[i]表示在以 arr[i]这个数结尾的情况下,arr[0…i]中的最大递增子序列长度。
2.对第一个数 arr[0]来说,令 dp[0]=1,接下来从左到右依次算出以每个位置的数结尾的情况下,最长递增子序列长度。
3.假设计算到位置 i,求以 arr[i]结尾情况下的最长递增子序列长度,即 dp[i]。如果最长递增子序列以 arr[i]结尾,那么在 arr[0…i-1]中所有比 arr[i]小的数都可以作为倒数第二个数。在这么多倒数第二个数的选择中,以哪个数结尾的最大递增子序列更大,就选哪个数作为倒数第二个数,所以 dp[i]=max{dp[j]+1(0<=j
按照步骤 1~步骤 3 可以计算出 dp 数组。
接下来解释如何根据求出的 dp 数组得到最长递增子序列。以题目的例子来说明,arr=[2,1,5,3,6,4,8,9,7],求出的数组 dp=[1,1,2,2,3,3,4,5,4]。
1.遍历 dp 数组,找到最大值以及位置。在本例中,最大值为 5,位置为 7,说明最终的最长递增子序列的长度为 5,并且应该以 arr[7]这个数(arr[7]=9)结尾。
2.从 arr 数组的位置 7 开始从右向左遍历。如果对某一个位置 i,既有 arr[i]
3.从 arr 数组的位置 6 开始继续向左遍历,按照同样的过程找到倒数第三个数。在本例中,位置 5 满足 arr[5]
4.重复这样的过程,直到所有的数都找出来。
dp 数组包含每一步决策的信息,其实根据 dp 数组找出最长递增子序列的过程就是从某一个位置开始逆序还原出决策路径的过程。
-
法二:动态规划+二分
生成 dp 数组的过程可以利用二分查找来进行优化。先生成一个长度为 N 的数组 ends,初始时 ends[0]=arr[0],其他位置上的值为 0。生成整型变量 right,初始时 right=0。在从左到右遍历 arr 数组的过程中,求解 dp[i]的过程需要使用 ends 数组和 right 变量,所以这里解释一下其含义。遍历的过程中,ends[0…right]为有效区,ends[right+1…N-1]为无效区。对有效区上的位置 b,如果有 ends[b]=c,则表示遍历到目前为止,在所有长度为 b+1 的递增序列中,最小的结尾数是 c。无效区的位置则没有意义。
比如,arr=[2,1,5,3,6,4,8,9,7],初始时 dp[0]=1,ends[0]=2,right=0。ends[0…0]为有效区,ends[0]=2 的含义是,在遍历过 arr[0]之后,所有长度为 1 的递增序列中(此时只有[2]),最小的结尾数是 2。之后的遍历继续用这个例子来说明求解过程。
1.遍历到 arr[1]=1。ends 有效区=ends[0…0]=[2],在有效区中找到最左边大于或等于 arr[1]的数。发现是 ends[0],表示以 arr[1]结尾的最长递增序列只有 arr[1],所以令 dp[1]=1。然后令ends[0]=1,因为遍历到目前为止,在所有长度为 1 的递增序列中,最小的结尾数是 1,而不再是 2。
2.遍历到 arr[2]=5。ends 有效区=ends[0…0]=[1],在有效区中找到最左边大于或等于 arr[2]的数。发现没有这样的数,表示以 arr[2]结尾的最长递增序列长度=ends 有效区长度+1,所以令dp[2]=2。ends 整个有效区都没有比 arr[2]更大的数,说明发现了比 ends 有效区长度更长的递增序列,于是把有效区扩大,ends 有效区=ends[0…1]=[1,5]。
3.遍历到 arr[3]=3。ends 有效区=ends[0…1]=[1,5],在有效区中用二分法找到最左边大于或等于 arr[3]的数。发现是 ends[1],表示以 arr[3]结尾的最长递增序列长度为 2,所以令 dp[3]=2。然后令 ends[1]=3,因为遍历到目前为止,在所有长度为 2 的递增序列中,最小的结尾数是 3,而不再是 5。
4.遍历到 arr[4]=6。ends 有效区=ends[0…1]=[1,3],在有效区中用二分法找到最左边大于或等于 arr[4]的数。发现没有这样的数,表示以 arr[4]结尾的最长递增序列长度=ends 有效区长度+1,所以令 dp[4]=3。ends 整个有效区都没有比 arr[4]更大的数,说明发现了比 ends 有效区长度更长的递增序列,于是把有效区扩大,ends 有效区=ends[0…2]=[1,3,6]。
5.遍历到 arr[5]=4。ends 有效区=ends[0…2]=[1,3,6],在有效区中用二分法找到最左边大于或等于 arr[5]的数。发现是 ends[2],表示以 arr[5]结尾的最长递增序列长度为 3,所以令 dp[5]=3。然后令 ends[2]=4,表示在所有长度为 3 的递增序列中,最小的结尾数变为 4。
6.遍历到 arr[6]=8。ends 有效区=ends[0…2]=[1,3,4],在有效区中用二分法找到最左边大于或等于 arr[6]的数。发现没有这样的数,表示以 arr[6]结尾的最长递增序列长度=ends 有效区长度+1,所以令 dp[6]=4。ends 整个有效区都没有比 arr[6]更大的数,说明发现了比 ends 有效区长度更长的递增序列,于是把有效区扩大,ends 有效区=ends[0…3]=[1,3,4,8]。
7.遍历到 arr[7]=9。ends 有效区=ends[0…3]=[1,3,4,8],在有效区中用二分法找到最左边大于或等于 arr[7]的数。发现没有这样的数,表示以 arr[7]结尾的最长递增序列长度=ends 有效区长度+1,所以令 dp[7]=5。ends 整个有效区都没有比 arr[7]更大的数,于是把有效区扩大,ends有效区=ends[0…5]=[1,3,4,8,9]。
8.遍历到 arr[8]=7。ends 有效区=ends[0…5]=[1,3,4,8,9],在有效区中用二分法找到最左边大于或等于 arr[8]的数。发现是 ends[3],表示以 arr[8]结尾的最长递增序列长度为 4,所以令dp[8]=4。然后令 ends[3]=7,表示在所有长度为 4 的递增序列中,最小的结尾数变为 7。
【代码】
- 法一
#include - 法二
#include 信封嵌套问题
【题目】
给定一个 N 行 2 列的二维数组,每一个小数组的两个值分别代表一个信封的长和宽。如果信封 A 的长和宽都小于信封 B,那么信封 A 可以放在信封 B 里,请返回信封最多嵌套多少层。
例如:
matrix = { {3,4}, {2,3}, {4,5}, {1,3}, {2,2}, {3,6}, {1,2}, {3,2}, {2,4} }
信封最多可以套 4 层,从里到外分别是{1,2},{2,3},{3,4},{4,5},所以返回 4。
【解答】
-
排序策略+最长递增子序列
首先把 N 个长度为 2 的小数组变成信封数组。然后对信封数组排序,排序的策略为,按照长度从小到大排序,长度相等的信封之间按照宽度从大到小排序。
比如原问题给出的例子,排序之后的结果为一个信封对象的数组,如下图所示。

