此篇博客写作思路是一边翻译英文原文一边总结博主在阅读过程中遇到的问题及一些思考,因为博主本人阅读英文论文水平不高,所以还请大家在看此篇博客的过程中带着批判的眼神阅读!小墨镜带好,有什么不对的地方请在留言指出,大家一起讨论,快乐的搞事情!
Fast R-CNN
Ross Girshick
Microsoft Research
摘要:
本文提出了一种可用于目标检测的基于区域的快速卷积神经网络方法,Fast-RCNN 是对以前使用深度卷积网络进行目标检测工作的一种有效增强!Fast-RCNN有几处牛逼的创新点,可以在大大减少训练和测试时间的同时增加训练精确度,Fast-RCNN训练非常深VGG16的网络,速度比RCNN快9倍,测试速度更是达到了惊人的213倍,在PASCAL VOC2012上实现了比较高的准确度!和SPPnet做比较,我们的Fast-RCNN训练速度达3倍,测试速度达10倍!简直是伟大的突破!
1 介绍
最近,深度卷积神经网络在图像分类任务和目标检测任务上的精确度有了重大提高,相比于图像分类任务,目标检测是一个更具有挑战性的任务!更复杂也更难做,因为复杂的原因,当前多级级联的方法十分慢而且不够机智。
目标检测的复杂性来源于需要精确的确定目标的位置,这就产生了两个极具挑战性的工作,首先,大量的待检测目标需要被处理(后文中统称proposal),其次,待检测目标的位置必须被精确的确定出来,这两个问题的解决常常伴随着速度,精确度或者简化的问题!
本文,我们精简了当前目标检测所用的卷积神经网络!我们提出了单级训练算法将分类和重新确定位置这两个任务级联了起来。
总而言之,我们训练了非常深的目标检测网络(VGG16)它比RCNN快9倍,比SPPnet快3倍,在运行时,检测网络处理图像仅仅需要0.3秒你敢信??哦,其实是不算图片生成待检测proposal目标的时间的啊!
最终我们取得了可喜可贺的成果,在PASCAL VOC2012上大了66%的精确度!比小弟RCNN的62%还精准还快你就说你怕不怕!
1.1R-CNN和SPPnet(常规套路先总结先人不足)
RCNN利用深度卷积网络实现了激动人心的准确率,当然了,它必须存在一些不足:
1 训练是一个多级级联过程
RCNN 微调了ConvNet 在目标检测上使用了log对数损失,然后它使用SVM来分类ConvNet的特征,这样SVM取代了softmax分类器而扮演着目标检测的角色,然后第三级,学习目标所在位置的框框!
2训练在空间和时间上的花费都是昂贵的
对SVM和边界框的训练来说,每一个图片的每一个待检测目标框框都需要提取特征并且写入到硬盘里吗,对于非常深得硬盘来说,这波操作是致命的!
3目标检测太慢了
就像上面说的,每个图片的每个proposal都要被提取特征,这就是RCNN最为致命的地方!所以其实Fast-RCNN的改进主要就是在这个地方借鉴了SPPnet,然后大大节省了时间
综上,目标检测之所以慢,就是因为卷积网络的前向运算对于每个proposal都会计算一次(一张图片可能会产生1k个proposal你想下多逆天!),没有共享计算啊亲,所以SPPnet(空间金字塔池化网络)提出了一个利用共享计算加速RCNN的方法。它只在整张图上利用卷积神经网络进行特征提取,得到关于整张图的特征图!然后利用proposal在图片的区域,进行一次映射,映射到特征图上然后进行proposal特征向量的生成,再送入后续网络,这样的方法省略了大量的重复提取特征的时间,你说能不节省吗!
可能会有同学质疑这种映射操作的可行性!我上图证明一下,(图来自其他博主):

特征图以一种密集的方式表征空间特征!也就是说原图image和特征图确实是相互对应的,用映射的方式来从特征图中选取proposal是可行的!
