Attention 理解汇总
在 Encoder-Decoder中,预测每个Decoder 的语义编码 c 是一样的,句子 X 中每个词对输出 Y 的每个词的影响都是相同的。
这样有两个弊端:
一是语义向量无法完全表示整个序列的信息;
二是先输入的内容携带的信息会被后输入的信息稀释掉,输入序列越长越严重,解码时就没有获得输入序列足够的信息,解码准确度也就不会太好。
比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在没加入Attention Model之前,生成的语义编码C是一致的,而加入之后,对应的语义编码可能如下:

f2 代表 Encoder 对输入词的某种变换函数,如 Encoder 使用RNN,f2 就是某个时刻输入 xi 后隐层节点状态值;g 代表 Encoder 根据单词的中间表示合成整个句子中间语义表示的变换函数;
一般 g 函数就是对构成元素加权求和:
例如 Ci 中 i 是“汤姆”,Tx 就是3(输入句子的长度),h1 = f(“Tom”),h2 = f(“Chase”),h3 = f(“Jerry”),对应注意力模型权值是0.6, 0.2, 0.2,g 函数就是个加权求和函数。
Attention在RNN中相当于给每个cell的时刻分配权重(特征抽取)
Attention在seq2seq中的原理计算
![]()
![]()
计算 decoder 的St-1状态与 encoder 的h1,h2...hT的关联性,使用 a(St-1, h1)...a(St-1, hT) 表示
a(St-1, h1) = exp(score(St-1, h1)) / sum(exp(score(St-1, h1)...exp(score(St-1, hT)))
score 的三种计算方式:Dot是向量内积,General是通过Wa参数矩阵计算;hs对应的是 St-1

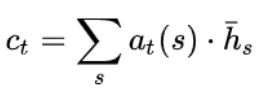

ct 和 ht 拼接后导致shape变化,使用 Wc 恢复 shape;
这里的 Attention 是基于source 端和 target 端的隐变量(hidden state)计算 Attention 值,结果是源端(source端)的每个词与目标端(target端)每个词之间的依赖关系;这是不同于self-attention的。
Attention 计算公式:
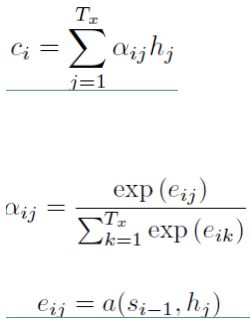 hj :Encoder 隐层第 j 时刻输出,si−1 是Decoder 第 i−1 时刻隐层的输出。
hj :Encoder 隐层第 j 时刻输出,si−1 是Decoder 第 i−1 时刻隐层的输出。
计算 ci 实际是个线性模型,而 ci 是Encoder层中各时刻隐层的输出的加权平均值。
小结:上述解决方法是对于每个Decoder输出都加权Encoder的信息,以Tom chase Jerry,Encoder-Decoder “汤姆”,“追逐”,“杰瑞”为例子,不计算起止符号,输出为3个单元,输入为3个单元。有时输入单元与输出数目会不一致,这里我们假设输入为X,m个,输出为Y,n个。对于每个yj都会综合所有x的信息共m个,同时m个X的信息权重之和为1(因为每个yj由X决定)。一共有n个y,所以有n组,n*m个权重要计算。
Self-attention 分别在source端和target端进行自身的attention 值计算,仅与 source input或者target input 自身相关的 Self -Attention,捕捉source端或target端自身的词与词之间的依赖关系;再把source端的得到的self -Attention加入到target端得到的Attention中,称作为Cross-Attention,以捕捉source端和target端词与词之间的依赖关系。
self -Attention比之前的 Attention 机制效果好,主要是传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,self-attention 不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
self-attention 中的 Q、K、V 单词以词向量输入,
先经过线性变换一般维度变小,而且参数W不共享
Q作为搜索词与句子中所有词K计算attention score,
单头的attention输出softmax(Q * KT / sqrt(dk)) * V