接下来在排序后的这个信封数组中忽略长度,只看宽度数组,也就是只看{3,2,4,3,2,6,4,2,5}这个数组的最长递增子序列长度是多少即可。为什么呢?这与我们的排序策略有关,按照长度从小到大排序,长度相等的信封之间按照宽度从大到小排序。
我们假设有一个信封 X,处在这个排序之后数组中的某个位置,长度为 Xlen,宽度为 Xwid。我们要求出必须以 X 作为最外面信封的情况下,最多套几层。那么信封 X 之后的信封一定不能放在 X 里,因为之后信封的长度都大于或等于 Xlen。分析一下信封 X 之前的信封,因为排序策略是按照长度从小到大排序的,所以 X 之前的信封长度要么小于 X,要么等于 X:
1)如果 X 之前的信封长度小于 X 的长度。那么只要之前信封的宽度小于 X 的宽度,一定可以放在 X 内。所以在宽度组成的数组中,X 的宽度如果作为最后一个数,求宽度数组的最长递增子序列即可。
2)如果 X 之前的信封长度等于 X 的长度。因为长度相等的信封之间按照宽度从大到小排序,所以这些信封的宽度一定大于或等于 X 的宽度,这样就不可能是 X 的宽度作为最后一个数的情况下,宽度数组的最长递增子序列的一部分。
所以,只需要求 X 的宽度作为最后一个数的情况下,宽度数组的最长递增子序列长度即可。
比如,在上图中的信封 7,宽度为 4,以信封 7 结尾的宽度数组为{3,2,4,3,2,6,4},必须以信封 7 结尾的宽度数组中,最长递增子序列为{2,3,4}。所以必须以信封 7 作为最外层的情况下,最多套 3 层。也就是说,在这个排序策略下,只要 X 之前的信封宽度小于 X 的宽度,长度也必小于 X 的长度。求一个数组的最长递增子序列即可。
【代码】
#include 汉诺塔问题
【题目】
给定一个整数 n,代表汉诺塔游戏中从小到大放置的 n 个圆盘,假设开始时所有的圆盘都放在左边的柱子上,想按照汉诺塔游戏的要求把所有的圆盘都移到右边的柱子上。实现函数打印最优移动轨迹。
例如:
n=1 时,打印:
move from left to right
n=2 时,打印:
move from left to mid
move from left to right
move from mid to right
进阶问题:给定一个整型数组 arr,其中只含有 1、2 和 3,代表所有圆盘目前的状态,1 代表左柱,2 代表中柱,3 代表右柱,arr[i]的值代表第 i+1 个圆盘的位置。比如,arr=[3,3,2,1],代表第 1 个圆盘在右柱上、第 2 个圆盘在右柱上、第 3 个圆盘在中柱上、第 4 个圆盘在左柱上。如果 arr 代表的状态是最优移动轨迹过程中出现的状态,返回 arr 这种状态是最优移动轨迹中的第几个状态。如果 arr 代表的状态不是最优移动轨迹过程中出现的状态,则返回-1。
例如:
arr=[1,1]。两个圆盘目前都在左柱上,也就是初始状态,所以返回 0。
arr=[2,1]。第一个圆盘在中柱上、第二个圆盘在左柱上,这个状态是 2 个圆盘的汉诺塔游戏中最优移动轨迹的第 1 步,所以返回 1。
arr=[3,3]。第一个圆盘在右柱上、第二个圆盘在右柱上,这个状态是 2 个圆盘的汉诺塔游戏中最优移动轨迹的第 3 步,所以返回 3。
arr=[2,2]。第一个圆盘在中柱上、第二个圆盘在中柱上,这个状态是 2 个圆盘的汉诺塔游戏中最优移动轨迹从来不会出现的状态,所以返回-1。
【解答】
-
递归或非递归
原问题。假设有 from 柱子、mid 柱子和 to 柱子,都从 from 的圆盘 1~i 完全移动到 to,最优过程为:
步骤 1:为圆盘 1~i-1 从 from 移动到 mid。
步骤 2:为单独把圆盘 i 从 from 移动到 to。
步骤 3:为把圆盘 1~i-1 从 mid 移动到 to。如果圆盘只有 1 个,直接把这个圆盘从 from 移动到 to 即可。
进阶问题。首先求都在 from 柱子上的圆盘 1~i,如果都移动到 to 上的最少步骤数假设为 S ( i ) S(i) S(i)。根据上面的步骤, S ( i ) S(i) S(i)=步骤 1 的步骤总数+1+步骤 3 的步骤总数= S ( i − 1 ) + 1 + S ( i − 1 ) S(i-1)+1+S(i-1) S(i−1)+1+S(i−1), S ( 1 ) = 1 S(1)=1 S(1)=1。所以 S ( i ) + 1 = 2 ( S ( i − 1 ) + 1 ) S(i)+1=2(S(i-1)+1) S(i)+1=2(S(i−1)+1),又 S ( 1 ) + 1 = 2 S(1)+1=2 S(1)+1=2。根据等比数列求和公式得到 S ( i ) + 1 = 2 i S(i)+1=2^i S(i)+1=2i,所以 S ( i ) = 2 i − 1 S(i)=2^i-1 S(i)=2i−1。
对于数组 arr 来说,arr[N-1]表示最大圆盘 N 在哪个柱子上,情况有以下三种。
- 圆盘 N 在左柱上,说明步骤 1 或者没有完成,或者已经完成,需要考查圆盘 1~N-1的状况。
- 圆盘 N 在右柱上,说明步骤 1 已经完成,起码走完了 2 N − 1 − 1 2^{N-1}-1 2N−1−1 步。步骤 2 也已经完成,起码又走完了 1 步,所以当前状况起码是最优步骤的 2 N − 1 2^{N-1} 2N−1步,剩下的步骤怎么确定还得继续考查圆盘 1~N-1 的状况。
- 圆盘 N 在中柱上,这是不可能的,最优步骤中不可能让圆盘 N 处在中柱上,直接返回-1。
所以整个过程可以总结为:对圆盘 1~i 来说,如果目标为从 from 到 to,那么情况有三种:
- 圆盘 i 在 from 上,需要继续考查圆盘 1~i-1 的状况,圆盘 1~i-1 的目标为从 from 到 mid。
- 圆盘 i 在 to 上,说明起码走完了 2 i − 1 2^{i-1} 2i−1步,剩下的步骤怎么确定还得继续考查圆盘 1~i-1的状况,圆盘 1~i-1 的目标为从 mid 到 to。
- 圆盘 i 在 mid 上,直接返回-1。
【代码】
- 递归
#include - 非递归
#include 最长公共子序列问题
【题目】
给定两个字符串 str1 和 str2,返回两个字符串的最长公共子序列。
例如:
str1=“1A2C3D4B56”,str2=“B1D23CA45B6A”。
"123456"或者"12C4B6"都是最长公共子序列,返回哪一个都行。
【解答】
-
动态规划
先来介绍求解动态规划表的过程。如果 str1 的长度为 M,str2 的长度为 N,生成大小为 M×N 的矩阵 dp,行数为 M,列数为 N。dp[i] [j]的含义是 str1[0…i]与 str2[0…j]的最长公共子序列的长度。从左到右,再从上到下计算矩阵 dp。
