Reweight:社区推荐多目标优化的1.0及其代码实现(tensorflow2.2)
点击上方“数据与智能”,“星标或置顶公众号”
第一时间获取好内容


作者 | xulu1352 目前在一家互联网公司从事推荐算法工作(知乎:xulu1352)
编辑 | lily


0

前序
说到社区feed信息流推荐,必定要思考如何从多元信息中筛选出优质且具有个性化的内容推送给用户,相信大多数人会将点击率作为feed流推荐优劣的评估指标,但是为了兼顾社区的氛围与发展,优化目标也就从用户的点击率延伸到阅读时长、回复、点赞、收藏、分享、关注等多个目标优化;当然,平台的终极目标是希望用户拥有沉浸式体验,锁定用户更多的碎片时间。好了,吹水的内容就到这了,接下来说说本文的主题reweight。关于reweight网上已有几篇本人觉得不错的文章,比如蘑菇街大佬的蘑菇街首页推荐多目标优化之reweight实践:一把双刃剑?这篇文章对reweight原理及样本权重的设计都做了不错的阐述,但是实践中总会遇到有些原理看起来很简单的东西,实现起来却很痛苦,对于算法理解也绝不能停留理念层面,绝知此事要躬行,这也是我写这篇文章的原因,你可以把这篇文章认为是上述文章reweight方案的一种实现,想要了解更多的原理可以参考蘑菇街大佬的那篇文章。
1
目前业界多目标优化的几种方案(只列出本人实践过的三个)
轻量级的reweight
这种方案,实现简单,算是一种小而美的解决方案;其主要思想在优化主目标(一般ctr)的同时,将其他的目标通过炼丹的方式转化为Sample Weight,这个Sample Weight计算逻辑设计就需要结合自身业务来定了,我们这里主要使用阅读时长及点赞来计算它,Sample Weight设计的好不好,说实话得靠炼丹;有了Sample Weight就可以将它加入到排序模型的损失函数中去,损失函数又是一种学习准则,影响了它,模型优化主目标损失的同时可以兼顾到其他目标的优化;其实本质上还是让模型优化一个目标,并不是多目标建模,只是优化一个转化后的新目标。
我们称为这种损失为加权交叉熵损失,当label 时,即negative样本,其样本权重会置为1,如果感兴趣,推导下反向传播梯度求导公式可以看出训练时 的样本,即positive样本会在原始梯度的基础上乘以reweight 值。
中量级的Share-bottom Parameter Multi-task DNN
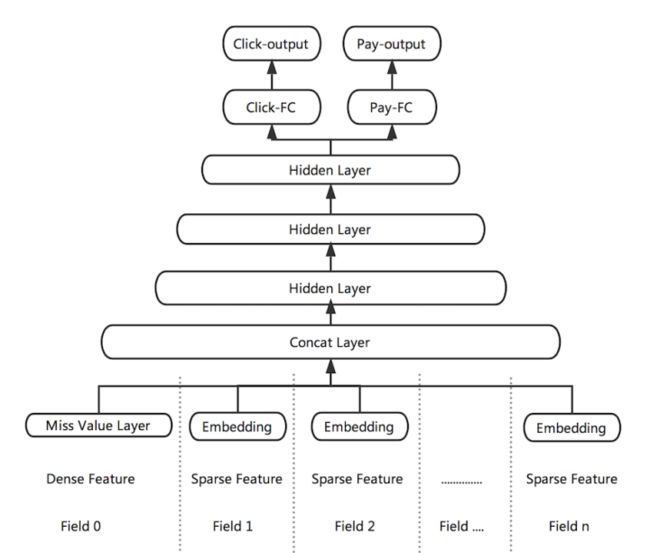
这种Multi-task DNN 在使用时值得注意的是当多个任务相关性较弱时,或者各任务有冲突时,这种Hard parameter sharing的方法,底层的shared layer 很难学到两者共同的模式,多目标任务也很难学好。
重量级的MMoE
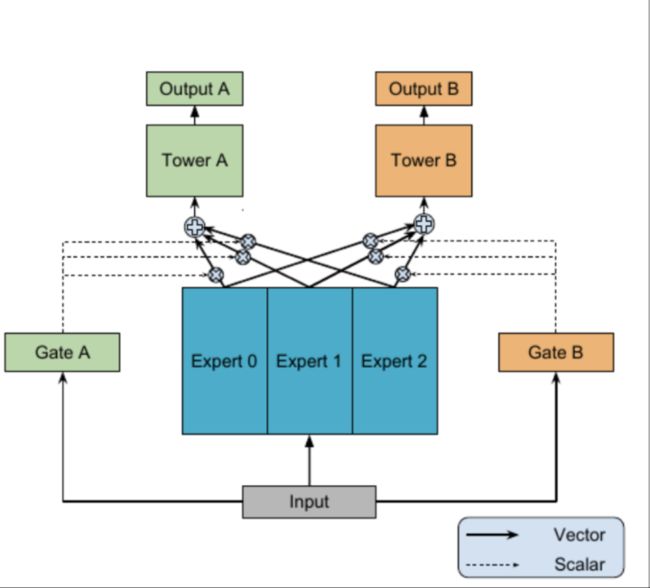
MMoE的全称叫做Multi-gate Mixture-of-Experts,在这篇论文发表前,还有个MoE模型(Mixture-of-Experts,给定 个任务,模型由一个shared-bottom network 和 个 tower networks 组成,其中 ),MMoE是建立在MoE的基础上,其主要思想是用MoE layer来替代share bottom network ,对于每个任务 ,都加入一个单独的gating network , 具体地,任务 的输出是:
gating networks就是一个简单加上softmax layer的线性变换:
其中, , 为experts的个数, 为特征维度。
2
手把手教你实现reweight
在看代码实现之前,还有个重要常识需要了解,不然你的reweight,很可能是一次失败的炼丹。从上面提到的 公式中可以看出:
当reweight > 1时,对positive样本预测错误将带来更大的损失,因此false negative数量将会减少,将会上升;相反的,当reweight < 1时,对负样本预测错误将带来更大的损失,导致false positive数量减少,从而将会增加。
