自监督学习新思路!基于蒸馏(distillation loss)的自监督学习算法

今天给大家介绍一篇 CVPR 2021 关于自监督的文章叫 S2-BNN [1],来自 CMU,HKUST 和 IIAI。它探讨了如果网络规模在非常小的情况下(比如 efficient networks 或者 binary neural networks),什么样的自监督训练策略和方法是最好的。
本文发现基于小网络的前提下,基于蒸馏(distillation learning)的自监督学习得到的模型性能远远强于对比学习(contrastive learning),同时他们还发现同时使用蒸馏和对比学习效果反而不如单独使用蒸馏损失,这也是一个非常有意思的发现。

论文标题:
S2-BNN: Bridging the Gap Between Self-Supervised Real and 1-bit Neural Networks via Guided Distribution Calibration
论文链接:
https://arxiv.org/abs/2102.08946
代码和模型:
https://github.com/szq0214/S2-BNN
本文的初衷是:如果网络模型的规模比较小,那么它的表达能力也会非常有限,从而会造成这类网络的预测概率变得不那么确信(confident),这时候作者就产生一个疑问:最常使用的对比学习在这种类型的网络上面还能取得较好的结果吗?
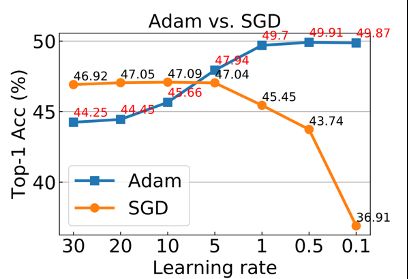
基于这个疑问:作者首先使用默认参数的 MoCo V2 作为自监督学习基准算法(baseline),在使用 ReActNet 作为主干网的时候在 ImageNet 上得到 46.9%。由于该主干网是一个二值化网络,因此作者提出需要调整优化器、学习率策略、数据增强策略来匹配二值网络的特性。作者尝试使用 Adam 和 SGD 两种优化器来训练主干网,在线性评估(linear evaluation)阶段使用不同学习率来寻找最佳的参数设计。
作者发现使用使用 SGD 训练的网络,在线性评估阶段学习率比较大的时候性能比较高,学习率降低时精度严重下降,而 Adam 训练的网络刚好相反,学习率降低时精度反而上升,同时 Adam 训练的网络在取得最佳精度的设置时结果明显优于 SGD 的最佳结果。因此作者首先提出了一个基于 MoCo V2 的更强的 baseline+,性能为 52.5%。
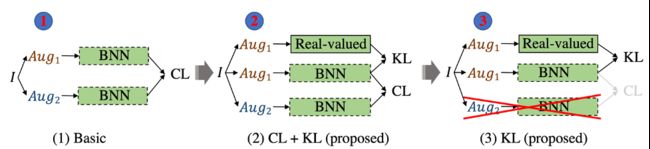
接下来作者提出并比较了如下三种策略:
1. 单纯使用对比学习(使用增强后的 MoCo V2 作为对比学习算法);
2. 对比学习损失加上知识蒸馏损失(文章使用 cross-entropy loss 作为蒸馏损失)训练模型;
3. 只使用知识蒸馏损失(cross-entropy loss)训练模型。
蒸馏损失函数表达:
作者这边使用的是 soft 版本的 cross-entropy loss 作为蒸馏损失函数,具体实现细节可以去看他们的代码,损失函数表达形式如下:

如何获取 teacher 呢?
这里作者讨论了两种方案来得到 teacher 网络,一种是在线(online)的方式同时训练 teacher 和 student,如下图所示。另一种是离线(offline)的方式,即先使用自监督方法训好 teacher,然后固定 teacher 的权重来蒸馏目标网络,这也是本文中采用的策略。
为什么使用 offline 的策略呢?其主要好处是效率高,由于 teacher 只需要训练一次,后面可以重复使用,从而使 student 的训练更加高效。其次就是 teacher 在蒸馏过程中权重都是 freeze 的,产生的监督信号也跟精确更稳定,对于 student 的收敛也会有帮助。
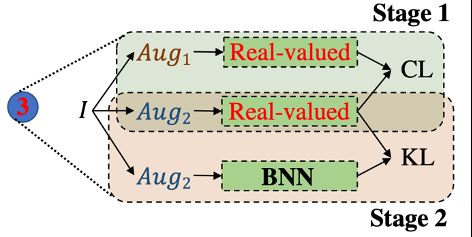
下面是两种策略的算法示意图:

核心实验结果:
作者在 ImageNets-1k 上进行了实验,核心结果如下:

表中 ① ② ③ 分别对应了三种训练策略,本文增强之后的结果比原始的 baseline 高了 5.6%,加上蒸馏损失(distillation loss)之后结果提升到 5.6%,去掉对比损失(contrastive loss)精度进一步提升了 5.5%,达到 61.5%。可以看到只使用知识蒸馏的策略相比其他两个方案,对于性能的提升还是非常可观的。
为什么同时使用蒸馏损失和对比损失效果反而没有单独使用蒸馏损失效果好?
直观地说,蒸馏损失会迫使 student 去模仿 teacher 网络的预测概率输出,而对比学习倾向于从数据本身中发现潜在模式(patterns)。如下图所示,在二值化网络场景中,对比损失学习细粒度表示的能力相比蒸馏损失相对较弱,学到的表达在语义层面也更模糊。因此,由于优化空间的差异而导致两者结合使用可能并不是最佳的解决方案。

同时期一些基于蒸馏的自监督学习方法:
最近基于知识蒸馏的自监督方法有不少,包括跟本文同时期的 SEED [2](发表于 ICLR 2021, 两者投稿相隔一个月,可以认为是同时期的工作)以及后续比较有名的 FAIR 的 DINO [3] 等等, SEED 基本上跟这篇文章的方法是类似的,只是在 student 的选取上一个选择的是小规模网络,本文选择的是 efficient 的二值化网络,但是本身训练方法上没有大的差别。DINO 跟他们两者的主要区别在于 DINO 的 teacher 的权重在训练过程是不固定的。
更多分析和消融实验请阅读论文原文。
参考文献
[1] Zhiqiang Shen, Zechun Liu, Jie Qin, Lei Huang, Kwang-Ting Cheng, and Marios Savvides. "S2-bnn: Bridging the gap between self-supervised real and 1-bit neural networks via guided distribution calibration." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2165-2174. 2021.
[2] Zhiyuan Fang, Jianfeng Wang, Lijuan Wang, Lei Zhang, Yezhou Yang, and Zicheng Liu. "Seed: Self-supervised distillation for visual representation." arXiv preprint arXiv:2101.04731 (2021).
[3] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. "Emerging properties in self-supervised vision transformers." arXiv preprint arXiv:2104.14294 (2021).
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
