TensorRT学习(2):使用C++API构建引擎
TensorRT学习(1) 使用C++API构建引擎
1. tensorrt轮子代码示例
首先我们先将tensorRT的函数简单封装一下,方便后面搭建网络,以下为部分示例:
// size() 获取张量形状
static vector<int> trt_size(ITensor *input) {
auto shape = input->getDimensions().d;
auto dim_num = input->getDimensions().nbDims;
vector<int> d(dim_num, 0);
for (int i = 0; i < dim_num; ++i)
d[i] = shape[i];
return d;
}
// matmul() transpose为true则表示在乘法前先进行转置
static ITensor* trt_matmul(INetworkDefinition *network, ITensor *input1, bool transpose1, ITensor *input2, bool transpose2) {
return network->addMatrixMultiply(*input1, transpose1, *input2, transpose2)->getOutput(0);
}
// 张量切片 后三个参数依次为切片开始时各维度的索引、切片完成后张量的形状以及切片时各维度的步长
static ITensor* trt_slice(INetworkDefinition *network, ITensor *input, Dims start, Dims size, Dims step){
return network->addSlice(*input, start, size, step)->getOutput(0);
}
// view() 不可乱用,张量填充是最后一个维度对应填充,会导致数据混乱,所以一定要确保数据对应后在填充(先做维度变换) 例如:(n,c)->(c,1,n),应该先(n,c)->(c,n),然后(c,n)->(c,1,n)
static ITensor* trt_view(INetworkDefinition *network, ITensor *input, Dims dims){
IShuffleLayer *reshape = network->addShuffle(*input);
reshape->setReshapeDimensions(dims);
return reshape->getOutput(0);
}
// transpose() 维度变换
static ITensor* trt_transpose(INetworkDefinition *network, ITensor *input, Permutation pmt){
IShuffleLayer *premute = network->addShuffle(*input);
premute->setFirstTranspose(pmt);
return premute->getOutput(0);
}
// softmax()
static ITensor* trt_softmax(INetworkDefinition *network, ITensor *input, int axes) {
auto sm = network->addSoftMax(*input);
sm->setAxes(axes);
return sm->getOutput(0);
}
// 对张量做一元运算,如取对数、绝对值、三角函数等
static ITensor* trt_unary(INetworkDefinition *network, ITensor *input, UnaryOperation op) {
return network->addUnary(*input, op)->getOutput(0);
}
// log_softmax()
static ITensor* trt_log_softmax(INetworkDefinition *network, ITensor *input, int axes) {
input = trt_softmax(network, input, axes);
return trt_unary(network, input, UnaryOperation::kLOG);
}
// cat() 多个张量进行拼接,所有张量的dimisions必须相同!即一个2*3*4,其它也得是2*3*4
static ITensor* trt_cat(INetworkDefinition *network, vector<ITensor *> inputs, int axis){
int num_inputs = inputs.size();
ITensor** input = new ITensor*[num_inputs];
for (int i = 0; i < num_inputs; i++)
input[i] = inputs[i];
IConcatenationLayer *cat = network->addConcatenation(input, num_inputs);
cat->setAxis(axis);
return cat->getOutput(0);
}
// T = (scale * T + shift) ^ power T至少三个维度
static ITensor* trt_scale(INetworkDefinition *network, ITensor *input, ScaleMode sm, Weights &shift, Weights &scale, Weights &power) {
return network->addScale(*input, sm, shift, scale, power)->getOutput(0);
}
// 对张量进行某个维度求最值,求和等操作。 reduceAxes采用的是bitmask表示法,下方max()为一个示例
static ITensor* trt_reduce(INetworkDefinition *network, ITensor *input, uint32_t reduceAxes, ReduceOperation op, bool keepDims){
/* 若TRT的输入是 C * H * W
*reduceAxes W H C
* 0X01 0 0 1
* 0X02 0 1 0
* 0X03 0 1 1
* 0X04 1 0 0
* 0X05 1 0 1
* 0X06 1 1 0
* 0X07 1 1 1
*/
return network->addReduce(*input, op, reduceAxes, keepDims)->getOutput(0);
}
// max()
static ITensor* trt_max(INetworkDefinition *network, ITensor *input, uint32_t reduceAxes, bool keepDims) {
/* 若TRT的输入是 C * H * W
*reduceAxes W H C
* 0X01 0 0 1
* 0X02 0 1 0
* 0X03 0 1 1
* 0X04 1 0 0
* 0X05 1 0 1
* 0X06 1 1 0
* 0X07 1 1 1
*/
return network->addReduce(*input, ReduceOperation::kMAX, reduceAxes, keepDims)->getOutput(0);
}
// 常量层
static ITensor* trt_constant(INetworkDefinition *network, Dims dims, float *wgt, int count){
Weights weights{ DataType::kFLOAT,wgt,count };
return network->addConstant(dims, weights)->getOutput(0);
}
// 激活层
static ITensor* trt_act(INetworkDefinition *network, ITensor *input, ActivationType op) {
return network->addActivation(*input, op)->getOutput(0);
}
// relu()
static ITensor* trt_relu(INetworkDefinition *network, ITensor *input) {
return trt_act(network, input, ActivationType::kRELU);
}
还有很多其它层的写法就不展示了,感兴趣的同学可以看这位大佬的github:tensorRT_Wheels.
2. 创建项目
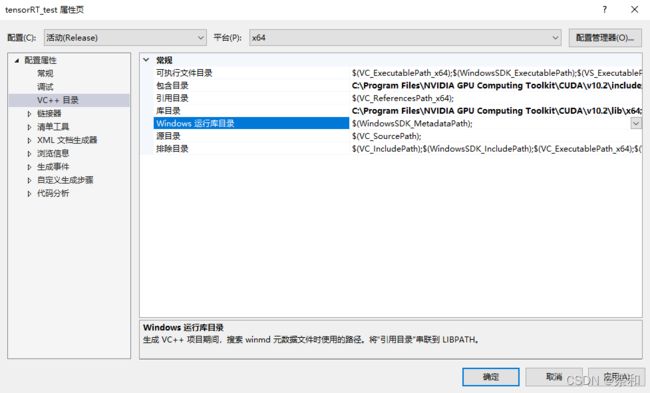
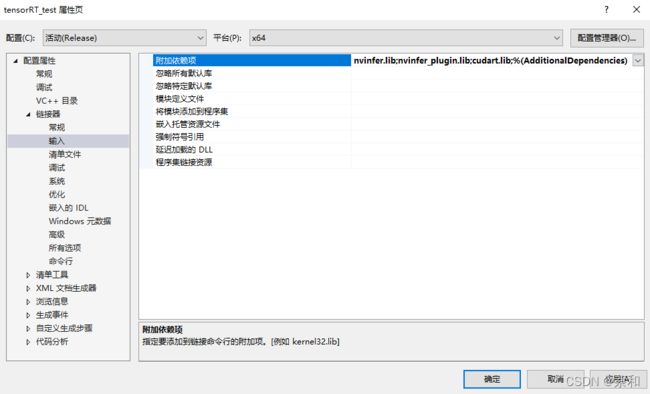
打开项目属性页,添加所需包含目录、库目录以及链接器输入。
包含目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
库目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
链接器输入:nvinfer.lib nvinfer_plugin.lib cudart.lib
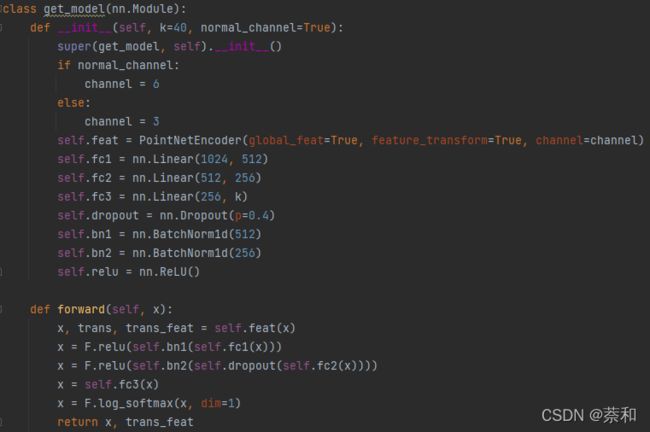
3. 构建engine(以pointNet为例)
-
使用 C++ API 搭建pointNet网络
模仿pointNet分类的python代码,编写出C++版本的pointNetCla类,以下为部分代码对比:
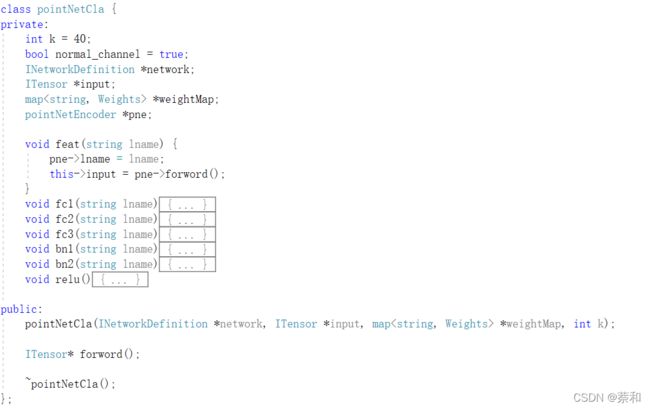
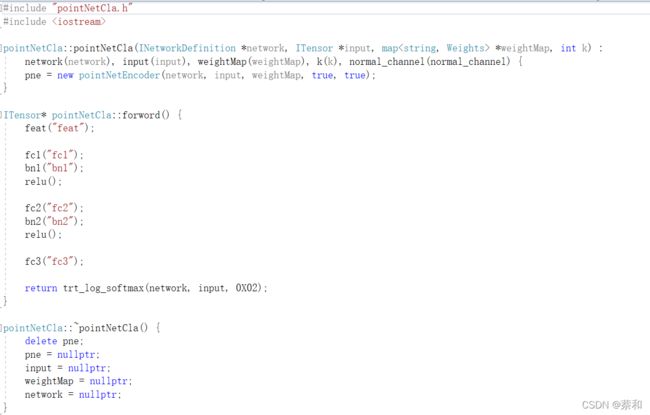
-
加载权重文件(如不了解wts文件结构,可参考上篇文章)
std::map<std::string, Weights> loadWeights(const std::string file) {
std::cout << "加载权重文件: " << file << std::endl;
std::map<std::string, Weights> weightMap;
std::ifstream input(file);
assert(input.is_open() && "无法打开文件,请检查文件路径是否正确!");
int count;
input >> std::dec >> count; // 指定读入格式 dec(十进制)
while (count--){
Weights wt{ DataType::kFLOAT, nullptr, 0 };
uint32_t size;
std::string name;
input >> name >> std::dec >> size;
wt.count = size;
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
input >> std::hex >> val[x]; // 指定读入格式 dec(十六进制)
wt.values = val;
weightMap[name] = wt;
}
return weightMap;
}
- 构建引擎文件
// func 表示要构建的是分类还是分割网络
ICudaEngine* createEngine(string wts_name, string func) {
map<string, Weights> &&weightMap = loadWeights(wts_name);
Logger logger;
