kaggle竞赛 | Quora Question Pairs | 判断相似的Question
目录
- 赛题背景
- 解题过程
-
- 1. 数据分析
- 2. 构建模型
-
- 2.1 特征工程 + 树模型
- 2.2 词向量 + LSTM
代码中有详细注释解析 不懂请看代码
比赛链接:(数据集下载)
https://www.kaggle.com/competitions/quora-question-pairs/data
赛题背景
Quora是一个获取和共享有关任何知识的地方。这里是一个提出问题并与提供独特见解和高质量答案的人联系的平台。这使人们能够相互学习并更好的了解世界。
每个月有超过 1 亿人访问 Quora,因此很多人问类似的问题也就不足为奇了。具有相同意图的多个问题可能会导致搜索者花费更多时间寻找问题的最佳答案,并使作者觉得他们需要回答同一问题的多个版本。Quora 重视规范问题,因为它们为活跃的搜索者和作家提供了更好的体验,并从长远来看为这两个群体提供了更多价值。
在本次比赛中,Kagglers 面临着通过应用先进技术对问题对是否重复进行分类来解决这一自然语言处理问题的挑战。这样做可以更轻松地找到问题的高质量答案,从而改善 Quora 作者、搜索者和读者的体验。
解题过程
1. 数据分析
代码中有详细注释解析
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
INPUT_PATH = '/home/lyz/work/kaggle/kaggle-quora-question-pairs'
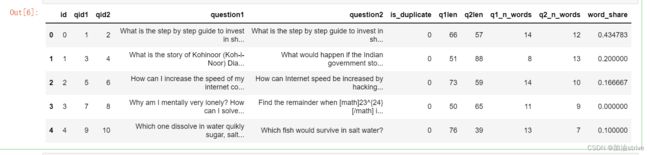
df = pd.read_csv(INPUT_PATH + "/train.csv").fillna("")
df.head()

观察有这么几个字段
id不重要
qid是问题的编码
question1和question2是具体的问题
is_duplicate问题是否类似
df.info()

除了question1和question2是字符串类型的问题
其他字段均为int型
df.shape # (404290, 6)
df.groupby("is_duplicate")['id'].count().plot.bar()

# 问题1和问题2的字符串长度
df['q1len'] = df['question1'].str.len()
df['q2len'] = df['question2'].str.len()
# 问题1和问题2的单词数量
df['q1_n_words'] = df['question1'].apply(lambda row: len(row.split(" ")))
df['q2_n_words'] = df['question2'].apply(lambda row: len(row.split(" ")))
# 根据空格分隔单词,并且将单词全部转化为小写字母并去重
# 返回值是Q1和Q2的不重复单词,占Q1 Q2总长度比值
def normalized_word_share(row):
w1 = set(map(lambda word: word.lower().strip(), row['question1'].split(" ")))
w2 = set(map(lambda word: word.lower().strip(), row['question2'].split(" ")))
return 1.0 * len(w1 & w2)/(len(w1) + len(w2))
df['word_share'] = df.apply(normalized_word_share, axis=1)
df.head()
画图查看新增特征跟目标值的相关性
plt.figure(figsize=(12, 8))
plt.subplot(1,2,1)
sns.violinplot(x = 'is_duplicate', y = 'word_share', data = df[0:50000])
plt.subplot(1,2,2)
sns.histplot(df[df['is_duplicate'] == 1.0]['word_share'][0:10000], color = 'green',kde=True)
sns.histplot(df[df['is_duplicate'] == 0.0]['word_share'][0:10000], color = 'red', kde=True)
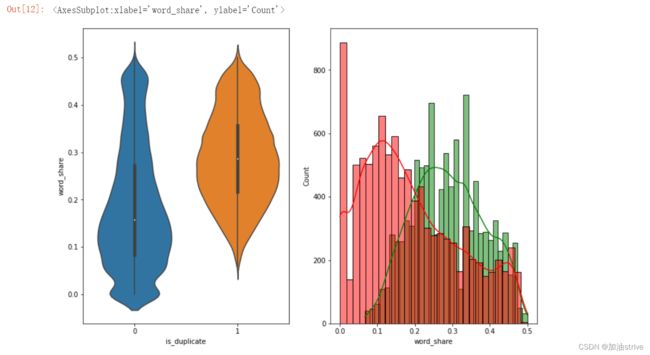
由图1可以看出,
不相似的问题word_share属性值是0–0.2
相似问题word_share属性值趋近于0.2–0.4
是一个很有效的特征值
2. 构建模型
2.1 特征工程 + 树模型
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import Counter
from nltk.corpus import stopwords
INPUT_PATH = '/home/lyz/work/kaggle/kaggle-quora-question-pairs/'
df_train = pd.read_csv(INPUT_PATH + 'train.csv', nrows=5000)
df_test = pd.read_csv(INPUT_PATH + 'test.csv', nrows=5000)
TFIDF
这里有个小问题,如果设置成: 1 / (count + eps),单词出现的频率越多,权值越低?