原文中说SPPNet在测试阶段加速RCNN从10到100X的提升,在训练阶段叶至少提升了3倍之多
不过当然了,SPPNet必然也有它的缺点,(不然作者干嘛要写Fast—RCNN呢) ,比如说,它仍然是一个多级训练过程,包括提取特征,用log的损失函数微调,以及训练SVM分类器和bounding-box的回归问题,就是独立训练这几部分,然后组成一个大的网络,而且它的特征也是存储在硬盘上的,大量浪费空间了,和RCNN不同的是,这种空间金字塔池化层因为加入了池化的关系,它不能够很好的更新池化层之前的卷积神经网络的参数了,这样前面的网络得不到生长,准确性必然会受影响!
1.2贡献部分:
所以总结一下,Fast-RCNN提出了一种新的训练算法有效的修补了RCNN和SPPnet的不足之处,在速度和准确性上面都有所提高,我们之所以称之为Fast-RCNN是因为它相比较而言不论是训练还是测试都更快速,Fast-
RCNN有以下几个优点:
1更高的检测准确率(mAP)
2训练是单级的或者说单通道的,并且使用了多级任务损失
3训练可以更新到整个网络!
4 没有硬盘存储大量特征的需求
接下来的文章自然是主要强调以上四个优点啦!
2 Fast-RCNN的结构以及训练方法

上图介绍了Fast-RCNN的网络结构,它接收整副图像和一系列的proposal作为输入,网络首先做的就是用一些卷积神经网络以及最大值池化层等对图片进行特征提取,然后对每一个proposal,利用感兴趣区域池化层从特征图
中提取出一个特征向量,每一个特征向量会被送进后续的全连接层,这个全连接层在末尾会产生两个分支,一个产生softmax来估计K个类别以及背景的概率(K+1个类别的softmax概率),另外一个层对每一个类别输出四个
实值数据,这四个值会重新确定边界框的位置K,其实这里的四个点就是(x,y,w,h)参考点的位置以及长和宽,这四个参数足够确定一个边界框了!
2.1 The ROI pooling layer
ROI pooling layer 使用最大值池化转换任意的感兴趣区域的特征图到某个固定的大小HxW(比如说7x7),这里的H和W就是传说中的超参数,其实超参数是很容易理解的,在训练之前你就得固定好它,你选取超参数的方法
可能就是你不断的在验证集上做实验,挑表现最好的固定下来,再开始训练优化,本文中,ROI是一个矩形窗口,而且每一个Roi都是由上文中所说的四个参数决定的(x,y,w,h),其中(x,y)是定义在左上角的参照点而这个(h,w)是
对应的矩形框长度和宽度。
Roi max pooling层之所以能够将任意的proposal转化乘固定的HxW区域,其原理是这样的,比如说proposal是h×w这样的,然后你可以按照h/H的高度,w/W的宽度进行切割,那么得到的自然是固定的H×W的参数结果啦~
2.2预训练网络的初始化
本文的作者使用了三个预训练的ImageNet进行实验,每一个都有五个最大池化层和五到十三个的卷积层组成,当这些预训练的网络转化成ImageNet的时候,通常都经历一下三方面的转化:
1首先,最后一层的池化层被Roi池化层取代,而且Roi池化的参数固定为H×W,目的就是为了和后续的全连接层进行匹配
2 网络最后的全连接层和softmax层(原网络训练的是1000类的分类)被替代为两个不同的全连接网络,一个是能够对K+1个种类进行分类的softmax的全连接层,另外是种类对应的边界框(bounding-box)的回归网络
3最后,网络被修改为接收两个输入,分别是整副图像和图像对应的全部的proposal
2.3网络微调
对于Fast-RCNN来说,对整个网络的权重参数进行反向传播训练是Fast-RCNN网络独有的能力!SPPnet网络就不能够更新金字塔池化层前面的卷积网络的参数哦!
为啥呢?为啥SPPnet金字塔池化层之前的网络参数就不能够有效的更新?原文中说了因为反向传播走到金字塔池化层的时候层的效率非常的低当proposal来自于不同的图片的时候,PS:好像在我的感觉里池化这种操作
确实不是很容易能够用函数式进行表示,就算表示出来了,那也肯定不是连续函数吧,也会很难求导,但这都不是主要的,主要原因是来自于不同的图片的proposal就会让反向求导操作的效率十分低下!