1.矩阵 dp 第一列即 dp[0…M-1] [0],dp[i] [0]的含义是 str1[0…i]与 str2[0]的最长公共子序列长度。str2[0]只有一个字符,所以 dp[i] [0]最大为 1。如果 str1[i]=str2[0],令 dp[i] [0]=1,一旦 dp[i] [0]被设置为 1,之后的 dp[i+1…M-1] [0]也都为 1。比如,str1[0…M-1]=“ABCDE”,str2[0]=“B”。str1[0]为"A",与 str2[0]不相等,所以 dp[0] [0]=0。str1[1]为"B",与 str2[0]相等,所以 str1[0…1]与 str2[0]的最长公共子序列为"B",令 dp[1] [0]=1。之后的 dp[2…4] [0]肯定都是 1,因为 str[0…2]、str[0…3]和 str[0…4]与 str2[0]的最长公共子序列肯定有"B"。
2.矩阵 dp 第一行即 dp[0] [0…N-1]与步骤 1 同理,如果 str1[0]=str2[j],则令 dp[0] [j]=1,一旦dp[0] [j]被设置为 1,之后的 dp[0] [j+1…N-1]也都为 1。
3.对其他位置(i,j),dp[i] [j]的值只可能来自以下三种情况。
- 可能是 dp[i-1] [j],代表 str1[0…i-1]与 str2[0…j]的最长公共子序列长度。比如,str1=“A1BC2”,str2=“AB34C”。str1[0…3](即"A1BC")与 str2[0…4](即"AB34C")的最长公共子序列为"ABC",即 dp[3] [4]为 3。str1[0…4](即"A1BC2")与 str2[0…4](即"AB34C")的最长公共子序列也是"ABC",所以 dp[4] [4]也为 3。
- 可能是 dp[i] [j-1],代表 str1[0…i]与 str2[0…j-1]的最长公共子序列长度。比如,str1=“A1B2C”,str2=“AB3C4”。str1[0…4](即"A1B2C")与 str2[0…3](即"AB3C")的最长公共子序列为"ABC",即 dp[4] [3]为 3。str1[0…4](即"A1B2C")与 str2[0…4](即"AB3C4")的最长公共子序列也是"ABC",所以 dp[4] [4]也为 3。
- 如果 str1[i]=str2[j],还可能是 dp[i-1] [j-1]+1。比如 str1=“ABCD”,str2=“ABCD”。str1[0…2](即"ABC")与 str2[0…2](即"ABC")的最长公共子序列为"ABC",即 dp[2] [2]为 3。因为str1[3]=str2[3]=“D”,所以 str1[0…3]与 str2[0…3]的最长公共子序列是"ABCD"。
这三个可能的值中,选最大的作为 dp[i] [j]的值。
dp 矩阵中最右下角的值代表 str1 整体和 str2 整体的最长公共子序列的长度。通过整个 dp矩阵的状态,可以得到最长公共子序列。具体方法如下:
1.从矩阵的右下角开始,有三种移动方式:向上、向左、向左上。假设移动的过程中,i表示此时的行数,j 表示此时的列数,同时用一个变量 res 来表示最长公共子序列。
2.如果 dp[i] [j]大于 dp[i-1] [j]和 dp[i] [j-1],说明之前在计算 dp[i] [j]的时候,一定是选择了决策 dp[i-1] [j-1]+1,可以确定 str1[i]等于 str2[j],并且这个字符一定属于最长公共子序列,把这个字符放进 res,然后向左上方移动。
3.如果 dp[i] [j]等于 dp[i-1] [j],说明之前在计算 dp[i] [j]的时候,dp[i-1] [j-1]+1 这个决策不是必须选择的决策,向上方移动即可。
4.如果 dp[i] [j]等于 dp[i] [j-1],与步骤 3 同理,向左方移动。
5.如果 dp[i] [j]同时等于 dp[i-1] [j]和 dp[i] [j-1],向上还是向下无所谓,选择其中一个即可,反正不会错过必须选择的字符。
也就是说,通过 dp 求解最长公共子序列的过程就是还原出当时如何求解 dp 的过程,来自哪个策略,就朝哪个方向移动。
【代码】
#include 最长公共子串问题
【题目】
给定两个字符串 str1 和 str2,返回两个字符串的最长公共子串。
例如:
str1=“1AB2345CD”,str2=“12345EF”,返回"2345"。
【解答】
-
法一:动态规划
首先需要生成动态规划表。生成大小为 M×N 的矩阵 dp,行数为 M,列数为 N。dp[i] [j]的含义是,在必须把 str1[i]和 str2[j]当作公共子串最后一个字符的情况下,公共子串最长能有多长。比如,str1=“A1234B”,str2=“CD1234”,dp[3] [4]的含义是在必须把 str1[3](即’3’)和 str2[4](即’3’)当作公共子串最后一个字符的情况下,公共子串最长能有多长。这种情况下的最长公共子串为"123",所以 dp[3] [4]为 3。再如,str1=“A12E4B”,str2=“CD12F4”,dp[3] [4]的含义是在必须把 str1[3](即’E’)和 str2[4](即’F’)当作公共子串最后一个字符的情况下,公共子串最长能有多长。这种情况下,根本不能构成公共子串,所以 dp[3] [4]为 0。介绍了 dp[i] [j]的意义后,接下来介绍 dp[i] [j]怎么求。具体过程如下:
1.矩阵 dp 第一列即 dp[0…M-1] [0]。对某一个位置(i,0)来说,如果 str1[i]=str2[0],令 dp[i] [0]=1,否则令 dp[i] [0]=0。比如 str1=“ABAC”,str2[0]=“A”。dp 矩阵第一列上的值依次为 dp[0] [0]=1,dp[1] [0]=0,dp[2] [0]=1,dp[3] [0]=0。
2.矩阵 dp 第一行即 dp[0] [0…N-1]与步骤 1 同理。对某一个位置(0,j)来说,如果 str1[0]=str2[j],令 dp[0] [j]=1,否则令 dp[0] [j]=0。
3.其他位置按照从左到右,再从上到下来计算,dp[i] [j]的值只可能有两种情况。
- 如果 str1[i]!=str2[j],说明在必须把 str1[i]和 str2[j]当作公共子串最后一个字符是不可能的,令 dp[i] [j]=0。
- 如果 str1[i]=str2[j],说明 str1[i]和 str2[j]可以作为公共子串的最后一个字符,从最后一个字符向左能扩多大的长度呢?就是 dp[i-1] [j-1]的值,所以令 dp[i] [j]=dp[i-1] [j-1]+1。
如果 str1=“abcde”,str2=“bebcd”。计算的 dp 矩阵如下:
b e b c d
a 0 0 0 0 0
b 1 0 1 0 0
c 0 0 0 2 0
d 0 0 0 0 3
e 0 1 0 0 0生成动态规划表 dp 之后,得到最长公共子串是非常容易的。比如,上边生成的 dp 中,最大值是 dp[3] [4]==3,说明最长公共子串的长度为 3。最长公共子串的最后一个字符是 str1[3],当然也是 str2[4],因为两个字符一样。那么最长公共子串为从 str1[3]开始向左一共 3 字节的子串,即 str1[1…3],当然也是 str2[2…4]。总之,遍历 dp 找到最大值及其位置,最长公共子串自然可以得到。