# 计算每个单词的权重
# 如果单词数量小于2,那么将其权重设置为0
# 如果单词数量大于2,那么将其权重设置为1 / (count + eps)
def get_weight(count, eps=10000, min_count=2):
return 0 if count < min_count else 1 / (count + eps)
# 将Q1和Q2的两个问题拼接
train_qs = pd.Series(
df_train['question1'].tolist() + df_train['question2'].tolist()
).astype(str)
# 全部转化成小写
words = (" ".join(train_qs)).lower().split()
# 计数
counts = Counter(words)
#
weights = {word: get_weight(count) for word, count in counts.items()}
载入停用词
stops = set(stopwords.words("english"))
def word_shares(row):
# 第1种情况:句子1只包含停用词
q1_list = str(row['question1']).lower().split()
q1 = set(q1_list)
q1words = q1.difference(stops)
if len(q1words) == 0:
return '0:0:0:0:0:0:0:0'
# 第2种情况:句子2只包含停用词
q2_list = str(row['question2']).lower().split()
q2 = set(q2_list)
q2words = q2.difference(stops)
if len(q2words) == 0:
return '0:0:0:0:0:0:0:0'
# 相同单词在最长问题的占比
words_hamming = sum(1 for i in zip(q1_list, q2_list) if i[0]==i[1])/max( len(q1_list), len(q2_list) )
# Q1和Q2的停用词
q1stops = q1.intersection(stops)
q2stops = q2.intersection(stops)
# 问题中的单词去重
q1_2gram = set([i for i in zip(q1_list, q1_list[1:])])
q2_2gram = set([i for i in zip(q2_list, q2_list[1:])])
# 去重后的单词序列,看两个问题之间相同单词序列的个数
shared_2gram = q1_2gram.intersection(q2_2gram)
# Q1和Q2的相同的单词
shared_words = q1words.intersection(q2words)
# 未处理前 相同单词的权重列表
shared_weights = [weights.get(w, 0) for w in shared_words]
# Q1和Q2单词的权重列表
q1_weights = [weights.get(w, 0) for w in q1words]
q2_weights = [weights.get(w, 0) for w in q2words]
# 两个问题的总权重列表
total_weights = q1_weights + q2_weights
# 相同单词的权重 / 总权重
R1 = np.sum(shared_weights) / np.sum(total_weights)
# 相同单词的长度 / (总长度-相同单词长度)
R2 = len(shared_words) / (len(q1words) + len(q2words) - len(shared_words))
# Q1停用词的占比
R31 = len(q1stops) / len(q1words)
# Q2停用词的占比
R32 = len(q2stops) / len(q2words)
# 相似度公式
Rcosine_denominator = (np.sqrt(np.dot(q1_weights,q1_weights))*np.sqrt(np.dot(q2_weights,q2_weights)))
Rcosine = np.dot(shared_weights, shared_weights)/Rcosine_denominator
# 处理后的 相同单词的权重
if len(q1_2gram) + len(q2_2gram) == 0:
R2gram = 0
else:
R2gram = len(shared_2gram) / (len(q1_2gram) + len(q2_2gram))
# 返回新的特征序列
return '{}:{}:{}:{}:{}:{}:{}:{}'.format(R1, R2, len(shared_words), R31, R32, R2gram, Rcosine, words_hamming)
# 将训练集和测试集拼接 并计算应用上一步构建新特征的函数
df = pd.concat([df_train, df_test])
df['word_shares'] = df.apply(word_shares, axis=1)
train_test = pd.DataFrame()
# 分割特征字符串为字段
train_test['word_match'] = df['word_shares'].apply(lambda x: float(x.split(':')[0]))
train_test['word_match_2root'] = np.sqrt(train_test['word_match'])
train_test['tfidf_word_match'] = df['word_shares'].apply(lambda x: float(x.split(':')[1]))
train_test['shared_count'] = df['word_shares'].apply(lambda x: float(x.split(':')[2]))
train_test['stops1_ratio'] = df['word_shares'].apply(lambda x: float(x.split(':')[3]))
train_test['stops2_ratio'] = df['word_shares'].apply(lambda x: float(x.split(':')[4]))
train_test['shared_2gram'] = df['word_shares'].apply(lambda x: float(x.split(':')[5]))
train_test['cosine'] = df['word_shares'].apply(lambda x: float(x.split(':')[6]))
train_test['words_hamming'] = df['word_shares'].apply(lambda x: float(x.split(':')[7]))
# Q1停用词占比 - Q2停用词占比
train_test['diff_stops_r'] = train_test['stops1_ratio'] - train_test['stops2_ratio']
train_test['len_q1'] = df['question1'].apply(lambda x: len(str(x)))
train_test['len_q2'] = df['question2'].apply(lambda x: len(str(x)))
# Q1长度 - Q2长度
train_test['diff_len'] = train_test['len_q1'] - train_test['len_q2']
train_test['caps_count_q1'] = df['question1'].apply(lambda x:sum(1 for i in str(x) if i.isupper()))
train_test['caps_count_q2'] = df['question2'].apply(lambda x:sum(1 for i in str(x) if i.isupper()))
# Q1和Q2大写单词数量差
train_test['diff_caps'] = train_test['caps_count_q1'] - train_test['caps_count_q2']
train_test['len_char_q1'] = df['question1'].apply(lambda x: len(str(x).replace(' ', '')))
train_test['len_char_q2'] = df['question2'].apply(lambda x: len(str(x).replace(' ', '')))
# Q1和Q2的长度差
train_test['diff_len_char'] = train_test['len_char_q1'] - train_test['len_char_q2']
train_test['len_word_q1'] = df['question1'].apply(lambda x: len(str(x).split()))
train_test['len_word_q2'] = df['question2'].apply(lambda x: len(str(x).split()))
# Q1和Q2的单词数量差
train_test['diff_len_word'] = train_test['len_word_q1'] - train_test['len_word_q2']
# 字符串数量和单词数量比
train_test['avg_world_len1'] = train_test['len_char_q1'] / train_test['len_word_q1']
train_test['avg_world_len2'] = train_test['len_char_q2'] / train_test['len_word_q2']
# Q1和Q2 字符串数量和单词数量比 之差
train_test['diff_avg_word'] = train_test['avg_world_len1'] - train_test['avg_world_len2']
# Q1和Q2 是否完全相同
train_test['exactly_same'] = (df['question1'] == df['question2']).astype(int)
# 检测两个问题的重复情况
train_test['duplicated'] = df.duplicated(subset=['question1','question2']).astype(int)
# 统计 word 单词在 df的Q1和Q2 中出现的次数
def add_word_count(x, df, word):
x['q1_' + word] = df['question1'].apply(lambda x: (word in str(x).lower())*1)
x['q2_' + word] = df['question2'].apply(lambda x: (word in str(x).lower())*1)
x[word + '_both'] = x['q1_' + word] * x['q2_' + word]
# how what which who等等
add_word_count(train_test, df, 'how')
add_word_count(train_test, df, 'what')
add_word_count(train_test, df, 'which')
add_word_count(train_test, df, ' ')
add_word_count(train_test, df, 'where')
add_word_count(train_test, df, 'when')
add_word_count(train_test, df, 'why')
XGBoost模型训练
只用5000条数据进行训练,查看效果
params = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'eta': 0.1,
'max_depth': 5,
}
cv_results = xgb.cv(
params,