因为每一个Roi都有可能从图像的不同地方获取,这样它就对应着一个十分大的接收场(我把它理解为定义域),甚至有可能是来自于整副图像,所以前向传输计算过程中,必须要处理整副图像,这个训练输入是十分大的!
那作者是怎么解决这个问题的呢? 作者充分利用训练过程中的特征图共享的有点,在Fast-RCNN的训练过程中,SGD的mini-batch是分层次的采样,假设一共寻要R个proposal,那么我们首先采样N张图片,然后再
每张图片采样R/N个proposal,然后让来自于同一张图片的的proposal共享计算和内存在前向和后向传播过程中!作者举了个例子,当使用N=2,R=128的时候,利用这种方法训练速度是采样来自128张不同图片的Roi的速度
的128倍!,真的是快的一逼啊!
但是这样也可能会有一些小问题,比如说,来自于同一张图片的Roi可能具有很大的相关性,会严重托慢训练速度,但是这个问题在作者的训练过程中没有造成什么严重的后果,然后作者使用更少的SGD迭代次数也
得到了比RCNN更好的训练结果。
除了分层采样之外,作者还有一个小trick,那就是将网络全连接层后面的两个网络进行了联合优化,也就是将sotfmax分类器和边界框回归网络进行联合优化,而不是分开来softmax Classficaiton ,SVM,边界框回归器
一个个的挨个优化!
多任务损失
一个Fast-RCNN的网络有两个不同的输出层,一个输出离散概率分布,Ρ=(p0,......pk),overK+1个类别,和其他的网络类似,也是通过softmax来计算k+1个输出种类的概率,第二个输出的是边界框的回归偏置Tk=(tx,ty,tw,th),对
k个种类中的每一个类别都是如此,而且tk指定了空间尺度不变性的转换和对数空间的宽高的平移,对每一个proposal都是如此
每一个用于训练的Roi都有一个真实的类标记u和一个确切可靠的边界回归框v,我们使用多任务损失L来对分类和边界框进行联合优化训练:
![]()
在这个公式中 :![]() 代表的是真实类别的对数损失,很可靠,如果pu越小,那么logpu就会越趋向于负无穷,添加负号之后,就对应的越大!概率越小,惩罚越大,是损失函数的常规套路,
代表的是真实类别的对数损失,很可靠,如果pu越小,那么logpu就会越趋向于负无穷,添加负号之后,就对应的越大!概率越小,惩罚越大,是损失函数的常规套路,
至于回归任务的损失函数就比较麻烦,介绍之前先说一个超参数λ,这个是训练之前指定的,表明分类和回归的重要性程度,本文中都是设置为1,损失函数肯定是有目标target和预测它们分别是:
边界框通过神经网络算出的参数:![]()
人为标定的真实边界框的参数: ![]()
![]()
这样,边界框的的损失函数可以定义为: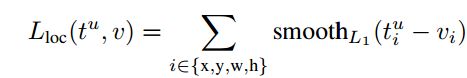
而这个smoothL1函数的定义如下: 
这样这个多级任务损失函数就定义完了,我知道你们肯定想看图像,我用wolframAlpha画出来了,好像其实和2次函数的图像没什么区别嘛,大家可以仔细考虑一下作者这样定义的意图。
作者说这样是一个稳健的L1损失,相对于L2损失而言它对离群的值并不敏感在RCNN和SPPnet中,因为回归训练是没有边界的,所以你必须要小心的设置学习率避免梯度爆炸,哈哈哈哈
Mini-batch sampling
在微调过程中,作者将mini-batch中N的大小设置为2,也就是一个小批量数据采样选择两幅图像,选择均匀随机分布,然后设置mini-batch自身的大小是128,每幅图像采样64个Roi。然后作者从那些和真实边界框标记重叠
至少0.5的Roi中选择了25%,然后给这些Roi一个前景标记,也就是训练过程中的正例,此时u肯定是大于等于1的,剩下那些和真实边界框重叠率在[0.1,0.5)的,我们将它的标记设置为背景,此时u=0(因为不需要进行标定)
在训练过程中图像被反转的概率是0.5,没有其他的数据进行填充(这一段标记了正例反例,而且加入了图像反转增加网络的鲁棒性,是在训练网络对目标的辨识程度,这个地方和前面的损失函数部分好像让人不知所云??)