解析self-attention计算过程:动手推导Self-attention-译文 - 知乎
self-attention 模块输入为 n, 输出也为 n。self-attention 允许输入彼此之间进行交互并找出应更多关注的区域(“Attention”)。输出是这些交互作用和注意力得分的总和。
self-attention中的position向量计算

pos为token在序列中的位置号码,取值是 0 到序列最大长度 max_que_length - 1 间的整数。
如序列 “[cls] 我 爱 中 华 [sep]” 是 6 个token组成的序列,[cls]的pos值为0,“我”的pos值为1,“爱”的pos为2,“中”为3,“华”为4,'[sep]'为5 。bert base 最大长度 max_que_length 是512,pos取值到511,如果序列真实长度小于最大长度时,后面的位置号没有意义,最终会被mask掉。
dmodel 是位置向量的维度,与整个模型的隐藏状态维度值相同,在 bert base 模型里设置为768。
i 是从0到dmodel/2-1之间的整数值,即0,1,2,... 383
2i 是指向量维度中偶数维,即第0维,第2维,第4维,直到第766维。
2i + 1 是维度中奇数维,即第1维,第3维,第5维,直到第767维。
PE矩阵行数是最大序列长度max_que_length,列数为 dmodel,
shape = [max_que_length,dmodel]
PE(pos, 2i)是 PE 矩阵中第 pos 行,第2i列的数值,是标量,偶数列用正玄函数计算。
PE(pos,2i +1) 是PE矩阵中第 pos 行,第2i +1列的数值,是标量,奇数列用余玄函数计算。
以序列 “[cls] 我 爱 中 华 [sep]” 为例,计算序列中 "我" 的位置向量,有768维,以前面4维的值和最后2维做为例。"我" 的 pos 值是1,当 i = 0 时,2i 表示第0维,2i+1表示第1维,dmodel=768。
PE(1,0)= sin(1 / (10000)^(0/768)) = sin(1/1) = sin(1) = 0.84
PE(1,1) = cos(1 / (10000)^(0/768)) = cos(1/1)=cos(1) = 0.54
再看当i=1时的第2维和第3维
PE(1,2) = sin(1 / (10000 ^ (2 / 768))) = sin(1 / (10000 ^ (1 / 384))) = sin(1 / 1.02) = 0.83
PE(1,3) = cos(1 / (10000 ^ (2 / 768))) = cos(1 / 1.02) = 0.56
再看最后两维的情况,i = 383:
PE(1,766) = sin(1 / (10000 ^ (766/768))) = sin(1 / 9763.00) = 0.00
PE(1,767) = cos(1 / (10000 ^ (766/768))) = cos(1 / 9763.00) = 1.00
当位置号pos不断增大时,如第 0 维的变化。三角函数是关于 2 倍圆周率 Pi 的周期函数,所以把数值转为 Pi 的倍数,三角函数是周期函数,随着位置号的增加,相同维度的值周期性变化。
P(1,0)=sin(1)=sin(0.31Pi)
P(2,0)=sin(2)=sin(0.64Pi)
P(3,0)=sin(3)=sin(0.96Pi)
P(6,0)=sin(6)=sin(1.91Pi)
P(7,0)=sin(7)=sin(2.23Pi)=sin(0.23Pi)
P(8,0)=sin(8)=sin(2.54Pi)=sin(0.54Pi)
三角函数性质:sin(a+b) = sin(a) * cos(b) + cos(a) * sin(b);
cos(a+b) = cos(a) * cos(b) - sin(a) * sin(b);
两个位置向量的点积与两个位置差值(即相对位置)有关,与绝对位置无关。这个性质使得在计算注意力权重的时候(两个向量做点积),使得相对位置对注意力发生影响,而绝对位置变化不会对注意力有任何影响,这更符合常理。
如 ”我爱中华“,”华“ 与 ”中“ 相对位置为1,华与中的相关性程度取决于相对位置值1。如果这句话前面还有其他字符,华和中两个字的绝对位置会变化,此变化不影响到中华这两个字的相关程度。
缺陷:相对位置没有正负之分,比如"华"在"中"的后面,对于"中"字,"华"相对位置值应该是1,而"爱"在"中"的前面,相对位置仍然是1,无法区分到底是前面的还是后面的。