-
法二:动态规划+空间压缩
计算每一个 dp[i] [j]的时候,最多只需要其左上方 dp[i-1] [j-1]的值,所以按照斜线方向来计算所有的值,只需要一个变量就可以计算出所有位置的值。
如下图所示,每一条斜线在计算之前生成整型变量 len,len 表示左上方位置的值,初始时 len=0。从斜线最左上的位置开始向右下方依次计算每个位置的值,假设计算到位置(i,j),此时 len 表示位置(i-1,j-1)的值。如果 str1[i]==str2[j],那么位置(i,j)的值为 len+1,如果 str1[i]!=str2[j],那么位置(i,j)的值为 0。计算后将 len 更新成位置(i,j)的值,然后计算下一个位置,即(i+1,j+1)位置的值。依次计算下去就可以得到斜线上每个位置的值,然后算下一条斜线。用全局变量 maxValue 记录所有位置的值中的最大值。最大值出现时,用全局变量 end 记录其位置即可。

【代码】
- 法一
#include - 法二
#include 子数组异或和为 0 的最多划分
【题目】
数组异或和的定义:把数组中所有的数异或起来得到的值。给定一个整型数组 arr,其中可能有正、有负、有零。你可以随意把整个数组切成若干个不相容的子数组,求异或和为 0 的子数组最多能有多少个?
例如:
arr = {3,2,1,9,0,7,0,2,1,3}
把数组分割成{3,2,1}、{9}、{0}、{7}、{0}、{2,1,3}是最优分割,因为其中{3,2,1}、{0}、{0}、{2,1,3}这四个子数组的异或和为 0,并且是所有的分割方案中,能切出最多异或和为 0 的子数组的方案,返回 4。
【解答】
-
动态规划
假设 arr 长度为 N,生成长度为 N 的数组 dp[]。dp[i]的含义是如果在arr[0…i]上做分割,异或和为 0 的子数组最多能有多少个。如果可以从左到右依次求出 dp[0]、dp[1]…dp[i-1]、dp[i]…dp[N-1]。那么 dp[N-1]的值就是:如果在 arr[0…N-1]上做分割,异或和为 0的子数组最多能有多少个,也就是最终答案。
现在假设 dp[0]~dp[i-1]已经求出,如何求出 dp[i]就是最关键的问题。为了分析这个问题,我们假设 arr[0~i]上存在最优分割。显而易见的是,分割出来的最后一个子数组一定包含 arr[i],那么这个最优分割的最后一个子数组只可能有如下两种情况。
1)最优分割的最后一个子数组,异或和不等于 0。
2)最优分割的最后一个子数组,异或和等于 0。
对于情况 1),如果最优分割的最后一个子数组异或和不等于 0,那么 dp[i]的值等于 dp[i-1]。可以这样来理解这个结论,既然在 arr[0…i]上做最优分割,并且切出来的异或和为 0 的子数组和arr[i]没有关系,那么 arr[0…i-1]最多能切多少个,arr[0…i]上就能切多少个。
对于情况 2),如果最优分割的最后一个子数组异或和等于 0。假设 arr[k…i]就是最优分割的最后一个子数组,并且异或和等于 0,那么 dp[i]的值等于 dp[k-1]+1。可以这样理解这个结论,如果我们已经知道在 arr[0…i]上的最优分割,并且最后一个分割出的子数组是 arr[k…i],也知道arr[k…i]的异或和是 0。那么在 arr[0…i]上最多能分割出几个异或和为0的子数组呢?就是arr[0…k-1]上最多能够分割出的数量(dp[k-1]),再加上 arr[k…i]这部分,就是答案,dp[i] = dp[k-1] + 1。那么如何求出 k 这个位置,就变成了唯一需要关心的问题。
在 arr[0…i]上的最优分割中,如果最后一个子数组异或和等于 0,且 arr[k…i]就是最后一个子数组。那么 k 到 i 之间的任何一个位置 j(k
如果我们记下 arr[0…0]的异或和、arr[0…1]的异或和……arr[0…i-1]的异或和。现在来到 i 位置,并且 arr[0…i]的异或和为 eor,我们只要知道 eor 上一次出现在什么位置,也就求出了 k 位置。举个例子:
arr = { 6, 3, 2, 1}
位置: 0 1 2 3
展示一下来到 i=3 位置时,怎么求 k 位置。
先准备一张表 map,key:某一个异或和;value:key 这个异或和上次出现的位置。
提前在 map 里放入一条记录(key = 0, value = -1),表示没遍历 arr 之前,就有 0 这个异或和。
遍历到 0 位置时,arr[0…0]的异或和为 6,把(6,0)这个记录放入 map。
此时 map 为:
(key = 0,value = -1)
(key = 6,value = 0)
遍历到 1 位置时,arr[0…1]的异或和为 5,把(5,1)这个记录放入 map。
此时 map 为:
(key = 0,value = -1)
(key = 6,value = 0)
(key = 5,value = 1)
遍历到 2 位置时,arr[0…2]的异或和为 7,把(7,2)这个记录放入 map。
此时 map 为:
(key = 0,value = -1)
(key = 6,value = 0)
(key = 5,value = 1)
(key = 7,value = 2)
遍历到 3 位置时,arr[0…3]的异或和为 6。怎么求 k?在 map 中看异或和为 6 上次出现的位置,是 0 位置。所以知道 arr[1…3]就是 arr[k…i],1 位置就是 k 位置。
情况 2)的分析结束。dp[i] = dp[k-1] + 1,k 为在 i 位置左边,离 i 位置最近的使得 arr[k…i]的异或和为 0 的位置。
两种情况中哪一个值更大,哪一个就是 dp[i]的值,即 dp[i] = max { dp[i-1], dp[k-1] + 1}。
【代码】
#include 最小编辑代价
【题目】
给定两个字符串 str1 和 str2,再给定三个整数 ic、dc 和 rc,分别代表插入、删除和替换一个字符的代价,返回将 str1 编辑成 str2 的最小代价。
例如:
str1=“abc”,str2=“adc”,ic=5,dc=3,rc=2。
从"abc"编辑成"adc",把’b’替换成’d’是代价最小的,所以返回 2。
str1=“abc”,str2=“adc”,ic=5,dc=3,rc=100。
从"abc"编辑成"adc",先删除’b’,然后插入’d’是代价最小的,所以返回 8。
str1=“abc”,str2=“abc”,ic=5,dc=3,rc=2。
不用编辑了,本来就是一样的字符串,所以返回 0。
【解答】
-
动态规划(可空间压缩)
假设 str1 的长度为 M,str2 的长度为 N。首先生成大小为(M+1)×(N+1)的矩阵 dp,dp[i] [j]的值代表str1[0…i-1]编辑成 str2[0…j-1]的最小代价。举个例子,str1=“ab12cd3”,str2=“abcdf”,ic=5,dc=3,rc=2。dp 是一个 8×6 的矩阵,最终计算结果如下。

