You Only Look Once: Unified, Real-Time Object Detection(Yolov1) 论文详细解读
目录
- 前言
- 1. 简介
- 2. 思想设计
- 3. 模型设计
-
- 3.1 网络
- 3.2 训练
- 3.3 预测
- 4. 实验结果
前言
研究目标检测相关的论文,将其文章梳理总结如下
对应的ppt展示可看我这资源:You Only Look Once: Unified, Real-Time Object Detection
目标检测主要分为两类
- Region Proposal的R-CNN系(R-CNN、Fast R-CNN、Faster R-CNN)。两个阶段
- YOLO、SSD。一个阶段
所谓的两阶段与一阶段
两个阶段:将其图片使用启发式或者CNN产生Region Proposal,在对其分类回归
一个阶段:将其图片使用CNN输出类别与位置
1. 简介
原本人类看一眼图像,就可知道图像在表达什么。目前的目标检测系统利用分类器进行检测,对该物体的分类器进行评估,并测试图像不同位置和比例的测试图像进行评估。
Rcnn在图像中生成潜在的边界框,然后通过分类器来完善边界框消除重复的检测,对其进行评分。基于场景的各个物体,每个都需要进行训练优化。
原本利用分类器进行检测,现在把物体检测看做一个回归问题,将其分离为相关的类别概率。
直接从一副完整的图像中预测出边界框和类别概率,整个预测都是单一的网络,可直接根据预测进行端到端的优化。
也就直接从图像像素到边界框坐标和类别概率,使用YOLO即可预测物体的存在以及位置
卷积网络可同时预测多个边界框以及每个框的类别概率。
与传统的检测相比较有以下好处:
- yolo的基本网络运行速度为45帧/秒(速度快)
- 平均精度是其他实时系统的两倍以上(精度高),rcnn是一种顶部预测方法,会把图像中的背景误认为物体
进行预检测是对图像进行全局推理,不同于滑动窗口和区域技术,yolo在训练和预测可看到整个图像(隐含编码了关于类别以及它们外观的上下文信息)
补充滑动窗口
此处文章中提到的滑动窗口(补充讲解),类似leetcode的滑动窗口题,不过这是数组的滑动,以下是图形的滑动:239. 滑动窗口最大值
图像中的滑动窗口思路如下:
采用不同长宽的图以及步长在图片中进行滑动,但限定于图片目标规模以及不同窗口、步长,而且计算量很大(可能有些区域没有目标,也在计算)。为了减少计算量而且保证步长,专门减少一些区域,可以使用Selective Search,这个方法主要有三个优势: 捕捉不同尺度(Capture All Scales)、多样化(Diversification)、快速计算(Fast to Compute)。来提升效率过滤无用的子区域。
卷积就有点类似滑动窗口的思想,图片的空间位置信息不变性
yolo为了解决只限定窗口大小以及步长,不采用滑动窗口,将其原始图片分割为格子,通过卷积产生特征图,每个特征图也代表该物体是否在格子内。
2. 思想设计
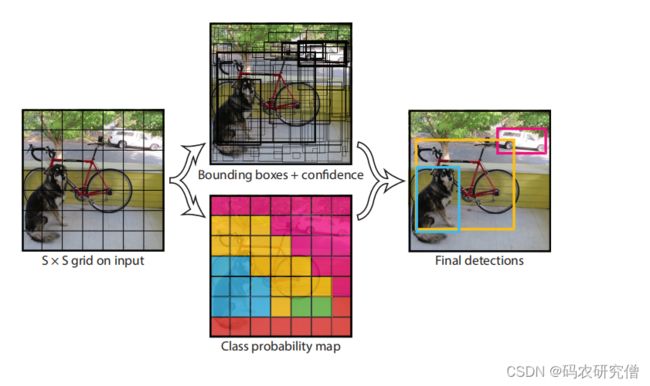
从文章的这个图片也可看出,这和以前的 faster rcnn有所区别
yolo是一个阶段,端对端的目标检测

大致的意思:
- 将图像压缩为448*448
- 将图像运行在单个卷积网络,端到端输入到输出
- 将其结果阈值设置为模型的置信度
将其物体的独立组件都统一到单一的神经网络,利用其网络对其整个图像预测每个边框之值,还可预测一个图像中所有类别的边界框。(从此处可看出对整个图像中的所有物体进行了全局推理)
之所以可以保证高精度以及高速度,具体原因如下:
- 将其图像限定为S*S的网格。一个物体中心落入网格,该网络负责检测该物体。
- 每个网格可预测出B个边界框和这些框的置信度(其置信度反映对物体的准确度)
将其准确度定义如下:

IOU为预测框和实际框的交集,每个预测款都由5个值组成(x、y、w、h、confidence),xy坐标相对于框中心下的,宽度高度同理。每个网格单元还预测了C类的条件概率Pr(Classi|Object),这些概率以包含一个物体的网格单元为条件的。
这主要是置信度定义的由来
- 格子是否包含目标,由Pr(Object)概率确定,要么有为1,要么没有为0
- 格子是否预测准确(与真实框相比较),通过IOU这个交并比区分
具体边界框大小与位置由如下参数确定:(x,y,w,h,c)。xywh都限定在了0与1的范围内
- xy相对于每个框的坐标进行偏移,此xy对应的是框的中心偏移量
- wh是每个框的宽与高
- c为框的置信度
上面的公式还有些不合理之处。单算单元格预测出的边界框是否有该物体还不大行,每个单元格还要预测出C类别概率。对此需要将其概率预测值和边界框结合在一起。类似先验概率,预测出该物体是否存在以及该物体中出现该类别的概率以及IOU交并比(三者是相乘关系)。该单元格没有物体,则置信度分数为0。
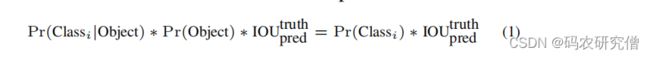
通过这个公式,可以看到涉及两个回归问题
一个是有物体上的概率,通过是否有物体来预测
一个是交并比的问题,后期会设置一个IOU阈值大小决定预测的问题
总体算下来
每个单元格为:(B∗5+C)
图片总体张量为:S×S×(B∗5+C)张量
该论文是只预测在PASCAL VOC上评估YOLO时,我们使用S=7,B=2。PASCAL VOC有20个标记的类,所以C=20。我们的最终预测是一个7×7×30的张量。
3. 模型设计
3.1 网络
使用的数据集为:PASCAL VOC
利用网络的初始卷积层从图像中提取该特征,利用全连接层预测输出概率以及坐标。
网络结构参考了GoogleNet,有24个卷积层,2个全连接层
具体YOLO的模型如下:
卷积层 主要使用11的卷积以及33的卷积,大的卷积层以及全连接使用了Leaky ReLU激活函数。最后一层使用线性激活函数。

训练了一个快速版本的YOLO(快速版本卷积层为9层。每个层都由较少的过滤器,其他训练以及测试参数都是一样的),为推动快速物体检测的边界
7764 64个卷积核,步长为2
3.2 训练
使用ImageNet预训练卷积层,对于预训练,使用前20个卷积层、average-pool、全连接层,训练了一个星期。
之后在前20个卷积层中添加了四个卷积层以及两个全连接层,并随机初始化了权重,将其分辨率调整为448*448(考虑更加好的分辨参数)。
对应将其边界框的x y 宽 高限定在了0 和 1的偏移,最后一层使用了线性激活函数,其他层次使用了leaky的线性函数。