transformer的位置向量还有一种生成方式是可训练位置向量。即随机初始化一个向量,然后由模型自动训练出最可能的向量。transformer的作者指出这种可训练向量方式的效果与正玄余玄编码方式的效果差不多,bert 中采用的是可训练向量方式。
不考虑seq2seq模型,单独思考Attention;将Source中的构成元素当成是由一系列数据对构成,给定Target中的某个元素Query,计算Query和各个Key的相似性或者相关性,Key对应Value的权重系数,对Value加权求和,即Attention值。所以Attention是对Source中元素的Value值加权求和,Query和Key用来计算对应Value的权重系数;当K=V=P的时候,就是Self-Attention。
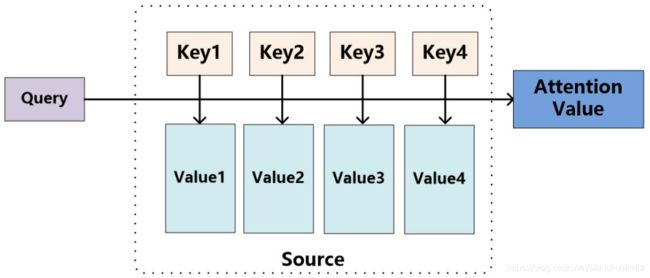
Key和Value 指向同一个东西,即输入句子中每个单词对应的语义编码 。
Attention值计算的三个阶段:
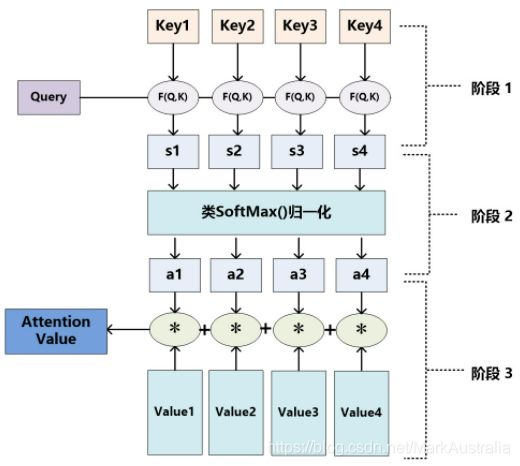
阶段1可使用不同函数计算,根据Query和某个 计算相似性或者相关性,
计算相似性或者相关性,
常用方法:求两者向量点积、求两者的向量Cosine相似性或引入额外的神经网络来求值。
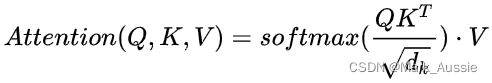
Attention 计算公式的解释:有两个句子,现需要对比两个句子;于是第一个句子用矩阵 Q 表示出来,第二个句子用矩阵 K 和矩阵 V 表示出来;计算的时候先用 Q 和 K 点积,再用 softmax 激活,得到两个句子的相似性,值的大小代表把注意力放在 V 不同位置的值;结果乘 V 得到最终提取到的特征。



Self Attention可捕获同一个句子中单词之间的一些句法特征,其核心就是使用句子中的其他词汇增强目标词汇的语义表示。
RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,距离越远,有效捕获的可能性越小。
Self Attention会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,这样远距离依赖特征之间的距离被极大缩短,可有效地利用这些特征。此外Self Attention也增加计算的并行性。
Self Attention 让Value充当Query,表示某单词自身与此句子其他单词的关联权重。可以增强句子中长距离的依赖关系(解决了RNN的长时间依赖问题)。
对Query、Key、Value的理解:
例如:Source:我 是 中国人;Target: I am Chinese
翻译的目标单词为 I 时,I 就是Query;
Source中的词都是 Key;计算每个 Key与Query的相似度,再用softmax归一化;
Value是Source中的词经过神经网络输出的vector;如使用RNN,Value就是对应的状态向量,即key与value相同;
小结:Encoder-Decoder中,Attention的 target 来自Decoder的词,source 是encoder输入句子;
self-attention 中target 和source都来自相同句子。
Keras中没有定义Attention层,需要自定义;Keras实现一个Layer 实现三个方法即可:
build(input_shape): 定义权重。必须设 self.built = True,调用 super([Layer], self).build() 完成。
call(x): 编写层的功能逻辑。只需关注传入 call 的第一个参数:输入张量,除非需要支持masking。
compute_output_shape(input_shape): 如果层更改了输入张量的形状,在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
import keras.backend as K
class AttentionWeightedAverage(Layer):
"""
Computes a weighted average of the different channels across timesteps.
Uses 1 parameter pr. channel to compute the attention value for a single timestep.