下面具体说明 dp 矩阵每个位置的值是如何计算的。
1.dp[0] [0]=0,表示 str1 空的子串编辑成 str2 空的子串的代价为 0。
2.矩阵 dp 第一列即 dp[0…M-1] [0]。dp[i] [0]表示 str1[0…i-1]编辑成空串的最小代价,毫无疑问,是把 str1[0…i-1]所有的字符删掉的代价,所以 dp[i] [0]=dc * i。
3.矩阵 dp 第一行即 dp[0] [0…N-1]。dp[0] [j]表示空串编辑成 str2[0…j-1]的最小代价,毫无疑问,是在空串里插入 str2[0…j-1]所有字符的代价,所以 dp[0] [j]=ic * j。
4.其他位置按照从左到右,再从上到下来计算,dp[i] [j]的值只可能有以下四种情况。
- str1[0…i-1]可以先编辑成 str1[0…i-2],也就是删除字符 str1[i-1],然后由 str1[0…i-2]编辑成 str2[0…j-1],dp[i-1] [j]表示 str1[0…i-2]编辑成 str2[0…j-1]的最小代价,那么 dp[i] [j]可能等于 dc+dp[i-1] [j]。
- str1[0…i-1]可以先编辑成 str2[0…j-2],然后将 str2[0…j-2]插入字符 str2[j-1],编辑成str2[0…j-1],dp[i] [j-1]表示 str1[0…i-1]编辑成 str2[0…j-2]的最小代价,那么 dp[i] [j]可能等于 dp[i] [j-1]+ic。
- 如果 str1[i-1]!=str2[j-1]。先把 str1[0…i-1]中 str1[0…i-2]的部分变成 str2[0…j-2],然后把字符 str1[i-1]替换成 str2[j-1],这样 str1[0…i-1]就编辑成 str2[0…j-1]了。dp[i-1] [j-1]表示str1[0…i-2]编辑成 str2[0…i-2]的最小代价,那么 dp[i] [j]可能等于 dp[i-1] [j-1]+rc。
- 如果 str1[i-1]==str2[j-1]。先把 str1[0…i-1]中 str1[0…i-2]的部分变成 str2[0…j-2],因为此时字符 str1[i-1]等于 str2[j-1],所以 str1[0…i-1]已经编辑成 str2[0…j-1]了。dp[i-1] [j-1]表示str1[0…i-2]编辑成 str2[0…i-2]的最小代价,那么 dp[i] [j]可能等于 dp[i-1] [j-1]。
5.以上四种可能的值中,选最小值作为 dp[i] [j]的值。dp 最右下角的值就是最终结果。
【代码】
- 动态规划
#include - 动态规划+空间压缩
#include 字符串的交错组成
【题目】
给定三个字符串 str1、str2 和 aim,如果 aim 包含且仅包含来自 str1 和 str2 的所有字符,而且在 aim 中属于 str1 的字符之间保持原来在 str1 中的顺序,属于 str2 的字符之间保持原来在 str2中的顺序,那么称 aim 是 str1 和 str2 的交错组成。实现一个函数,判断 aim 是否是 str1 和 str2交错组成。
例如:
str1=“AB”,str2=“12”。那么"AB12"、“A1B2”、“A12B”、"1A2B"和"1AB2"等都是 str1 和 str2 的交错组成。
【解答】
-
动态规划(可空间压缩)
首先,假设 str1 的长度为 M,str2 的长度为 N,aim 如果是 str1 和 str2 的交错组成,aim 的长度一定是 M+N,否则直接返回 false。然后生成大小为(M+1)×(N+1)布尔类型的矩阵 dp,dp[i] [j]的值代表aim[0…i+j-1]能否被 str1[0…i-1]和 str2[0…j-1]交错组成。计算 dp 矩阵的时候,是从左到右,再从上到下计算的,dp[M] [N]也就是 dp 矩阵中最右下角的值,表示 aim 整体能否被 str1 整体和 str2 整体交错组成,也就是最终结果。下面具体说明 dp 矩阵每个位置的值是如何计算的。
1.dp[0] [0]=true。aim 为空串时,当然可以被 str1 为空串和 str2 为空串交错组成。
2.矩阵 dp 第一列即 dp[0…M-1] [0]。dp[i] [0]表示 aim[0…i-1]能否只被 str1[0…i-1]交错组成。如果 aim[0…i-1]等于 str1[0…i-1],则令 dp[i] [0]=true,否则令 dp[i] [0]=false。
3.矩阵 dp 第一行即 dp[0] [0…N-1]。dp[0] [j]表示 aim[0…j-1]能否只被 str2[0…j-1]交错组成。如果 aim[0…j-1]等于 str1[0…j-1],则令 dp[0] [j]=true,否则令 dp[0] [j]=false。
4.对其他位置(i,j),dp[i] [j]的值由下面的情况决定。
- dp[i-1] [j]代表 aim[0…i+j-2]能否被 str1[0…i-2]和 str2[0…j-1]交错组成,如果可以,那么如果再有 str1[i-1]等于 aim[i+j-1],说明 str1[i-1]又可以作为交错组成 aim[0…i+j-1]的最后一个字符。令 dp[i] [j]=true。
- dp[i] [j-1]代表 aim[0…i+j-2]能否被 str1[0…i-1]和 str2[0…j-2]交错组成,如果可以,那么如果再有 str2[j-1]等于 aim[i+j-1],说明 str2[j-1]又可以作为交错组成 aim[0…i+j-1]的最后一个字符。令 dp[i] [j]=true。
- 如果第 1 种情况和第 2 种情况都不满足,令 dp[i] [j]=false。
【代码】
#include 龙与地下城游戏问题
【题目】
给定一个二维数组 map,含义是一张地图,例如,如下矩阵:
-2 -3 3
-5 -10 1
0 30 -5
游戏的规则如下:
- 骑士从左上角出发,每次只能向右或向下走,最后到达右下角见到公主。
- 地图中每个位置的值代表骑士要遭遇的事情。如果是负数,说明此处有怪兽,要让骑士损失血量。如果是非负数,代表此处有血瓶,能让骑士回血。
- 骑士从左上角到右下角的过程中,走到任何一个位置时,血量都不能少于 1。
为了保证骑士能见到公主,初始血量至少是多少?根据 map,返回初始血量。
【解答】
-
动态规划(可空间压缩)
定义和地图大小一样的矩阵,记为 dp,dp[i] [j]的含义是如果骑士要走上位置(i,j),并且从该位置选一条最优的路径,最后走到右下角,骑士起码应该具备的血量。根据 dp 的定义,我们最终需要的是 dp[0] [0]的结果。以题目的例子来说,map[2] [2]的值为-5,所以骑士若要走上这个位置,需要 6 点血才能让自己不死。同时位置(2,2)已经是最右下角的位置,即没有后续的路径,所以 dp[2] [2]==6。
那么 dp[i] [j]的值应该怎么计算呢?
骑士还要面临向下还是向右的选择,dp[i] [j+1]是骑士选择当前向右走并最终达到右下角的血量要求。同理,dp[i+1] [j]是向下走的要求。如果骑士决定向右走,那么骑士在当前位置加完血或者扣完血之后的血量只要等于 dp[i] [j+1]即可。骑士在加血或扣血之前的血量要求(也就是在没有踏上(i,j)位置之前的血量要求),就是 dp[i] [j+1]-map[i] [j]。同时,骑士血量要随时不少于 1,所以向右的要求为 max{dp[i] [j+1]-map[i] [j],1}。如果骑士决定向下走,分析方式相同,向下的要求为 max{dp[i+1] [j]-map[i] [j],1}。
骑士可以有两种选择,当然要选最优的一条,所以 dp[i] [j]=min{向右的要求,向下的要求}。计算 dp 矩阵时从右下角开始计算,选择依次从右至左,再从下到上的计算方式即可。
【代码】
#include 数字字符串转换为字母组合的种数
【题目】
给定一个字符串 str,str 全部由数字字符组成,如果 str 中某一个或某相邻两个字符组成的子串值在 1~26 之间,则这个子串可以转换为一个字母。规定"1"转换为"A",“2"转换为"B”,“3"转换为"C”……“26"转换为"Z”。写一个函数,求 str 有多少种不同的转换结果,并返回种数。
例如:
str=“1111”。
能转换出的结果有"AAAA"、“LAA”、“ALA”、“AAL"和"LL”,返回 5。
str=“01”。
"0"没有对应的字母,而"01"根据规定不可转换,返回 0。
str=“10”。
能转换出的结果是"J",返回 1。
【解答】
-
法一:暴力递归
假设 str 的长度为 N,先定义递归函数 p(i)(0≤i≤N)。p(i)的含义是 str[0…i-1]已经转换完毕,而 str[i…N-1]还没转换的情况下,最终合法的转换种数有多少并返回。特别指出,p(N)表示 str[0…N-1](也就是 str 的整体)都已经转换完,没有后续的字符了,那么合法的转换种数为 1,即 p(N)=1。比如,str=“111123”,p(4)表示 str[0…3](即"1111")已经转换完毕,具体结果是什么不重要,反正已经转换完毕并且不可变,没转换的部分是 str[4…5](即"23"),可转换的只有两种,即"BC"或"W",所以 p(4)=2。p(6)表示 str 整体已经转换完毕,所以 p(6)=1。那么p(i)如何计算呢?只有以下四种情况。
- 如果 i=N。根据上文对 p(N)=1 的解释,直接返回 1。
- 如果不满足情况 1,又有 str[i]=‘0’。str[0…i-1]已经转换完毕,而 str[i…N-1]此时又以’0’开头,str[i…N-1]无论怎样都不可能合法转换,所以直接返回 0。
- 如果不满足情况 1 和情况 2,说明 str[i]属于’1’ ~ ‘9’,str[i]可以转换为’A’ ~ ‘I’,那么 p(i)的值一定包含 p(i+1)的值,即 p(i)=p(i+1)。
- 如果不满足情况 1 和情况 2,说明 str[i]属于’1’~‘9’,如果又有 str[i…i+1]在"10”" ~ "26"之间,str[i…i+1]可以转换为’J’ ~ ‘Z’,那么 p(i)的值一定也包含 p(i+2)的值,即 p(i)+=p(i+2)。
-
法二:非递归
研究一下递归函数 p 就会发现,p(i)最多依赖 p(i+1)和 p(i+2)的值,这是可以从后往前进行顺序计算的,也就是先计算 p(N)和 p(N-1),然后根据这两个值计算 p(N-2),再根据 p(N-1)和 p(N-2)计算 p(N-3),最后根据 p(1)和 p(2)计算出 p(0)即可。类似斐波那契数列的求解过程,只不过斐波那契数列是从前往后计算的,这里是从后往前计算而已。但是本题并不是严格的 f(i)=f(i-1)+f(i-2),str[i]的具体情况决定了 p(i)是等于 0 还是等于 p(i+1)或 p(i+1)+p(i+2),所以无法使用矩阵乘法的方法。
【代码】
- 法一
#include - 法二
#include 表达式得到期望结果的组成种数
【题目】
给定一个只由 0(假)、1(真)、&(逻辑与)、|(逻辑或)和^(异或)五种字符组成的字符串 express,再给定一个布尔值 desired。返回 express 能有多少种组合方式,可以达到 desired的结果。
例如:
express=“1^0|0|1”,desired=false。
只有 1^((0|0)|1)和 1^(0|(0|1))的组合可以得到 false,返回 2。
express=“1”,desired=false。
无组合则可以得到 false,返回 0。
【解答】
-
法一:暴力递归
首先应该判断 express 是否符合题目要求,比如"1^“和"10”,都不是有效的表达式。总结起来有以下三个判断标准:
- 表达式的长度必须是奇数。
- 表达式下标为偶数位置的字符一定是’0’或者’1’。
- 表达式下标为奇数位置的字符一定是’&‘、’|‘或’^'。只要符合上述三个标准,表达式必然是有效的。
在判断 express 符合标准之后,将 express 划分成左右两部分,求出各种划分的情况下,能得到 desired 的种数是多少。以本题的例子进行举例说明,express 为"1^0|0|1",desired 为 false,总的种数求法如下:
- 第 1 个划分为’ ^ ',左部分为"1",右部分为"0|0|1",因为当前划分的逻辑符号为^,所以要想在此划分下得到 false,包含的可能性有两种:左部分为真,右部分为真;左部分为假,右部分为假。结果 1 = 左部分为真的种数 × 右部分为真的种数 + 左部分为假的种数 × 右部分为假的种数。
- 第 2 个划分为’ | ',左部分为"1^0",右部分为"0|1",因为当前划分的逻辑符号为|,所以要想在此划分下得到 false,包含的可能性只有一种,即左部分为假,右部分为假。结果 2 = 左部分为假的种数 × 右部分为假的种数。
- 第 3 个划分为’ | ',左部分为"1^0|0",右部分为"1",因为当前划分的逻辑符号为|,所以结果 3 = 左部分为假的种数 × 右部分为假的种数。
- 结果 1+结果 2+结果 3 就是总的种数。也就是说,一个字符串中有几个逻辑符号,就有多少种划分,把每种划分能够得到最终 desired 值的种数全加起来,就是总的种数。
现在系统地总结一下划分符号和 desired 的情况。
① 划分符号为^、desired 为 true 的情况下:种数 = 左部分为真的种数 × 右部分为假的种数 + 左部分为假的种数 × 右部分为真的种数。
② 划分符号为^、desired 为 false 的情况下:种数 = 左部分为真的种数 × 右部分为真的种数 + 左部分为假的种数 × 右部分为假的种数。
③ 划分符号为&、desired 为 true 的情况下:种数 = 左部分为真的种数 × 右部分为真的种数。
④ 划分符号为&、desired 为 false 的情况下:种数 = 左部分为真的种数 × 右部分为假的种数 + 左部分为假的种数 × 右部分为真的种数 + 左部分为假的种数 × 右部分为假的种数。
⑤ 划分符号为|、desired 为 true 的情况下:种数 = 左部分为真的种数 × 右部分为假的种数 + 左部分为假的种数 × 右部分为真的种数 + 左部分为真的种数 × 右部分为真的种数。
⑥ 划分符号为|、desired 为 false 的情况下:种数 = 左部分为假的种数 × 右部分为假的种数。
根据如上总结,以 express 中的每一个逻辑符号来划分 express,每种划分都求出各自的种数,再把种数累加起来,就是 express 达到 desired 总的种数。每次划分出的左右两部分递归求解即可。
-
法二:动态规划
如果 express 长度为 N,生成两个大小为 N×N 的矩阵 t 和 f,t[j] [i]表示express[j…i]组成 true 的种数,f[j] [i]表示 express[j…i]组成 false 的种数。t[j] [i]和 f[j] [i]的计算方式还是枚举 express[j…i]上的每种划分。
【代码】
- 法一
#include - 法二
#include 排成一条线的纸牌博弈问题
【题目】
给定一个整型数组 arr,代表数值不同的纸牌排成一条线。玩家 A 和玩家 B 依次拿走每张纸牌,规定玩家 A 先拿,玩家 B 后拿,但是每个玩家每次只能拿走最左或最右的纸牌,玩家 A 和玩家 B 都绝顶聪明。请返回最后获胜者的分数。
例如:
arr=[1,2,100,4]。
开始时,玩家 A 只能拿走 1 或 4。如果玩家 A 拿走 1,则排列变为[2,100,4],接下来玩家 B可以拿走 2 或 4,然后继续轮到玩家 A。如果开始时玩家 A 拿走 4,则排列变为[1,2,100],接下来玩家 B 可以拿走 1 或 100,然后继续轮到玩家 A。玩家 A 作为绝顶聪明的人不会先拿 4,因为拿 4 之后,玩家 B 将拿走 100。所以玩家 A 会先拿 1,让排列变为[2,100,4],接下来玩家 B 不管怎么选,100 都会被玩家 A 拿走。玩家 A 会获胜,分数为 101。所以返回 101。
arr=[1,100,2]。
开始时,玩家 A 不管拿 1 还是 2,玩家 B 作为绝顶聪明的人,都会把 100 拿走。玩家 B 会获胜,分数为 100。所以返回 100。
【解答】
-
法一:暴力递归
定义递归函数 f(i,j),表示如果 arr[i…j]这个排列上的纸牌被绝顶聪明的人先拿,最终能获得什么分数。定义递归函数 s(i,j),表示如果 arr[i…j]这个排列上的纸牌被绝顶聪明的人后拿,最终能获得什么分数。
首先分析 f(i,j),具体过程如下:
1.如果 i=j(即 arr[i…j])上只剩一张纸牌。当然会被先拿纸牌的人拿走,所以返回 arr[i]。
2.如果 i!=j。当前拿纸牌的人有两种选择,要么拿走 arr[i],要么拿走 arr[j]。如果拿走 arr[i],那么排列将剩下 arr[i+1…j]。对当前的玩家来说,面对 arr[i+1…j]排列的纸牌,他成了后拿的人,所以后续他能获得的分数为 s(i+1,j)。如果拿走 arr[j],那么排列将剩下 arr[i…j-1]。对当前的玩家来说,面对 arr[i…j-1]排列的纸牌,他成了后拿的人,所以后续他能获得的分数为 s(i,j-1)。作为绝顶聪明的人,必然会在两种决策中选最优的。所以返回 max{arr[i]+s(i+1,j) , arr[j]+s(i,j-1)}。
然后分析 s(i,j),具体过程如下:
1.如果 i=j(即 arr[i…j])上只剩一张纸牌。作为后拿纸牌的人必然什么也得不到,返回 0。
2.如果 i!=j。根据函数 s 的定义,玩家的对手会先拿纸牌。对手要么拿走 arr[i],要么拿走arr[j]。如果对手拿走 arr[i],那么排列将剩下 arr[i+1…j],然后轮到玩家先拿。如果对手拿走 arr[j],那么排列将剩下 arr[i…j-1],然后轮到玩家先拿。对手也是绝顶聪明的人,必然会把最差的情况留给玩家。所以返回 min{f(i+1,j) , f(i,j-1)}。
-
法二:动态规划
如果 arr 长度为 N,生成两个大小为 N×N 的矩阵 f 和 s,f[i] [j]表示函数 f(i,j)的返回值,s[i] [j]表示函数 s(i,j)的返回值。规定一下两个矩阵的计算方向即可。
【代码】
- 法一
#include - 法二
#include 跳跃游戏
【题目】
给定数组 arr,arr[i]=k 代表可以从位置 i 向右跳 1~k 个距离。比如,arr[2]=3,代表可以从位置 2 跳到位置 3、位置 4 或位置 5。如果从位置 0 出发,返回最少跳几次能跳到 arr 最后的位置上。
例如:
arr=[3,2,3,1,1,4]。
arr[0]=3,选择跳到位置 2;arr[2]=3,可以跳到最后的位置。所以返回 2。
【解答】
-