这个在tensorflow官方文档中关于tf.nn.weighted_cross_entropy_with_logits函数用法说明也有相似的描述,感兴趣的同学可以查看一下。下面就来看看训练流程中与base model 两点不同的地方,完整代码实现可以参见本文附录。
输入数据的改变
这里以构造tf.data.Dataset输入为例,既然是reweight,自然每个样本我们就必须指定其sample_weight值,训练时将sample_weight参数传递给Model.fit() 。对于 dataset类型的输入数据来说,需要在构建dataset时将sample_weight 加入其中,返回一个三元组的 dataset ,格式为 (input_batch, target_batch, sample_weight_batch)。
# 数据处理逻辑
def _parse_function(example_proto):
"""
your data processing logic code
"""
return feature_dict, label, sample_weight
filenames= tf.data.Dataset.list_files([
'/data/train_data.csv',
])
dataset = filenames.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
batch_size = 1024
dataset = dataset.map(_parse_function, num_parallel_calls=20)
dataset = dataset.repeat()
dataset = dataset.shuffle(buffer_size = batch_size) # 在缓冲区中随机打乱数据
dataset = dataset.batch(batch_size = batch_size) # 每1024条数据为一个batch,生成一个新的Datasets
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)自定义Model损失
在训练阶段计算batch loss 时,如果我们希望这个loss 是加权平均loss,或者希望训练过程看着更清晰些,我们就需要自定义 Model 的train_step(这个权限在tf.keras2.2才开放)操作,TF2 默认的加权loss计算方式是 ,这里我们使用加权平均loss,即 ,下面来看看具体code。
class ReweightModel(tf.keras.Model):
def train_step(self, data):
# Unpack the data. Its structure depends on your model and
# on what you pass to `fit()`.
if len(data) == 3:
y_prop, y_true, sample_weight = data
else:
raise "This is a reweight model, your inputs should contain features, label, sample_weight"
with tf.GradientTape() as tape:
y_pred = self(y_prop, training=True) # Forward pass
y_true_1d = tf.cast(tf.reshape(y_true, [-1, 1]),tf.float32) # (batch,1)
sample_weight_1d = tf.reshape(sample_weight, [-1, 1]) # (batch,1)