xgb.DMatrix(train_test.iloc[:df_train.shape[0]], df_train['is_duplicate'].values),
num_boost_round=100,
seed=42,
nfold=5,
early_stopping_rounds=10
)
cv_results
train-logloss-mean train-logloss-std test-logloss-mean test-logloss-std
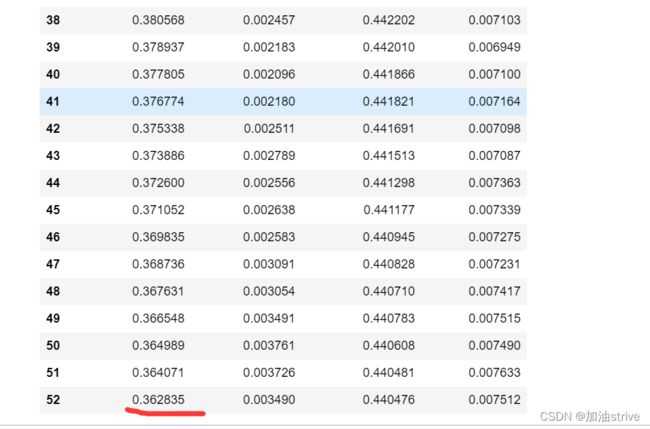
可以看到logloss是一直降低到的,可以换成全部数据集训练,查看效果
2.2 词向量 + LSTM
Import package
import os
import re
import csv
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# import codecs
from string import punctuation
from collections import defaultdict
# from tqdm import tqdm
from sklearn.preprocessing import StandardScaler
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, Input, Embedding, Dropout, Activation, LSTM, Lambda
from keras.layers.merge import concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.callbacks import EarlyStopping, ModelCheckpoint
# from keras.layers.convolutional import Conv1D
from keras.layers.pooling import GlobalAveragePooling1D
import keras.backend as K
定义常量和模型参数
Data_Dir = '../input/quora-question-pairs/' # 数据路径
Word_Vec_Dir = '../input/glove-840b-300d/' # 预训练好的glove 300维的向量模型
Embedding_File = Word_Vec_Dir + 'glove.840B.300d.txt' # 载入文件路径
Train_Data_File = Data_Dir + 'train.csv' # 训练集路径
Test_Data_File = Data_Dir + 'test.csv' # 测试集路径
Max_Sequence_Length = 60 # 最大句子长度
Max_Num_Words = 200000 # 最大单词总数量
Embedding_Dim = 300 # 嵌入层单词向量维度
Validation_Split_Ratio = 0.1 # 验证集划分比例
Num_Lstm = np.random.randint(175, 275) #
Num_Dense = np.random.randint(100, 150) #
Rate_Drop_Lstm = 0.15 + np.random.rand() * 0.25 #
Rate_Drop_Dense = 0.15 + np.random.rand() * 0.25 #
Lstm_Struc = 'lstm_{:d}_{:d}_{:.2f}_{:.2f}'.format(Num_Lstm, Num_Dense, Rate_Drop_Lstm, \
Rate_Drop_Dense)
print(Lstm_Struc)
act_f = 'relu' # 激活函数
re_weight = True
载入embedding权重
print('Create word embedding dictionary')
embeddings_index = {}
f = open(Embedding_File, encoding='utf-8')
for line in f:
values = line.split()
word = ''.join(values[:-300])
coefs = np.asarray(values[-300:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found {} word vectors of glove.'.format(len(embeddings_index)))
# Process text in dataset
print('Processing text dataset')
def text_to_wordlist(text, remove_stopwords=False, stem_words=False):
# 将字符转化为小写,并根据空格分隔
text = text.lower().split()
# 去除停用词
if remove_stopwords:
stop_words = set(stopwords.words("english"))
text = [w for w in text if not w in stop_words]
# 重新转换为字符串
text = " ".join(text)
# 清除特殊字符
text = re.sub(r"[^A-Za-z0-9^,!.\/'+-=]", " ", text)
text = re.sub(r"what's", "what is ", text)
text = re.sub(r"\'s", " ", text)
text = re.sub(r"\'ve", " have ", text)
text = re.sub(r"can't", "cannot ", text)
text = re.sub(r"n't", " not ", text)
text = re.sub(r"i'm", "i am ", text)
text = re.sub(r"\'re", " are ", text)
text = re.sub(r"\'d", " would ", text)
text = re.sub(r"\'ll", " will ", text)
text = re.sub(r",", " ", text)
text = re.sub(r"\.", " ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\/", " ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r"\+", " + ", text)
text = re.sub(r"\-", " - ", text)
text = re.sub(r"\=", " = ", text)
text = re.sub(r"'", " ", text)
text = re.sub(r":", " : ", text)
text = re.sub(r"(\d+)(k)", r"\g<1>000", text)
text = re.sub(r" e g ", " eg ", text)
text = re.sub(r" b g ", " bg ", text)
text = re.sub(r" u s ", " american ", text)
# text = re.sub(r"\0s", "0", text) # It doesn't make sense to me
text = re.sub(r" 9 11 ", "911", text)
text = re.sub(r"e - mail", "email", text)
text = re.sub(r"j k", "jk", text)
text = re.sub(r"\s{2,}", " ", text)
# 缩短单词的词干 (词干提取算法(SnowballStemmer))
if stem_words:
text = text.split()
stemmer = SnowballStemmer('english')
stemmed_words = [stemmer.stem(word) for word in text]
text = " ".join(stemmed_words)
return text
关于词干提取算法(SnowballStemmer)的实例:
https://www.zhiu.cn/57067.html
载入数据并处理
# load data and process with text_to_wordlist
train_texts_1 = []
train_texts_2 = []
train_labels = []
df_train = pd.read_csv(Train_Data_File, encoding='utf-8')
df_train = df_train.fillna('empty')
train_q1 = df_train.question1.values
train_q2 = df_train.question2.values
train_labels = df_train.is_duplicate.values
# 对训练集每个句子应用text_to_wordlist函数
for text in train_q1:
train_texts_1.append(text_to_wordlist(text, remove_stopwords=False, stem_words=False))
for text in train_q2:
train_texts_2.append(text_to_wordlist(text, remove_stopwords=False, stem_words=False))
print('{} texts are found in train.csv'.format(len(train_texts_1)))
# 对测试集每个句子应用text_to_wordlist函数
df_test = pd.read_csv(Test_Data_File, encoding='utf-8')
df_test = df_test.fillna('empty')
test_q1 = df_test.question1.values
test_q2 = df_test.question2.values
test_ids = df_test.test_id.values
for text in test_q1:
test_texts_1.append(text_to_wordlist(text, remove_stopwords=False, stem_words=False))
for text in test_q2:
test_texts_2.append(text_to_wordlist(text, remove_stopwords=False, stem_words=False))
print('{} texts are found in test.csv'.format(len(test_texts_1)))
# keras中自带的tokenizer工具
tokenizer = Tokenizer(num_words=Max_Num_Words)
# 训练全部的问题集
tokenizer.fit_on_texts(train_texts_1 + train_texts_2 + test_texts_1 + test_texts_2)
# 将问题文本转换为序列
train_sequences_1 = tokenizer.texts_to_sequences(train_texts_1)
train_sequences_2 = tokenizer.texts_to_sequences(train_texts_2)
test_sequences_1 = tokenizer.texts_to_sequences(test_texts_1)
test_sequences_2 = tokenizer.texts_to_sequences(test_texts_2)
# 看一下训练后 tokenizer中共有多少词典
word_index = tokenizer.word_index
print('{} unique tokens are found'.format(len(word_index)))
# 由于模型需要规则的input,因此需要将句子补成固定长度的序列
train_data_1 = pad_sequences(train_sequences_1, maxlen=Max_Sequence_Length)
train_data_2 = pad_sequences(train_sequences_2, maxlen=Max_Sequence_Length)
test_data_1 = pad_sequences(test_sequences_1, maxlen=Max_Sequence_Length)
test_data_2 = pad_sequences(test_sequences_2, maxlen=Max_Sequence_Length)
print('Shape of train data tensor:', train_data_1.shape)
print('Shape of train labels tensor:', train_labels.shape)
print('Shape of test data tensor:', test_data_2.shape)
print('Shape of test ids tensor:', test_ids.shape)
# 合并df_train和df_test的两个问题到一个dataframe中
questions = pd.concat([df_train[['question1', 'question2']], \
df_test[['question1', 'question2']]], axis=0).reset_index(drop='index')
questions = pd.concat([df_train[['question1', 'question2']], \
df_test[['question1', 'question2']]], axis=0).reset_index(drop='index')
# 字典格式 Key是question1,Value是question2
q_dict = defaultdict(set)
for i in range(questions.shape[0]):
q_dict[questions.question1[i]].add(questions.question2[i])
q_dict[questions.question2[i]].add(questions.question1[i])
# Q1的单词数量
def q1_freq(row):
return(len(q_dict[row['question1']]))
# Q2的单词数量
def q2_freq(row):
return(len(q_dict[row['question2']]))
# Q1和Q2问题重复单词的数量
# intersection求两个字典的交集
def q1_q2_intersect(row):
return(len(set(q_dict[row['question1']]).intersection(set(q_dict[row['question2']]))))
f_train['q1_q2_intersect'] = df_train.apply(q1_q2_intersect, axis=1, raw=True)
df_train['q1_freq'] = df_train.apply(q1_freq, axis=1, raw=True)
df_train['q2_freq'] = df_train.apply(q2_freq, axis=1, raw=True)
df_test['q1_q2_intersect'] = df_test.apply(q1_q2_intersect, axis=1, raw=True)
df_test['q1_freq'] = df_test.apply(q1_freq, axis=1, raw=True)
df_test['q2_freq'] = df_test.apply(q2_freq, axis=1, raw=True)
leaks = df_train[['q1_q2_intersect', 'q1_freq', 'q2_freq']]
test_leaks = df_test[['q1_q2_intersect', 'q1_freq', 'q2_freq']]
# 对上述的三个特征进行标准化处理
ss = StandardScaler()
ss.fit(np.vstack((leaks, test_leaks)))
leaks = ss.transform(leaks)
test_leaks = ss.transform(test_leaks)
num_words = min(Max_Num_Words, len(word_index))+1
embedding_matrix = np.zeros((num_words, Embedding_Dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
print('Null word embeddings: '.format(np.sum(np.sum(embedding_matrix, axis=1) == 0)))
# 划分训练集和验证集
perm = np.random.permutation(len(train_data_1))
idx_train = perm[:int(len(train_data_1)*(1-Validation_Split_Ratio))]
idx_val = perm[int(len(train_data_1)*(1-Validation_Split_Ratio)):]
data_1_train = np.vstack((train_data_1[idx_train], train_data_2[idx_train]))
data_2_train = np.vstack((train_data_2[idx_train], train_data_1[idx_train]))
leaks_train = np.vstack((leaks[idx_train], leaks[idx_train]))
labels_train = np.concatenate((train_labels[idx_train], train_labels[idx_train]))
data_1_val = np.vstack((train_data_1[idx_val], train_data_2[idx_val]))
data_2_val = np.vstack((train_data_2[idx_val], train_data_1[idx_val]))
leaks_val = np.vstack((leaks[idx_val], leaks[idx_val]))
labels_val = np.concatenate((train_labels[idx_val], train_labels[idx_val]))
vstack和hstack的区别:
https://blog.csdn.net/nanhuaibeian/article/details/100597342
定义模型
# 模型参数
emb_layer = Embedding(
input_dim=num_words,
output_dim=Embedding_Dim,
weights=[embedding_matrix],
input_length=Max_Sequence_Length,
trainable=False
)
# LSTM层
lstm_layer = LSTM(Num_Lstm, dropout=Rate_Drop_Lstm, recurrent_dropout=Rate_Drop_Lstm)
seq1 = Input(shape=(Max_Sequence_Length,), dtype='int32')
seq2 = Input(shape=(Max_Sequence_Length,), dtype='int32')
# Run inputs through embedding
emb1 = emb_layer(seq1)
emb2 = emb_layer(seq2)
# Run through LSTM layers
lstm_a = lstm_layer(emb1)
lstm_b = lstm_layer(emb2)
# 密集层
magic_input = Input(shape=(leaks.shape[1],))
magic_dense = Dense(int(Num_Dense/2), activation=act_f)(magic_input)
# 输入层 两个句子是LSTM,特征是Dense
merged = concatenate([lstm_a, lstm_b, magic_dense])
merged = BatchNormalization()(merged) # 批标准化
# Dropout 防止过拟合
merged = Dropout(Rate_Drop_Dense)(merged)
merged = Dense(Num_Dense, activation=act_f)(merged)
merged = BatchNormalization()(merged)
merged = Dropout(Rate_Drop_Dense)(merged)
# 二分类的激活函数用sigmoid,多分类用softmax
preds = Dense(1, activation='sigmoid')(merged)
if re_weight:
class_weight = {0: 1.309033281, 1: 0.471544715}
else:
class_weight = None
# 训练模型
model = Model(inputs=[seq1, seq2, magic_input], outputs=preds)
# 编译模型 nadam优化器 衡量指标是acc
model.compile(loss='binary_crossentropy', optimizer='nadam', metrics=['acc'])
# loss长时间不收敛 提前停止 patience设置的偏大是有用的
early_stopping =EarlyStopping(monitor='val_loss', patience=10)
bst_model_path = Lstm_Struc + '.h5'
# 设置检查点 只保存最好的模型和权重
model_checkpoint = ModelCheckpoint(bst_model_path, save_best_only=True, save_weights_only=True)
# 模型训练
hist = model.fit([data_1_train, data_2_train, leaks_train], labels_train, \
validation_data=([data_1_val, data_2_val, leaks_val], labels_val, weight_val), \
epochs=200, batch_size=2048, shuffle=True, \
class_weight=class_weight, callbacks=[early_stopping, model_checkpoint])
# 保存最优参数
model.save_weights(bst_model_path)
bst_val_score = min(hist.history['val_loss'])
# 制作提交文件
print('Making the submission')
preds = model.predict([test_data_1, test_data_2, test_leaks], batch_size=8192, verbose=1)
preds += model.predict([test_data_2, test_data_1, test_leaks], batch_size=8192, verbose=1)
preds /= 2
submission = pd.DataFrame({'test_id':test_ids, 'is_duplicate':preds.ravel()})
submission.to_csv('{:.4f}_'.format(bst_val_score)+Lstm_Struc+'_with_GloVe_Embedding.csv', index=False)
关于 BatchNormalization层
https://blog.csdn.net/weixin_44791964/article/details/114998793