重新思考人体姿态估计 Rethinking Human Pose Estimation
转载自https://zhuanlan.zhihu.com/p/72561165
重新思考人体姿态估计 Rethinking Human Pose Estimation
浅谈:2D人体姿态估计基本任务、研究问题、意义、应用、研究趋势、未来方向以及个人思考
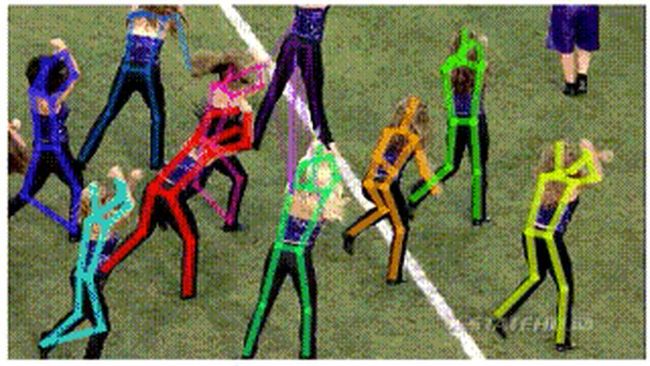
1.基本定义:从单张RGB图像中,精确地识别出多个人体的位置以及骨架上的稀疏的关键点位置。
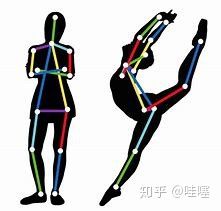

2.基本任务:给定一张RGB图像,定位图像中人体的关键点位置,并确定其隶属的人体。
按照人的直观视觉理解的话,主要会涉及到以下问题:
- 关键点及周围的局部特征是什么样的?
- 关键点之间、人体肢体的空间约束关系是什么样的,以及层级的人体部件关系是什么样的?
- 不同人体之间的交互关系是什么样的,人体与外界环境之间的交互关系是什么?
基于Deep CNN的方法的试图通过神经网络的拟合能力,建立一种隐式的预测模型来避开上述的显式问题:
- 基于去显式分析人体姿态问题的方法是有的,传统的Pictorial Structure[1]是其中一个较为经典的算法思路,目前也有少数方法用part-based[2]的层级树结构建立人体姿态模型并利用CNN,来进行学习与预测。
- 当下多数深度CNN回归的方式, 试图用模型强大的拟合能力去回避以上的显式问题,而从大量的图像数据和标签监督信息中用神经网络去学习图像数据与构建的标签信息之间的映射。
当前深度学习依然还是把CNN看成是 black box “黑盒”来进行训练与推理,但随着神经网络架构的日益复杂化,大家对模型的可解释性以及透明性有了更髙的需求。随着可解释性AI的发展,越来越多的工作开始研究模型如何做出决策时,以及其内部到底发生了什么。目前已经有工作 [3]开始研究人体姿态估计模型的可解释性。
3.当前主流研究的基础问题和难点:
神经网络结构的设计是个永远(当下)都会伴随的问题(假如深度学习的热潮没有退去的话)
Top-down:先检测人体,再做单人姿态估计的两阶段方法。(G-RMI[4], RMPE[5], CPN[6], SimpleBaseline[7],HRNet[8], ...)
- 必然受到了目标检测任务的制约。
- 基于bounding box的单人姿态估计问题,在面对遮挡问题容易受到挫折。
- 精度虽然髙实时性能较差,运行推断时间runtime和检测的人数成正比关系
- 小尺寸图像受限
Bottom-up:针对整副图像的多人关键点检测,检测所有关键点候选位置的同时,一般会用一定的算法关联或匹配到相关人体(OpenPose[9]的动态规划, Associative Embedding[10]的tag匹配, PersonLab[11]的贪婪解码算法等等)。(Deepcut[12], OpenPose, Aassociative Embedding, PersonLab)。个人认为Bottom-Up方法才是更值得研究的思路,是走向实时姿态估计的主要途径。ICCV-19, 也提出了Single-stage Multi-person Pose Machine[13], 其实也是可以看成一种bottom-up的方法, 它类似于19-arxiv-Objects as Points[14] 的思路, 因为有中心点的参考, 就弱化了对设计多人人体匹配算法的需求,类似的还有19-arxiv-DirectPose[15]工作.