# Compute the binary_crossentropy loss value.
bce = tf.losses.binary_crossentropy(y_true_1d, y_pred, from_logits=False)[:, None]
# multiply sample_weight
bce_weight = (bce * (1 - y_true_1d) + bce * (y_true_1d)) * sample_weight_1d
# sum bce loss with weight
loss_sum = tf.reduce_sum(bce_weight, name="weight_loss_sum")
# sum sample_weight
sw_sum = tf.reduce_sum(sample_weight, name="sample_weight_sum")
# mean batch bce loss with weight
loss = tf.divide(loss_sum, sw_sum, name="weight_logloss")
# you can try the following way, which is the default way of TF
# loss = tf.reduce_mean(bce_weight, name="weight_logloss")
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update the metrics.
# Metrics are configured in `compile()`.
self.compiled_metrics.update_state(y_true, y_pred)
# Return a dict mapping metric names to current value.
loss_tracker = {'logloss':loss}
metrics_tracker = {m.name: m.result() for m in self.metrics}
return {**loss_tracker, **metrics_tracker}好了,对比baseline,整个reweight需要做的改动已经说完了,是不是很简单,如果sample_weight设计的合适,相信会有一波收益的。
3
附上一套完整reweight训练code
我们线上的baseline是wide&deep,这里使用基于wide&deep的reweight实现作为演示。
为了更好的演示,假设我们的原始数格式是下面这样的,
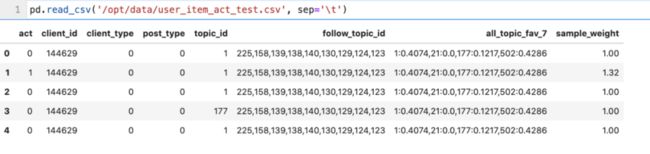
字段介绍:
act:为label数据 1:正样本,0:负样本
client_id: 用户id
post_type:物料item形式 图文 ,视频
client_type:用户客户端类型
follow_topic_id:用户关注话题分类id
all_topic_fav_7:用户画像特征,用户最近7天对话题偏爱度刻画,kv键值对形式
topic_id:物料所属的话题
sample_weight:样本reweight权重
import numpy as np
import pandas as pd
import datetime
import tensorflow as tf
from tensorflow.keras.layers import *
import tensorflow.keras.backend as K
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import TensorBoard
from collections import namedtuple, OrderedDict
########################################################################
#################数据预处理##############
########################################################################
# 定义参数类型
SparseFeat = namedtuple('SparseFeat', ['name', 'voc_size', 'share_embed','embed_dim', 'dtype'])
DenseFeat = namedtuple('DenseFeat', ['name', 'pre_embed','reduce_type','dim', 'dtype'])
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'voc_size', 'share_embed', 'weight_name', 'embed_dim','maxlen', 'dtype'])
# 筛选实体标签categorical
DICT_CATEGORICAL = {"topic_id": [str(i) for i in range(0, 700)],
"client_type": [0,1],
"post_type": [0,1],
}
feature_columns = [SparseFeat(name="topic_id", voc_size=700, share_embed=None, embed_dim=16, dtype='string'),
SparseFeat(name='client_type', voc_size=2, share_embed=None, embed_dim=1,dtype='float32'),
SparseFeat(name='post_type', voc_size=2, share_embed=None, embed_dim=1,dtype='float32'),
VarLenSparseFeat(name="follow_topic_id", voc_size=700, share_embed='topic_id',weight_name = None, embed_dim=16, maxlen=20,dtype='string'),
VarLenSparseFeat(name="all_topic_fav_7", voc_size=700, share_embed='topic_id', weight_name = 'all_topic_fav_7_weight', embed_dim=16, maxlen=5,dtype='string'),
]
# 用户特征及贴子特征
linear_feature_columns_name = ['client_type', 'post_type']
dnn_feature_columns_name = ["topic_id", 'follow_topic_id', "all_topic_fav_7"]
linear_feature_columns = [col for col in feature_columns if col.name in linear_feature_columns_name ]
dnn_feature_columns = [col for col in feature_columns if col.name in dnn_feature_columns_name ]
DEFAULT_VALUES = [[0],[''],[0.0],[0.0], [''],
[''], [''],[0.0]]
COL_NAME = ['act','client_id','client_type', 'post_type',"topic_id", 'follow_topic_id', "all_topic_fav_7",'sample_weight']
def _parse_function(example_proto):
item_feats = tf.io.decode_csv(example_proto, record_defaults=DEFAULT_VALUES, field_delim='\t')
parsed = dict(zip(COL_NAME, item_feats))
feature_dict = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