IBuilder *builder = createInferBuilder(logger);
IBuilderConfig *config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(B * (1 << 20)); // 这个值设置的要大于网络中最大的中间变量占用的空间,否则可能出现无法找到某个函数的实现的情况
builder->setMaxBatchSize(B);
if (use_fp == "USE_FP16")
config->setFlag(BuilderFlag::kFP16);
INetworkDefinition *network = builder->createNetworkV2(1);
// 点云是三维文件,tensorRT默认第四个维度是batchsize的大小,所以给点云升一维
ITensor* input = network->addInput(inputName, DataType::kFLOAT, Dims4{ B, C, N, 1 });
if (func == "cla") {
shared_ptr<pointNetCla> pn_cla = make_shared<pointNetCla>(network, input, &weightMap, K);
input = pn_cla->forword();
}else if (func == "sem") {
shared_ptr<pointNetSem> pn_sem = make_shared<pointNetSem>(network, input, &weightMap, K);
input = pn_sem->forword();
}
input->setName(outputName);
network->markOutput(*input);
cout << "build engine........" << endl;
auto engine = builder->buildEngineWithConfig(*network, *config);
config->destroy();
network->destroy();
builder->destroy();
return engine;
}
- 引擎文件的保存
void saveEngine(ICudaEngine *engine,string engine_name) {
IHostMemory* modelStream = engine->serialize();
engine->destroy();
ofstream ofs(engine_name, ios::binary);
ofs.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
ofs.close();
cout << "save engine successful!" << endl;
modelStream->destroy();
}