Back-propagation through Roi pooling layers
在Roi池化层的反向传播的计算,在解释说明反向传播的过程中,作者仅仅将N设置为1,也就是只取一个图片,但是作者说这样仅仅是方便说明,而且实际上N为几对这个解释都没影响,因为都很直觉。
在说明过程中,用Xi表示Roi池化层第i个激活输入,然后让Yrj表示第r个Roi区域的第j个输出,,然后Roi的池化层的计算公式是: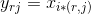 ,然后这个
,然后这个 ![]() ,
,![]() 其实就是输入划分的子窗口
其实就是输入划分的子窗口
好像这样说明读者读了肯定是一头雾水??拜托你这都写了些什么呢,我用我自己的理解给大家解释下

xi可能就是输入到Roi池化层的输入,这个没问题,没什么疑问,然后这个后面的一大串其实就是在解释最后输出的yi,一定是对应本子区域里面的最大的一个!举个例子:

就是这个池化过程的公式表示!看完大家应该可以对应起来,介绍完了公式部分,说一下如何在这个Roi池化层进行求导:

这个公式其实我也思索了良久,大家可以这么考虑,反向传播嘛,大家都知道从后往前,也就是说左边对x的偏导是越过了这个池化层的结果,那肯定要往前找对y的偏导和池化层的偏导数,而最难懂的就是这个池化层
的导数部分,按照公式的直观理解,拿上面的图举例子就是池化后的四个结果3,3,3,2和它对应的来自后面一层的导数加权求和,再对所有的Roi图像求和,就是最终我们要求得的结果!作者这里为什么要说这个Roi池化
层的求导部分,是因为作者说了这个网络结构是一个单级联的,反向求导可以贯穿整个网络,所以必须在这个地方定义出它的导数求导规则才行!
SGD hyper-parameters
随机梯度下降相关的超参数,用于softmax分类和边界回归的参数作者是用零均值,标准差是0.01到0.001的高斯分布进行初始化,偏置初始化为0,每一层的初始权值学习率为1,偏置学习率为2,然后全局的学习率设置为0.01
,而且学习率在前30k为0.01,后10k为0.001,,当遇到大的训练数据集的时候,SGD可能会迭代更多次,动量设置为0.9然后衰减参数设置为0.005
2.4尺度不变性
作者研究了两个实现尺度不变性的办法:
1 暴力法强制实现尺度不变性
2 通过使用图像金字塔实现尺度不变性
在暴力法实现中,不论是训练还是测试阶段,每一个图像被直接处理成预定义的的像素大小,网络必须从训练数据中直接学习尺度不变性的目标检测,而在多尺度方法中,它通过图像金字塔近似的为网络实现了尺度不变性,
在测试阶段,图像金字塔用来对每个proposal近似实现缩放标准化,而在多尺度训练阶段,作者随机的从缩放金字塔中采样一幅图像进行训练,这也可以算是一种数据扩充形式,作者本人只在小规模网络下实现了多尺度
金字塔放缩训练,因为GPU的显存限制。
3Fast-RCNN的网络检测
一旦Fast-RCNN网络微调完成,那么检测就会比前向计算耗时少很多了,网络接收一张图像或者图像金字塔(图像金字塔会把一系列的图片进行编码)和R个感兴趣的proposal作为输入,从而进行打分,对每一个用于测试的ROi
前向传输会输出该类别的先验概率分布和边界框的回归参数,而且作者通过估计概率给每一个类别k设置了检测置信率!
3.1 Truncated SVD for faster detection(截断奇异值分解)
可能Truncated翻译成截断有点奇怪,但是考虑下作者这个SVD分解的思想好像确实有那么点截断的意思
对于整副图像的分类,用在计算全连接层的时间和卷积层相比是很小的,但是,如果对于ROi的数量检测和处理来说,全连接层几乎又占据了整个前向传播接近一半的时间,所以,作者针对比较大的全连接层的网络设计了
一种加速的办法,那就是截断奇异值分解!
如果不是很了解奇异值分解的建议阅读奇异值分解的相关资料,这里只介绍作者加速的思想,其实一开始我也弄不懂这个加速到底是怎么做到的,作者说了,利用下述公式:![]() ,可以将计算的复杂度
,可以将计算的复杂度
从从u×v变成t(u+v),可能会有读者和我有一样的疑问,如果将u×v的矩阵分解成u×t,t×t和t×v,那最后乘起来不还是u×v吗?你这样有什么用呢,直到我后来自己动手画了一下:
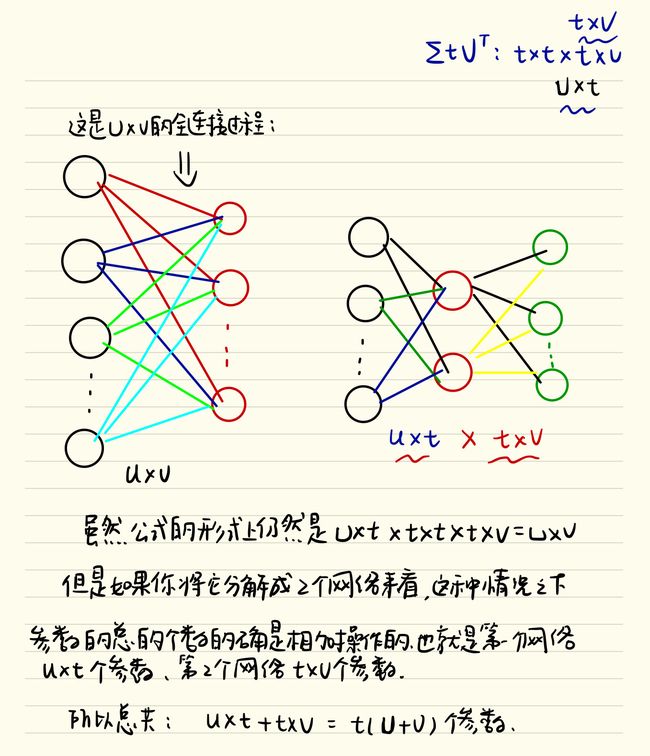
可以看到网络的参数确实是发生了变化,如果此时t的值会远远小于min(u,v)的最小值的话,那么这时候用这种奇异值分解的办法便可以特别好的简化计算过程,节省很多的前向计算的时间!
写到这里作者的主要思想基本上已经都翻译完了,Fast-RCNN的进步之处在于:
1 取消了每一个proposal都要计算一遍的繁琐过程,直接只计算一次特征图,然后利用映射关系直接在特征图里找proposal的特征向量,这样在避免重复计算的同时,节省了大量的硬盘存储
特征的时间,是一个从SPPnet得到的灵感的关于RCNN的改进,很棒!
2作者针对SPPnet的多级联多个网络模块分开训练的方法提出了改进,将这个网络组成一个单级联的网络,利用反向传播可以直接优化到整个网络,所以它在提出最大值proposal池化层的同时,
给出了网络反向传播经过池化层时候导数的计算方法!
3作者还借鉴SPPnet的空间金字塔池化模型,这样就不会限定网络的输入结构,不管特征图的大小如何,进入到空间金字塔池化层一样给你弄成固定大小的值,这种方法保证了和后续全连接层的无缝衔接!
4作者最后在全连接层继续提出优化,使用了SVD奇异值分解的办法,降低了全连接层需要学习的参数的数目,当全连接层网络结构很大的时候,可以大大降低参数数目,节省计算时间!
这就是我阅读Fast-RCNN的心得体会,如果有什么不对的地方,希望留言指出来我及时改正!下面我将继续向Faster-RCNN进发啦!谢谢~
,