if feat_col.weight_name is not None:
kvpairs = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
kvpairs = tf.strings.split(kvpairs, ':')
kvpairs = kvpairs.to_tensor()
feat_ids, feat_vals = tf.split(kvpairs, num_or_size_splits=2, axis=1)
feat_ids = tf.reshape(feat_ids, shape=[-1])
feat_vals = tf.reshape(feat_vals, shape=[-1])
feat_vals= tf.strings.to_number(feat_vals, out_type=tf.float32)
feature_dict[feat_col.name] = feat_ids
feature_dict[feat_col.weight_name] = feat_vals
else:
feat_ids = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
feat_ids = tf.reshape(feat_ids, shape=[-1])
feature_dict[feat_col.name] = feat_ids
elif isinstance(feat_col, SparseFeat):
feature_dict[feat_col.name] = parsed[feat_col.name]
elif isinstance(feat_col, DenseFeat):
if not feat_col.is_embed:
feature_dict[feat_col.name] = parsed[feat_col.name]
elif feat_col.reduce_type is not None:
keys = tf.strings.split(parsed[feat_col.is_embed], ',')
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(keys))
emb = tf.reduce_mean(emb,axis=0) if feat_col.reduce_type == 'mean' else tf.reduce_sum(emb,axis=0)
feature_dict[feat_col.name] = emb
else:
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(parsed[feat_col.is_embed]))
feature_dict[feat_col.name] = emb
else:
raise "unknown feature_columns...."
label = parsed['act']
sp = parsed['sample_weight']
return feature_dict, label, sp
pad_shapes = {}
pad_values = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
max_tokens = feat_col.maxlen
pad_shapes[feat_col.name] = tf.TensorShape([max_tokens])
pad_values[feat_col.name] = ''
if feat_col.weight_name is not None:
pad_shapes[feat_col.weight_name] = tf.TensorShape([max_tokens])
pad_values[feat_col.weight_name] = tf.constant(-1, dtype=tf.float32)
# no need to pad labels
elif isinstance(feat_col, SparseFeat):
if feat_col.dtype == 'string':
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = '9999'
else:
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = 0.0
elif isinstance(feat_col, DenseFeat):
if not feat_col.is_embed:
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = 0.0
else:
pad_shapes[feat_col.name] = tf.TensorShape([feat_col.dim])
pad_values[feat_col.name] = 0.0
pad_shapes = (pad_shapes, (tf.TensorShape([])), (tf.TensorShape([])))
pad_values = (pad_values, (tf.constant(0, dtype=tf.int32)), (tf.constant(0.0)))
filenames= tf.data.Dataset.list_files([
'/opt/data/user_item_act_test.csv',
])
dataset = filenames.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
batch_size = 2
dataset = dataset.map(_parse_function, num_parallel_calls=60)
dataset = dataset.repeat()
dataset = dataset.shuffle(buffer_size = batch_size) # 在缓冲区中随机打乱数据
dataset = dataset.padded_batch(batch_size = batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 验证集
filenames_val= tf.data.Dataset.list_files(['/opt/data/user_item_act_test_val.csv'])
dataset_val = filenames_val.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
val_batch_size = 2
dataset_val = dataset_val.map(_parse_function, num_parallel_calls=60)
dataset_val = dataset_val.padded_batch(batch_size = val_batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset_val = dataset_val.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
########################################################################
#################自定义Layer##############
########################################################################
# 离散多值查找表 转稀疏SparseTensor >> EncodeMultiEmbedding >>tf.nn.embedding_lookup_sparse的sp_ids参数中
class SparseVocabLayer(Layer):
def __init__(self, keys, **kwargs):
super(SparseVocabLayer, self).__init__(**kwargs)
vals = tf.range(1, len(keys) + 1)
vals = tf.constant(vals, dtype=tf.int32)