"""
def __init__(self, return_attention=False, **kwargs):
self.init = initializers.get('uniform')
self.supports_masking = True
self.return_attention = return_attention
super(AttentionWeightedAverage, self).__init__(**kwargs)
def build(self, input_shape):
self.input_spec = [InputSpec(ndim=3)]
assert len(input_shape) == 3
self.W = self.add_weight(shape=(input_shape[2], 1),
name='{}_W'.format(self.name),
initializer=self.init)
self.trainable_weights = [self.W]
super(AttentionWeightedAverage, self).build(input_shape)
def call(self, x, mask=None):
# computes a probability distribution over the timesteps
# uses 'max trick' for numerical stability
# reshape is done to avoid issue with Tensorflow
# and 1-dimensional weights
logits = K.dot(x, self.W)
x_shape = K.shape(x)
logits = K.reshape(logits, (x_shape[0], x_shape[1]))
ai = K.exp(logits - K.max(logits, axis=-1, keepdims=True))
# masked timesteps have zero weight
if mask is not None:
mask = K.cast(mask, K.floatx())
ai = ai * mask
att_weights = ai / (K.sum(ai, axis=1, keepdims=True) + K.epsilon())
weighted_input = x * K.expand_dims(att_weights)
result = K.sum(weighted_input, axis=1)
if self.return_attention:
return [result, att_weights]Multi-Head-Attention:
依旧是encoder-decoder的结构,只是使用self-attention替换了CNN和RNN;
编码器由一个多头attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。
解码器中多了一个多头attention层,为优化深度网络,整个网络使用残差连接和对层规范化处理(Add&Norm)。
当输入序列长度 n 小于 embedding 维度 d 时,每一层的时间复杂度 self-attention 是比较有优势的。当 n 比较大时,每个词不是和所有词计算attention,而只与限制的 r 个词去计算attention;并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。在长距离依赖上,由于 self-attention 是每个词和所有词都要计算 attention 值,所以不管中间有多长距离,最大的路径长度也都只是1,可以捕获长距离依赖关系。

Self-Attention 的应用:Attention 机制 一般用于RNN,主要思想是引入一个外部的权重得分值,对RNN每个时刻Cell的输出做一个重要度打分。由于RNN本质上还是一个特征抽取的过程,所以Attention机制的目标是帮助自动找出RNN的哪个时刻Cell的输出是强特,如果是RNN的输入是一个句子,则Attention机制能够找到哪个词是比较关键的词,Attention机制使模型做任务时将注意力集中在对任务有帮助的的重要的特征上面。
Attention 机制包含 一个Query,一个Key和一个Value,Key和Value 向量是对映的,如果是文本任务,Key 和 Value 表示的是同一句话(可能只是表示方式不同,通过了不同的参数进行特征变换),Query 和 Key 通过某种运算得到权重分值,获得 Value 中重要的特征做任务。
将Query和Key 经过某种数学运算的结果通过softmax激活函数激活可以得到权重得分值 at,Query 和 Key 在不同的任务中可以是不同东西。
- 在基于aspect 的情感分析中,Query 指的是 aspect,Key指的是句子;
- 在阅读理解任务中 Query指的是问题,Key指的是文档;
- 在文本分类任务中,Query 和 Key 指同一个句子,即self-attention。
将权重得分值 at 和 Value 加权求和或者加权平均,得到最终的特征表示。Value 和Key 指代的东西几乎一样,只不过表示方式不同(可能通过了不同的参数进行特征变换)。
- 在基于aspect 的情感分析中,Value指的是句子;
- 在阅读理解任务中Value指的是文档;
- 而在简单的文本分类任务中,Value依然指的是句子。
参考:
完全解析RNN, Seq2Seq, Attention注意力机制 - 知乎
Attention机制详解(一)——Seq2Seq中的Attention - 知乎
一文彻底搞懂attention机制 - 光彩照人 - 博客园
Attention机制详解(二)——Self-Attention与Transformer - 知乎 (zhihu.com)
Attention机制详解(三)——Attention模型的应用 - 知乎
基于keras的MultiAttention实现及实例 - 知乎
自然语言处理中的自注意力机制(Self-attention Mechanism) - robert_ai - 博客园
transformer 模型(self-attention自注意力)_ChihkAnchor的博客-CSDN博客_self-attention
浅谈对Attention机制的理解及Keras实现_林大大zzz的博客-CSDN博客_attention keras
[深度概念]·Attention机制实践解读_简明AI工作室-CSDN博客_attention解读
超细节!从源代码剖析Self-Attention知识点 (360doc.com)
通俗理解注意力机制中的Q、K和V表示的具体含义 - 简书 (jianshu.com)
第五课第四周笔记3:Multi-Head Attention多头注意力 - xingye_z - 博客园(多头的过程)
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)transformer模型中的多头attention机制_NeilGY的博客-CSDN博客_多头attention
5分钟理解transformer模型位置编码_u013853733的博客-CSDN博客
一种超级简单的Self-Attention ——keras 实战 - 简书
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili