Dataset and DataLoader加载数据集(上)参数解释+采用mini-batch糖尿病数据集的逻辑回归
目录
Dataset and DataLoader
数据读入和加载
Dataset 抽象类 不能实例化 只能继承
内置数据集读入方式
DataLoader 帮助我们加载数据
使用mini-batch的训练方法
采用mini-batch糖尿病数据集的逻辑回归
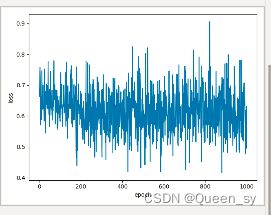
训练出来是不收敛的,不知道怎么回事,训练出来的宝子可以评论一下 告诉我什么情况。
Dataset and DataLoader
数据读入和加载
第一种方式:下载并使用PyTorch提供的内置数据集。只适用于常见的数据集,如MNIST,CIFAR10等,PyTorch官方提供了数据下载。这种方式往往适用于快速测试方法(比如测试下某个idea在MNIST数据集上是否有效)
第二种方式:从网站下载以csv格式存储的数据,读入并转成预期的格式。需要自己构建Dataset,这对于PyTorch应用于自己的工作中十分重要。
同时,还需要对数据进行必要的变换,比如说需要将图片统一为一致的大小,以便后续能够输入网络训练;需要将数据格式转为Tensor类,等等。
Dataset 抽象类 不能实例化 只能继承
内置数据集读入方式
模板 from torchvision import transforms image_size = 28 data_transform = transforms.Compose([ transforms.Resize(image_size), transforms.ToTensor() ]) from torchvision import datasets train_data = datasets.FashionMNIST(root='./',# 存放位置 train=True, # 载入训练集 download=True,# 下载 transform=data_transform 设置数据变换 ) test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)
DataLoader 帮助我们加载数据
模板:
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=0)
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,参数含义:
| dataset(Dataset) | 传入的数据集 |
| batch_size(int, optional) | 每个batch有多少个样本 |
| shuffle(bool, optional) | 在每个epoch开始的时候,对数据进行重新排序 |
| num_workers | 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0) |
| drop_last | 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了… 如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。 |
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中
timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each
worker subprocess with the worker id (an int in [0, num_workers – 1]) as input, after seeding and before data loading. (default: None)
使用mini-batch的训练方法
for epoch in range(1000):
for i,data in enumerate(train_loader,0):
# inputs labels都是张量
inputs,labels=data采用mini-batch糖尿病数据集的逻辑回归
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32,skiprows = 1)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2= torch.nn.Linear(6,4)
self.linear3= torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model=Model()
dataset=DiabetesDataset('pima-indians-diabetes.csv')
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
criterion=torch.nn.BCELoss(size_average=True)
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
px,py = [],[] # 记录要绘制的数据
for epoch in range(1000):
for i,data in enumerate(train_loader,0):
# inputs labels都是张量
inputs,labels=data
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
px.append(epoch)
py.append(loss.item())
plt.plot(px, py)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()