迭代遍历+贪心
具体过程如下:
1.整型变量 jump,代表目前跳了多少步。整型变量 cur,代表如果只能跳 jump 步,最远能够达到的位置。整型变量 next,代表如果再多跳一步,最远能够达到的位置。初始时,jump=0,cur=0,next=0。
2.从左到右遍历 arr,假设遍历到位置 i。
1)如果 cur≥i,说明跳 jump 步可以到达位置 i,此时什么也不做。
2)如果 cur
3)将 next 更新成 max(next, i+arr[i]),表示下一次多跳一步到达的最远位置。
3.最终返回 jump 即可。
【代码】
#include 数组中的最长连续序列
【题目】
给定无序数组 arr,返回其中最长的连续序列的长度。
例如:
arr=[100,4,200,1,3,2],最长的连续序列为[1,2,3,4],所以返回 4。
【解答】
-
迭代遍历+unordered_map
具体过程如下:
1.生成哈希表 unordered_map
2.从左到右遍历 arr,假设遍历到 arr[i]。如果 arr[i]之前出现过,直接遍历下一个数,只处理之前没出现过的 arr[i]。首先在 map 中加入记录(arr[i],1),代表目前 arr[i]单独作为一个连续序列。然后看 map 中是否含有 arr[i]-1,如果有,则说明 arr[i]-1 所在的连续序列可以和 arr[i]合并,合并后记为 A 序列。利用 map 可以得到 A 序列的长度,记为 lenA,最小值记为 leftA,最大值记为 rightA,只在 map 中更新与 leftA 和 rightA 有关的记录,更新成(leftA,lenA)和(rightA,lenA)接下来看 map 中是否含有 arr[i]+1,如果有,则说明 arr[i]+1 所在的连续序列可以和 A 合并,合并后记为 B 序列。利用 map 可以得到 B 序列的长度为 lenB,最小值记为 leftB,最大值记为 rightB,只在 map 中更新与 leftB 和 rightB 有关的记录,更新成(leftB,lenB)和(rightB,lenB)。
3.遍历过程中用全局变量 maxValue 记录每次合并出的序列的长度最大值,最后返回 maxValue。整个过程中,只是每个连续序列最小值和最大值在 map 中的记录有意义,中间数的记录不再更新,因为再也不会使用到。这是因为我们只处理之前没出现的数,如果一个没出现的数能够把某个连续区间扩大,或把某两个连续区间连在一起,毫无疑问,只需要 map 中有关这个连续区间最小值和最大值的记录。
【代码】
#include N 皇后问题
【题目】
N 皇后问题是指在 N×N 的棋盘上要摆 N 个皇后,要求任何两个皇后不同行、不同列,也不在同一条斜线上。给定一个整数 n,返回 n 皇后的摆法有多少种。
例如:
n=1,返回 1。
n=2 或 3,2 皇后和 3 皇后问题无论怎么摆都不行,返回 0。
n=8,返回 92。
【解答】
-
法一:暴力递归
如果在(i,j)位置(第 i 行第 j 列)放置了一个皇后,接下来在哪些位置不能放置皇后呢?
1.整个第 i 行的位置都不能放置。
2.整个第 j 列的位置都不能放置。
3.如果位置(a,b)满足|a-i|=|b-j|,说明(a,b)与(i,j)处在同一条斜线上,也不能放置。
把递归过程直接设计成逐行放置皇后的方式,可以避开条件 1 的那些不能放置的位置。接下来用一个数组保存已经放置的皇后位置,假设数组为 record,record[i]的值表示第 i 行皇后所在的列数。在递归计算到第 i 行第 j 列时,查看 record[0…k](k
-
法二:位运算+递归
变量 upperLim 表示当前行哪些位置是可以放置皇后的,1 代表可以放置,0代表不能放置。8 皇后问题中,初始时 upperLim 为 00000000000000000000000011111111,即32 位整数的 255。32 皇后问题中,初始时 upperLim 为 11111111111111111111111111111111,即 32 位整数的-1。
接下来解释一下递归方法,先介绍每个参数。
- upperLim:已经解释过了,而且这个变量的值在递归过程中是始终不变的。
- colLim:表示递归计算到上一行为止,在哪些列上已经放置了皇后,1 代表已经放置,0 代表没有放置。
- leftDiaLim:表示递归计算到上一行为止,因为受已经放置的所有皇后的左下方斜线的影响,导致当前行不能放置皇后,1 代表不能放置,0 代表可以放置。举个例子,如果在第 0 行第 4 列放置了皇后,计算到第 1 行时,第 0 行皇后的左下方斜线影响的是第 1 行第 3 列。当计算到第 2 行时,第 0 行皇后的左下方斜线影响的是第 2 行第 2 列。当计算到第 3 行时,影响的是第 3 行第 1 列。当计算到第 4 行时,影响的是第 4 行第0 列。当计算到第 5 行时,第 0 行的那个皇后的左下方斜线对第 5 行无影响,并且之后的行都不再受第 0 行皇后左下方斜线的影响。也就是说,leftDiaLim 每次左移一位,就可以得到之前所有皇后的左下方斜线对当前行的影响。
- rightDiaLim:表示递归计算到上一行为止,因为已经受放置的所有皇后的右下方斜线的影响,导致当前行不能放置皇后的位置,1 代表不能放置,0 代表可以放置。与leftDiaLim 变量类似,rightDiaLim 每右移一位,就可以得到之前所有皇后的右下方斜线对当前行的影响。
递归方法的返回值代表剩余的皇后在之前皇后的影响下,有多少种合法的摆法。其中,变量 pos 代表当前行在 colLim、leftDiaLim 和 rightDiaLim 这三个状态的影响下,还有哪些位置是可供选择的,1 代表可以选择,0 代表不能选择。变量 mostRightOne 代表在 pos 中,最右边的 1在什么位置。然后从右到左依次筛选出 pos 中可选择的位置进行递归尝试。
【代码】
- 法一
#include - 法二
#include