keys = tf.constant(keys)
self.table = tf.lookup.StaticHashTable(
tf.lookup.KeyValueTensorInitializer(keys, vals), 0)
def call(self, inputs):
input_idx = tf.where(tf.not_equal(inputs, ''))
input_sparse = tf.SparseTensor(input_idx, tf.gather_nd(inputs, input_idx), tf.shape(inputs, out_type=tf.int64))
return tf.SparseTensor(indices=input_sparse.indices,
values=self.table.lookup(input_sparse.values),
dense_shape=input_sparse.dense_shape)
def get_config(self):
config = super(SparseVocabLayer, self).get_config()
return config
# 自定义Embedding层,初始化时,需要传入预先定义好的embedding矩阵,好处可以共享embedding矩阵
class EncodeMultiEmbedding(Layer):
def __init__(self, embedding, has_weight=False, **kwargs):
super(EncodeMultiEmbedding, self).__init__(**kwargs)
self.has_weight = has_weight
self.embedding = embedding
def build(self, input_shape):
super(EncodeMultiEmbedding, self).build(input_shape)
def call(self, inputs):
if self.has_weight:
idx, val = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=val, combiner='sum')
else:
idx = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=None, combiner='mean')
return tf.expand_dims(combiner_embed, 1)
def get_config(self):
config = super(EncodeMultiEmbedding, self).get_config()
config.update({'has_weight': self.has_weight})
return config
# 稠密权重转稀疏格式输入到tf.nn.embedding_lookup_sparse的sp_weights参数中
class Dense2SparseTensor(Layer):
def __init__(self):
super(Dense2SparseTensor, self).__init__()
def call(self, dense_tensor):
weight_idx = tf.where(tf.not_equal(dense_tensor, tf.constant(-1, dtype=tf.float32)))
weight_sparse = tf.SparseTensor(weight_idx, tf.gather_nd(dense_tensor, weight_idx), tf.shape(dense_tensor, out_type=tf.int64))
return weight_sparse
def get_config(self):
config = super(Dense2SparseTensor, self).get_config()
return config
# 自定义dnese层 含BN, dropout
class CustomDense(Layer):
def __init__(self, units=32, activation='tanh', dropout_rate =0, use_bn=False, seed=1024, tag_name="dnn", **kwargs):
self.units = units
self.activation = activation
self.dropout_rate = dropout_rate
self.use_bn = use_bn
self.seed = seed
self.tag_name = tag_name
super(CustomDense, self).__init__(**kwargs)
#build方法一般定义Layer需要被训练的参数。
def build(self, input_shape):
self.weight = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True,
name='kernel_' + self.tag_name)
self.bias = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True,
name='bias_' + self.tag_name)
if self.use_bn:
self.bn_layers = tf.keras.layers.BatchNormalization()
self.dropout_layers = tf.keras.layers.Dropout(self.dropout_rate)
self.activation_layers = tf.keras.layers.Activation(self.activation, name= self.activation + '_' + self.tag_name)
super(CustomDense,self).build(input_shape) # 相当于设置self.built = True
#call方法一般定义正向传播运算逻辑,__call__方法调用了它。
def call(self, inputs,training=None, **kwargs):
fc = tf.matmul(inputs, self.weight) + self.bias
if self.use_bn:
fc = self.bn_layers(fc)
out_fc = self.activation_layers(fc)
return out_fc
#如果要让自定义的Layer通过Functional API 组合成模型时可以序列化,需要自定义get_config方法,保存模型不写这部分会报错
def get_config(self):
config = super(CustomDense, self).get_config()
config.update({'units': self.units, 'activation': self.activation, 'use_bn': self.use_bn,
'dropout_rate': self.dropout_rate, 'seed': self.seed, 'name': self.tag_name})
return config
class Add(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super(Add, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
super(Add, self).build(input_shape)
def call(self, inputs, **kwargs):
if not isinstance(inputs,list):
return inputs
if len(inputs) == 1 :
return inputs[0]
if len(inputs) == 0:
return tf.constant([[0.0]])
return tf.keras.layers.add(inputs)
class ReweightModel(tf.keras.Model):
def train_step(self, data):
# Unpack the data. Its structure depends on your model and
# on what you pass to `fit()`.
if len(data) == 3:
y_prop, y_true, sample_weight = data
else:
raise "This is a reweight model, your inputs should contain features, label, sample_weight"
with tf.GradientTape() as tape:
y_pred = self(y_prop, training=True) # Forward pass
y_true_1d = tf.cast(tf.reshape(y_true, [-1, 1]),tf.float32) # (batch,1)
sample_weight_1d = tf.reshape(sample_weight, [-1, 1]) # (batch,1)
# Compute the binary_crossentropy loss value.
bce = tf.losses.binary_crossentropy(y_true_1d, y_pred, from_logits=False)[:, None]
# multiply sample_weight
bce_weight = (bce * (1 - y_true_1d) + bce * (y_true_1d)) * sample_weight_1d
# sum bce loss with weight
loss_sum = tf.reduce_sum(bce_weight, name="weight_loss_sum")
# sum sample_weight
sw_sum = tf.reduce_sum(sample_weight, name="sample_weight_sum")
# mean batch bce loss with weight
loss = tf.divide(loss_sum, sw_sum, name="weight_logloss")
# you can try the following way, which is the default way of TF
# loss = tf.reduce_mean(bce_weight, name="weight_logloss")
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update the metrics.
# Metrics are configured in `compile()`.
self.compiled_metrics.update_state(y_true, y_pred)
# Return a dict mapping metric names to current value.
loss_tracker = {'logloss':loss}
metrics_tracker = {m.name: m.result() for m in self.metrics}
return {**loss_tracker, **metrics_tracker}
########################################################################
#################定义输入帮助函数##############
########################################################################
# 定义model输入特征
def build_input_features(features_columns, prefix=''):
input_features = OrderedDict()
for feat_col in features_columns:
if isinstance(feat_col, DenseFeat):
if feat_col.pre_embed is None:
input_features[feat_col.name] = Input([1], name=feat_col.name)
else:
input_features[feat_col.name] = Input([feat_col.dim], name=feat_col.name)
elif isinstance(feat_col, SparseFeat):
input_features[feat_col.name] = Input([1], name=feat_col.name, dtype=feat_col.dtype)
elif isinstance(feat_col, VarLenSparseFeat):
input_features[feat_col.name] = Input([None], name=feat_col.name, dtype='string')
if feat_col.weight_name is not None:
input_features[feat_col.weight_name] = Input([None], name=feat_col.weight_name, dtype='float32')
else:
raise TypeError("Invalid feature column in build_input_features: {}".format(feat_col.name))
return input_features
# 构造 自定义 embedding层matrix
def build_embedding_matrix(features_columns):
embedding_matrix = {}
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat) or isinstance(feat_col, VarLenSparseFeat):
if feat_col.dtype == 'string':
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
vocab_size = feat_col.voc_size
embed_dim = feat_col.embed_dim
if vocab_name not in embedding_matrix:
embedding_matrix[vocab_name] = tf.Variable(initial_value=tf.random.truncated_normal(shape=(vocab_size, embed_dim),mean=0.0,
stddev=0.0, dtype=tf.float32), trainable=True, name=vocab_name+'_embed')
return embedding_matrix
# 构造 自定义 embedding层
def build_embedding_dict(features_columns, embedding_matrix):
embedding_dict = {}
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
if feat_col.dtype == 'string':
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
embedding_dict[feat_col.name] = EncodeMultiEmbedding(embedding=embedding_matrix[vocab_name],name='EncodeMultiEmb_' + feat_col.name)
elif isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
if feat_col.weight_name is not None:
embedding_dict[feat_col.name] = EncodeMultiEmbedding(embedding=embedding_matrix[vocab_name],has_weight=True,name='EncodeMultiEmb_' + feat_col.name)
else:
embedding_dict[feat_col.name] = EncodeMultiEmbedding(embedding=embedding_matrix[vocab_name],name='EncodeMultiEmb_' + feat_col.name)
return embedding_dict
# dense 与 embedding特征输入
def input_from_feature_columns(features, features_columns, embedding_dict):
sparse_embedding_list = []
dense_value_list = []
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat) or isinstance(feat_col, VarLenSparseFeat):
if feat_col.dtype == 'string':
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
keys = DICT_CATEGORICAL[vocab_name]
_input_sparse = SparseVocabLayer(keys)(features[feat_col.name])
if isinstance(feat_col, SparseFeat):
if feat_col.dtype == 'string':
_embed = embedding_dict[feat_col.name](_input_sparse)
else:
_embed = Embedding(feat_col.voc_size+1, feat_col.embed_dim,
embeddings_regularizer=tf.keras.regularizers.l2(0.5),name='Embed_' + feat_col.name)(features[feat_col.name])
sparse_embedding_list.append(_embed)
elif isinstance(feat_col, VarLenSparseFeat):
if feat_col.weight_name is not None:
_weight_sparse = Dense2SparseTensor()(features[feat_col.weight_name])
_embed = embedding_dict[feat_col.name]([_input_sparse, _weight_sparse])
else:
_embed = embedding_dict[feat_col.name](_input_sparse)
sparse_embedding_list.append(_embed)
elif isinstance(feat_col, DenseFeat):
dense_value_list.append(features[feat_col.name])
else:
raise TypeError("Invalid feature column in input_from_feature_columns: {}".format(feat_col.name))
return sparse_embedding_list, dense_value_list
def concat_func(inputs, axis=-1):
if len(inputs) == 1:
return inputs[0]
else:
return Concatenate(axis=axis)(inputs)
def combined_dnn_input(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_dnn_input = Flatten()(concat_func(sparse_embedding_list))
dense_dnn_input = Flatten()(concat_func(dense_value_list))
return concat_func([sparse_dnn_input, dense_dnn_input])
elif len(sparse_embedding_list) > 0:
return Flatten()(concat_func(sparse_embedding_list))
elif len(dense_value_list) > 0:
return Flatten()(concat_func(dense_value_list))
else:
raise "dnn_feature_columns can not be empty list"
def get_linear_logit(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten()(sparse_linear_layer)
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1)(dense_linear)
linear_logit = Add()([dense_linear_layer, sparse_linear_layer])
return linear_logit
elif len(sparse_embedding_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten()(sparse_linear_layer)
return sparse_linear_layer
elif len(dense_value_list) > 0:
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1)(dense_linear)
return dense_linear_layer
else:
raise "linear_feature_columns can not be empty list"
########################################################################
#################定义模型##############
########################################################################
def WideDeep(
linear_feature_columns,
dnn_feature_columns,
dnn_hidden_units=(128, 128),
dnn_dropout=0,
dnn_activation='relu',
dnn_use_bn=False,
reweight=False,
seed=1024):
"""
Instantiates the Wide&Deep Learning architecture.
Args:
linear_feature_columns: An iterable containing all the features used by linear part of the model.
dnn_feature_columns: An iterable containing all the features used by deep part of the model.
dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of DNN
dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
dnn_activation: Activation function to use in DNN
dnn_use_bn: bool. Whether use BatchNormalization before activation or not in deep net
reweight: bool, False: no need sample_weight , True: support reweight and input should contain sample_weight
seed: integer ,to use as random seed.
return: A TF Keras model instance.
"""
features_columns = linear_feature_columns + dnn_feature_columns
# 构建 embedding_dict
embedding_matrix = build_embedding_matrix(features_columns)
embedding_dict = build_embedding_dict(features_columns, embedding_matrix)
# 特征处理
features = build_input_features(feature_columns)
inputs_list = list(features.values())
linear_sparse_embedding_list, linear_dense_value_list = input_from_feature_columns(features, linear_feature_columns, embedding_dict)
linear_logit = get_linear_logit(linear_sparse_embedding_list, linear_dense_value_list)
dnn_sparse_embedding_list, dnn_dense_value_list = input_from_feature_columns(features, dnn_feature_columns, embedding_dict)
dnn_input = combined_dnn_input(dnn_sparse_embedding_list, dnn_dense_value_list)
# DNN
for i in range(len(dnn_hidden_units)):
if i == len(dnn_hidden_units) - 1:
dnn_out = CustomDense(units=dnn_hidden_units[i],dropout_rate=dnn_dropout,
use_bn=dnn_use_bn, activation=dnn_activation, name='dnn_'+str(i))(dnn_input)
break
dnn_input = CustomDense(units=dnn_hidden_units[i],dropout_rate=dnn_dropout,
use_bn=dnn_use_bn, activation='relu', name='dnn_'+str(i))(dnn_input)
dnn_logit = Dense(1, use_bias=False, activation=None, name='dnn_logit')(dnn_out)
final_logit = Add()([dnn_logit, linear_logit])
output = tf.keras.layers.Activation("sigmoid", name="wdl_out")(final_logit)
if reweight:
model = ReweightModel(inputs=inputs_list, outputs=output)
else:
model = Model(inputs=inputs_list, outputs=output)
return model
model = WideDeep(
linear_feature_columns,
dnn_feature_columns,
dnn_hidden_units=(128, 128),
dnn_dropout=0,
dnn_activation='relu',
dnn_use_bn=False,
reweight=True,
seed=1024)
model.compile(optimizer="adam", metrics=tf.keras.metrics.AUC(name='auc'))
log_dir = '/tensorboardshare/logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tbCallBack = TensorBoard(log_dir=log_dir, # log 目录
histogram_freq=0, # 按照何等频率(epoch)来计算直方图,0为不计算
write_graph=True, # 是否存储网络结构图
write_images=True, # 是否可视化参数
update_freq='epoch',
embeddings_freq=0,
embeddings_layer_names=None,
embeddings_metadata=None,
profile_batch = 20)
total_train_sample = 10
total_test_sample = 10
train_steps_per_epoch=np.floor(total_train_sample/batch_size).astype(np.int32)
test_steps_per_epoch = np.ceil(total_test_sample/val_batch_size).astype(np.int32)
history_loss = model.fit(dataset, epochs=3,
steps_per_epoch=train_steps_per_epoch,
validation_data=dataset_val, validation_steps=test_steps_per_epoch,
verbose=1, callbacks=[tbCallBack])基于wide&deep的reweight模型定义好了,最后看下模型结构
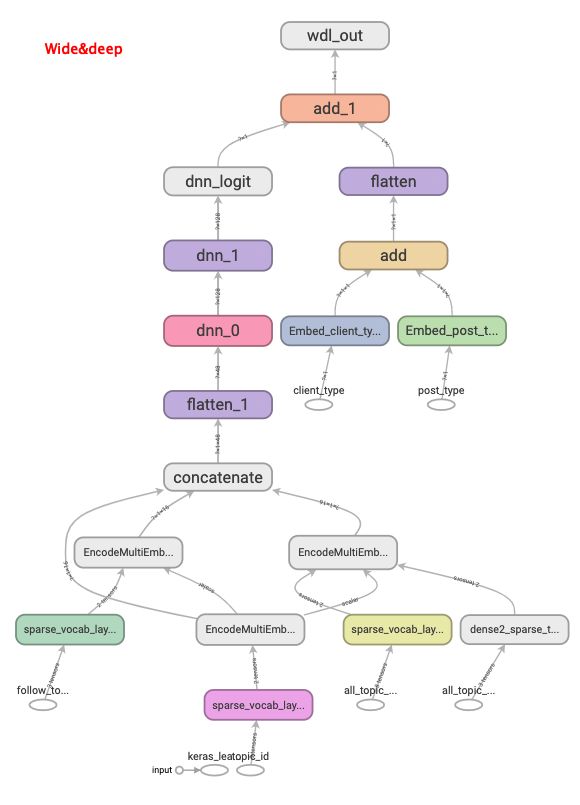
参考文献
琦琦:蘑菇街首页推荐多目标优化之reweight实践:一把双刃剑?
SunSuc:推荐系统中如何做多目标优化
美团“猜你喜欢”深度学习排序模型实践
MMoE论文笔记 - 滴水不穿石 - 博客园
shenweichen/DeepCTR