训练过程中的损失函数分析如下:
在每张图像中,许多网格单元不包含任何物体,导致一些格子的信心分数以及置信度分数趋于0。解决这一问题,增加边界值以及坐标预测的损失,减少 不包含物体边框的 置信度的预测损失。
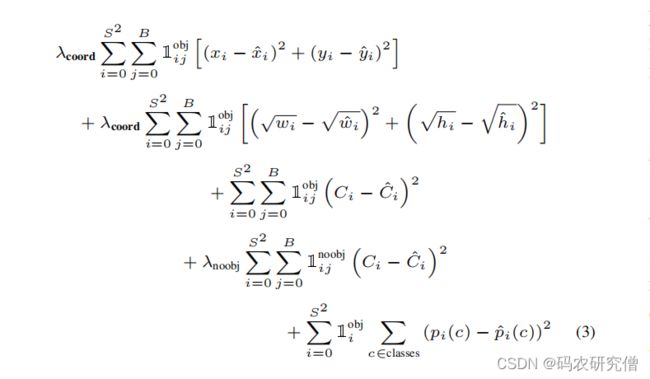
对应的参数如下:
- 中心坐标误差
- 宽高误差
- 包含边界框置信度误差
- 不包含边界框置信度误差
- 包含目标分类误差
回归问题采用了均方差的损失函数,
- 方差计算不同:之所以xy与wh不一样的计算方式,因为小边界框的坐标误差比大边界框的坐标误差要反应大,所以wh对其平方根
- 权重不同:对应λcoord为定位误差,所以使用了较大的权重(为5),对应λnoobj为分类误差,使用较小的权重(为0.5)
为了提高性能,显示边界框更加的专业化,一个格子有多个边界框,但类别只有一个,最多只有一个边界框只有该类别,其他边界框不能有该类别。不存在目标的边界框,损失的误差只有置信度C。
yolo预测了每个网格单元的多个边界框,在训练的时候,只希望一个边界框来负责每个对象,依据是预测与真是的IOU是最高的,这样的预测器可以更好的预测尺寸、长宽以及物体的类别,来提高整体的召回率。
对应这句话的解读:

对象i是否出现在单元格i中 以及 i单元格中的第j个边界框预测器对该预测框进行预测
损失函数只是对分类错误进行惩罚(只是惩罚边界框中的坐标错误)
训练的过程中,批次64,动量0.9,衰减为0.0005,学习率有10-3到10-2(为了防止不稳定,一般都是从低到高)
yolo的预训练比较快,不像分类器
3.3 预测
非极大抑制(NMS)消除重复检测
对网络单元进行空间限制,有助于减少同一物体的多次检测
具体思路如下:从所有检测框中找出最大的置信度,挨个计算与其它框的交并比,如果该值大于最大的置信度,则将其筛选掉(重合度高)
其他快速检测器 Fast和Faster R-CNN,专注于通过共享计算和使用神经网络,来提出区域而不是选择性搜索来加快R-CNN框架的速度
总共预测的框个数(论文 7 * 7 ):7 * 7 * 2 = 98
也就是有98个边界框,将其小于置信度的置为0。按照类别对其对其置信度采用非极大值抑制,对应将其不符合的置信度置为0(与最大的置信度进行交并比筛选)
4. 实验结果
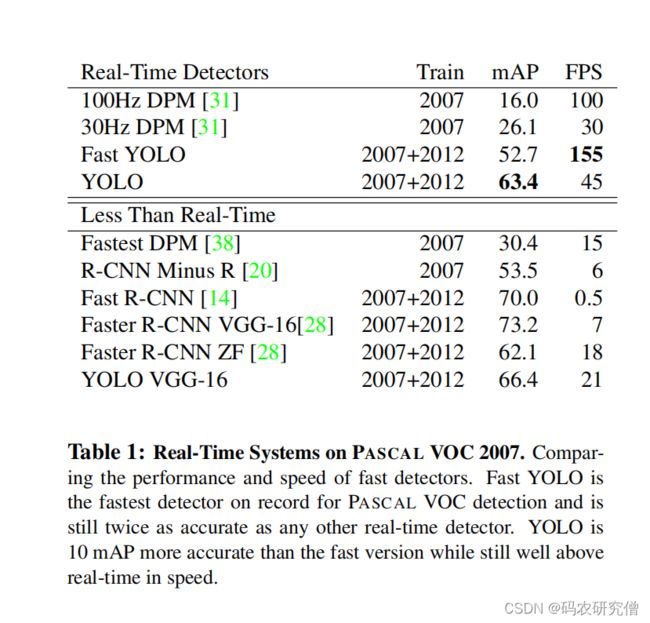
YOLO与其它检测算法进行比较如下:
误差分析如下:
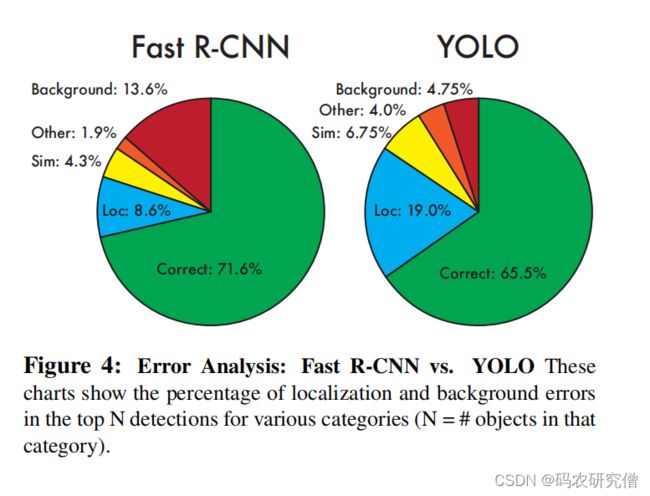
- Correct(准确度):类别正确,IOU>0.5;
- Localization(定位不准):类别正确,0.1 < IOU<0.5
- Similar:类别相似,IOU>0.1
- Other:类别错误,IOU>0.1
- Background(背景当物体):任何目标,IOU<0.1
缺点:
- 每个网格两个边界框,如果物体长宽不确定,性能差
- 物体很靠近很密集,性能差
- 每个网格有多个物体,性能差
- 小物体,性能差
小物体的改进可以使用多尺度单元格,类似的框架有SSD、Faster R-CNN