- 精度不如Top-down的更加精准,但实时性能较好
- bounding box free
- 面对拥挤问题、遮挡问题仍然容易受到挫折
- 图像上的人体的尺度大小,未经归一化,分布很不均匀,关键点特征的提取难大于Top-down的方法 (19-arxiv-Bottom-up Higher Resolution Network[16]在尝试不使用多尺度test来克服这个问题)
- 小尺寸图像的量化精度问题 (PersonLab, PifPaf[17]的offset预测)
量化精度问题: G-RMI预测short offset弥补; 最大峰值与次峰的1/4偏移处的经验估计法; numerical coordinate regression利用soft-argmax将heatmaps转换为joints coordinates[18]; 2020-CVPR-DarkPose-Distribution-Aware Coordinate Representation[19]假设高斯分布用泰勒展开来估计真实位置. 量化精度问题实际上是一种工程问题, 它的本质来源在于, 计算机图像像素位置处于离散空间, 但是真实关键点位置位于连续空间,很多数据变换公式只能近似到离散的像素位置, 所以很多估计都是有偏的, 也有论文2020-CVPR-The Devil is in the Details: Delving into Unbiased Data Processing[20] 在讨论姿态估计中数据变换出现的偏差问题.
4.方法分类:
- 标准1 PipeLine:Top-Down和Bottom-up的方法。
- 标准2 全局关系-部分关系:全局的长距离关系的隐式学习问题(大多数)和基于part的中短距离关系学习问题(ECCV-18 PersonLab,ECCV-18 Deeply learned compositional models[21])的学习问题
- 标准3 输出表示:heatmap回归(大多数),直接坐标回归方法(CVPR-14-DeepPose[22],ECCV-18的Integral Pose[23]),向量场嵌入(CVPR-17 G-RMI、OpenPose,ECCV-18 PersonLab,CVPR-19 PIFPAF)的方法等等
5.近几年的代表作
2013~2014
发迹于2013, 2014年, ICLR 2013 Learning Human Pose Estimation Features with Convolutional Networks[24]。2014 CVPR: Google的DeepPose, 同年出现了MPII[25]数据集(Max-Planck )以及MS-COCO[26]数据集。NeurIPS还出现了纽约大学LeCun等人将CNN和Graphical Model联合训练[27],并使用了heatmap的表示方法。
2016
CVPR:CMU的Convolutional Pose Machine (CPM)[28]和德国的马克斯普朗克研究所Deepcut以及Stacked Hourglass[29] 网络结构设计的出现。
2017
CVPR:Google的G-RMI开启基于目标检测的人体姿态估计方法。Multi-context Attention的方法,将注意力机制的进入。CMU的OpenPose系统出现,致力于打造实时姿态估计系统。Deepcut的改进版DeeperCut出现。同年ICCV上,Learning Feature Pyramids, Mask RCNN[30]、上海交通大学的RMPE以及随后的AlphaPose崭露头角, NeurIPS17也出现了 Associative Embedding 以新的端到端的方式来避免人体姿态估计多阶段不连续学习的问题。
2018
CVPR上出现了旷世的CPN拿下了17年COCO挑战赛的冠军, ECCV上微软亚洲研究院的SimpleBaseline用自上而下的方法为姿态估计打造最简单的baseline,并刷新了COCO数据集的新高。ECCV上还出现了来自中东技术大学的Muhammed Kocabas提出了MultiPoseNet[31],利用soft-argmax解决argmax不可微和量化误差的Integral Human Pose 以及Google的自下而上多任务的新作PersonLab, 值得一提的是还有一些开辟新的研究角度的方法如ECCV上美国西北大学part-based的姿态估计方法Deeply learned compositional models 。18年的另外一个趋势就是,新问题新任务的出现,比如CVPR18的DensePose[32]标志着密集关键点人体姿态估计任务的出现, 2D pose track 任务(CVPR18 PoseTrack[33]数据集)的提出, 以及3D 姿态估计问题的兴起......
2019
CVPR, 姿态估计再次呈现一个小爆发. HRNet的出现, 成为了姿态估计任务中更强的baseline模型, 其结构本身也具备较强的泛化性, 可以作为backbone的候选. 19 CVPR上还有 PIFPAF,针对小尺度的姿态, Enhanced Channel-Wise and Spatial Information Pose[34]加入attention的模块到神经网络结构中 ,Related Parts Help[35] 探讨了将人体部件划分为多个group进行学习的好处,Crowded Pose [36]针对拥挤场景, Fast Human Pose [37]使用大模型的知识蒸馏训练小模型,Pose2Seg[38]引入像素分割等等, ICCV19 上也有了 single-stage multi person pose machines, 大量的研究在探讨姿态估计的问题, 并且3D 姿态估计即将成为主流。 当然, 2D姿态估计任务仍然是值得去深入探讨的问题, 因为一些本质上的难题目前还没有完全的洞察和有效的解决方案, 比如严重遮挡,多人重叠问题等等。另外, 数据集MPII, COCO数据集上的"刷性能" 也依然是大家孜孜不倦的追求,性能再次来到了新高。
可以看出来几条结论,
1. 引领姿态估计潮流的有几伙子人
2.美国 德国 的研究机构是 姿态估计的 “始作俑者”,亚洲人后来者居上
3. 欧美国家喜欢方法创新,以及新问题的提出,中国研究机构更擅长占据性能的榜首
2020
时间走到了2020,3D,似乎已经成为了人体姿态估计的主旋律。实际上,在2020年之前,3D姿态估计也已经有了大量的研究进展,本博客不再整理以往年份的3D姿态估计论文,具体可以参考这个Github的整理 [39]。或者可以留言补充。
CVPR上:VIBE: Video Inference for Human Body Pose and Shape Estimation[40] ,MPI的Muhammed Kocabas,Michael J. Black 等人以视频为数据源,利用可以CNN和GRU来生成连续帧的人体表面模型SMPL的pose参数和shape参数,然后利用motion discriminator来区分生成的参数和数据集的中真实标注参数,进行生成对抗训练,此外3D到2D的re-projection loss也可以将多个2D和3D数据集的标注用到一个统一的框架,这个工作是2018年CVPR的End-to-end recovery of human pose and shape[41]的延续; Epipolar Transformer[42],CMU的Yihui He等人利用多视角的3D特征来帮助2D检测器来预测有遮挡的关键点,用query做内积来匹配多视角的3D特征并融合;Compressed Volumetric Heatmaps[43],是意大利University of Modena and Reggio Emilia的研究者提出的一种,用压缩编码来表征多人3D人体Heatmaps,然后预测这个解码并恢复3D heatmaps,解码时用到来一个启发式的距离匹配人体算法。Higher HRNet[44] 在 HRNet的基础上针对Bottom-up方法可能出现的人体尺度上的变化,提升了输出分辨率,并结合Associative Embedding 的loss进行多人人体关联。ECCV 上, RSN[45] 的神经网络架构取得了更髙的性能;Whole-Body Human Pose Estimation in the Wild[46] 提出了更加丰富的人体关键点标注数据。另外还有一些前面提到的工作DarkPose[19]和The devil in details[20]等等。
对于2D多人姿态估计来讲,其难题仍然是在互遮挡、自遮挡、复杂背景环境干扰。为什么难以解决?一方面可能是因为当前的深度学习模型有其历史上的局限性,另一方面可能是我们研究问题本身就是病态(ill-posed)问题或者是不完备问题。另外,2D姿态估计研究空间上的相互挤占,”创新空间“似乎已经变成了“红海”,而3D姿态估计丰富的切入点,似乎展现出了一片欣欣向荣的“蓝海”?2D 关键点预测是姿态估计任务的基础性研究问题,但它并不是代表着姿态估计就仅仅是预测关键点,其本身难以克服的问题如拥挤、自遮挡或相互遮挡,就是因为深度、3D信息的缺乏而导致,也许只有上升到3D的层面时才能被解决。
6.研究意义:
- 3D人体姿态估计的铺垫、3维人体重建的必备技术 (从2维到3维,从姿态到形态)
- 人体关键点的视频追踪问题的基础(从静态到动态)
- 动作识别的信息来源(从关键点的时序空间特征映射到动作语义问题)
7.应用:
- 自动驾驶行业:自动驾驶道路街景中行人的检测以及姿态估计、动作预测等问题
- 娱乐产业:动作特效的增加。快手、抖音、微视等视频软件,但娱乐是一种锦上添花的需求,而非必要,人工智能不应该满足于”娱乐至上“的精神。
- 安全领域:行人再识别问题,以及特殊场景的特定动作监控,婴儿、老人的照顾。
- 影视产业:拍电影特效(复仇者联盟拍摄主要靠动作捕捉衣,是不是可以应用视觉技术?)
- 人机交互:AR,VR,以及未来的人机交互方式
- 产业界应该探索更多潜在的应用
8.研究趋势的变化以及扩展:
- 3D (甚至 4D,5D, 6D,...)人体姿态估计的流行, 大量的论文出现...
- 稀疏关键点到密集关键点(CVPR-18 FaceBook DensePose[47])
- 静态图像到视频追踪 (CVPR-18 PoseTrack[48])
- 从关键点定位到肢体的像素分割预测 (pose parsing,CVPR-19 pose2seg[38])
- 从监督学习到弱监督 、自监督,甚至无监督有可能(如, ICLR-2019 unsupervised discovery, parts, structure and dynamics [49],NeurIPS-2019 Learning Temporal Pose Estimation from Sparsely-Labeled Videos[50])
- 当然:神经网络结构的设计也是一个必不可少的环节:从CVPR-16-CPM, ECCV-16-Stacked Hourglass, ECCV-18 SimpleBaseline,CVPR-18 CPN, CVPR-19 HRNet,CVPR-19 Enhanced Channel-wise and Spatial Information,ICCV FPN-Pose, arXiv-19-MSPN-Rethinking Multi-stage Networks for Human Pose Estimation[51],多尺度融合、多阶段级联、堆叠等等等等,用于姿态估计神经网络的结构层出不穷 , 甚至NAS for human pose estimation也是有可能,比如19-arXiv-Pose Neural Fabrics Search[52] 引入人体结构先验知识引导神经网络搜索,自动搜索出多个part-specific结构的子网络对应不同人体部件。如深度学习的热潮没有退去的话,神经网络结构的设计会是一个永远都会伴随的问题,只是其重要程度和切入的视角在不断地发生变化。
- 人体属性、穿衣风格、人体动作的迁移 , 如2019-ICCV-Everybody Dance Now[53], 2020-CVPR-Neural Pose Transfer.[54]
- 2020年,神经网络搜索NAS在姿态估计领域也取得了新的进展,20-arxiv-AutoPose 利用强化学习搜索多分支融合,2020-arxiv-Evo2dPose[55]利用进化算法搜索高效的模型,2020-arxiv-ScaleNAS[56]在类似HRNet的搜索空间中进行架构搜索,类似的还有2020-EfficientPose[57],2020-MM-PoseNAS[58]模型等等。
- 有2020-arxiv-TransPose[3]:towards explainable human pose estimation by Transformer利用Transformer的注意力机制来揭示模型预测的人体关键点位置依靠什么样的空间依赖
- 2020-arxiv-rethinking heatmap regression for Bottom-up HPE[59] 利用可学习的高斯核标准差来解决Bottom-up方法中不同人体的尺度变化问题。另外,也有一个综述性文章Deep Learning-Based Human Pose Estimation: A Survey[60]全面介绍姿态估计领域最近几年的发展。
- 数据收集层面:更先进的传感器感知和更可靠的数据,比如的iPhone 12上已经配备LiDar-激光雷达采集3D 点云,当前手机已经配备了收集深度信息的传感器。
个人思考
当前所有的姿态估计方法几乎都使用了深度卷积神经网络的强大功能,但个人认为神经网络设计绝不是解决该问题的核心,用力搔靴和脱掉鞋子,哪个才是更好的止痒手段呢?
关于应用与产品 (2019-11-19)
人体姿态估计是一个综合的问题,有很多的切入点和难题值得去研究,并且它是一个尚未实际落地的计算机视觉技术。在这个层面上,AI的产品经理们和投机者们应该想想这项技术怎么能更好地服务大众,并带来市场和利润。
作为科学研究者,赚钱的考虑或应该暂时放到明天。我想讨论的是: 当我们面对一项任务和难题, 我们是应该忽略固有的困难和问题,提出新的问题,给出问题方案,去探索新的研究趋势呢?还是强行深入当前的固有问题,解决当下的难题呢? 是不是有一些的问题是超前式的,也许放到以后才会有更加合适的方案和角度来解决?
关于研究方向 (2019-11-19)
或者说,我们还可以用另一种粗暴的方案:把这一问题黑箱化或者半黑箱化,然后从神经网络结构设计、数据处理、增强以及其他机器学习数学方法去暴力式的解决。这样的解决方式实际上是,摒弃了人类本身做姿态估计的直观思路(上面所述),而是从更加“机器学习”的角度去处理这个问题。假如,我们寻找到一个“完美”结构的神经网络,让它去达到100%或者近似100%的准确率!这样以来,似乎预测问题被完完全全地解决了,但是问题是,我们不知道能不能找到这样的结构或者技术,或者说一旦找到了以后能不能解释性地理解这一技术? 这就又引出了大家探讨争论许久的可解释性问题、显式推理问题。也许PersonLab和PifPaf的工作值得去思考,继续引入复合场(Composite Field)的概念,预测人为设计好的高维度向量来处理人体姿态预测问题,让模型预测更加巧妙的监督信息, 并且能降低量化误差,设计保持期望的一致性的关联肢体得分公式,再加之快速贪心算法,利用人体的连通特性就能得到多人姿态。这样的设计与算法,尽管性能比那些注重网络结构设计的差一些,但却遵循合理的直觉,有可解释性, 这是不是需要我们更多的关注?
另外,有学者甚至提出了无监督的方式处理人体部件。 我认为这是一种可以去探索的问题, 因为人体姿态本身其实可以看成图像中的特征簇, 其视觉上的连通特性本身就具备了高维空间上的独特性. 那么生成模型, 无监督学习在直觉上是可行的吗? 如果再加上视频,光流等辅助信息, 是不是就可以从大量无标签的图像数据中, 准确构建人体部件的特征、部件到整体的结构特征以及人体姿态的运动时序特征? 这可能又会是一个新的思路和解决人体姿态估计任务的新手段吗?
关于数据以及人本身 (2020-6-9)
遵循所谓的第一性原理,我们在进行姿态估计问题研究时,也可以进行下面几个单纯的思考:
1.我们可获得的数据与标注是什么样的形式?
2.我们期望模型能够从中获得的目标是什么样的形式?
3.从我们的数据源,到我们期望获得的目标形式之间,信息整合加工的过程是否可靠?
我们人眼双目感知的人体姿态是在3D真实空间中的,我们有深度(远近)上的感知定义上,以及可获取的数据源上。2D图像是3D真实物体通过摄像机进行不可逆转的投影成像(请参考小孔成像原理,相机坐标系到像平面坐标系的转换)而得到的。
所谓的“遮挡”,我们剖析其物理原因,即:不同的物体或者部件出现了相同的成像位置上,而遮挡物距离观察者(人眼或者相机)更近,被遮挡物的反射光线传播不到观察者。
拿关键点定位来讲,比如,对于手腕类型关键点,假如两个人的左手腕离得比较近,而A的遮住了B的左手腕。然而对于3D维空间本身来讲,在同一个绝对3D位置上是不可能出现两个不同的物体的。这就说明相机模型成像本身有其固有的缺陷,当然我们不能说是缺陷,相机本身就是一种人类记录影像的伟大发明了,自然赋予人类视觉,人类记录自然以数字图像。那我们人眼也是按照光学成像,为什么人类这么擅长做“人体姿态估计”?
大概因为:
- 双目的3D感知。在观察一个真实的3D空间场景时,人有双眼。即使假设人的一只眼和相机模型具备同样的2维成像原理,但是,双目就具备了3D空间上的感知能力,所以人的双目视觉系统是天生具备对极几何的处理能力。
- 逻辑推理及高阶的语义表达。人在观察一副成像的2D RGB图像时,人有推理能力。可以利用自己关于人体结构的常识以及图像整体和局部的线索进行推理,比如,我们看到了领带,我们知道人的躯干和头部在哪。即使某些人体部分被遮挡,我们仍然可以用可见的部分去猜测他们的位置。
- 大量的先验知识、常识构造出思维中的人体模型。人类自出生起就开始观察、学习、认知同类的外貌、身体结构、姿态。关于人体结构的先验和大量姿态的记忆已经潜移默化地成为了我们认知中的常识模型。我们学习到了一个非常全面细致的参数模型!这个思维中的参数模型可能比常见的SMPL参数模型更强大。
综上所说,我们的进步,不只包括利用最先进的技术来优化我们的模型,来对RGB图像中的内容进行预测、推理、解释、分析,也包括使用更先进的传感器和更可靠的数据,来给我们的"智能机器"提供更多维度的数据源信息。
本文长期更新, 致力于反映姿态估计领域的发展~欢迎各位探讨或补充~
Newly: 2021-1-13
参考
- ^Felzenszwalb et al. Pictorial structures for object recognition. International Journal of Computer Vision (IJCV), 61(1):55–79, 2005.
- ^Felzenszwalb et al. A discriminatively trained, multiscale, deformable part model. In CVPR, volume 2, page 7, 2008
- ^abTransPose: Towards Explainable Human Pose Estimation by Transformer https://arxiv.org/abs/2012.14214
- ^George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, and Kevin Murphy. Towards accurate multi-person pose estimation in the wild.
- ^Hao-Shu Fang, ShuqinXie,Yu-WingTai,andCewuLu. Rmpe:Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2334–2343, 2017.
- ^Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7103–7112, 2018
- ^ Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pages 466–481, 2018.
- ^Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose esti-mation. In CVPR, 2019.
- ^Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multiperson 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7291–7299, 2017.
- ^Alejandro Newell, Zhiao Huang, and Jia Deng. Associative embedding: End-to-end learning for joint detection and grouping. In Advances in Neural Information Processing Systems (NeurIPS), pages 2277–2287, 2017.
- ^George Papandreou, Tyler Zhu, Liang-Chieh Chen, Spyros Gidaris, Jonathan Tompson, and Kevin Murphy. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), 2018.
- ^Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter V. Gehler, and Bernt Schiele. Deepcut: Joint subset partition and labeling for multi person pose estimation. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4929–4937, 2016.
- ^Nie, Xuecheng, Jianfeng Zhang, Shuicheng Yan, and Jiashi Feng. "Single-Stage Multi-Person Pose Machines." arXiv preprint arXiv:1908.09220 (2019).
- ^Zhou, Xingyi, Dequan Wang, and Philipp Krähenbühl. "Objects as Points." arXiv preprint arXiv:1904.07850 (2019).
- ^Zhi Tian, Hao Chen, Chunhua Shen. "DirectPose: Direct End-to-End Multi-Person Pose Estimation." arXiv preprint arXiv:1911.07451(2019).
- ^Cheng, Bowen, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S. Huang, and Lei Zhang. "Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation." arXiv preprint arXiv:1908.10357 (2019).
- ^Kreiss, Sven, Lorenzo Bertoni, and Alexandre Alahi. "Pifpaf: Composite fields for human pose estimation." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11977-11986. 2019.
- ^Nibali, A., He, Z., Morgan, S., Prendergast, L.: Numerical coordinate regression with convolutional neural networks. arXiv preprint arXiv:1801.07372 (2018)
- ^abZhang, Feng, Xiatian Zhu, Hanbin Dai, Mao Ye, and Ce Zhu. "Distribution-Aware Coordinate Representation for Human Pose Estimation." arXiv preprint arXiv:1910.06278 (2019).
- ^abJunjie Huang, Zheng Zhu, Feng Guo, Guan Huang, "The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation." arXiv preprint arXiv:1911.07524 (2019).
- ^Wei Tang, Pei Yu, and Ying Wu. Deeply learned compositional models for human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 190–206, 2018.
- ^Toshev, Alexander, and Christian Szegedy. "Deeppose: Human pose estimation via deep neural networks." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1653-1660. 2014.
- ^Sun, Xiao et al. “Integral Human Pose Regression.” ECCV (2018). https://arxiv.org/abs/1711.08229
- ^Learning Human Pose Estimation Features with Convolutional Networks Jain, A., Tompson, J., Andriluka, M., Taylor, G.W., & Bregler, C. (ICLR 2013),
- ^Andriluka et al. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition (CVPR), pages 3686–3693, 2014.
- ^Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- ^Jonathan J Tompson, Arjun Jain, Yann LeCun, and Christoph Bregler. Joint training of a convolutional network and a graphical model for human pose estimation. In Advances in Neural Information Processing Systems (NeurIPS), pages 1799–1807, 2014.
- ^Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4724–4732, 2016
- ^Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 483–499. Springer, 2016.
- ^Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2961–2969, 2017.
- ^Muhammed Kocabas, Salih Karagoz, and Emre Akbas. Multiposenet:Fast multi-person pose estimation using pose residual network. InProceedings of the European Conference on Computer Vision (ECCV),pages 417–433, 2018
- ^Alp Güler, Rıza, Natalia Neverova, and Iasonas Kokkinos. "Densepose: Dense human pose estimation in the wild." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7297-7306. 2018.
- ^Andriluka, Mykhaylo, et al. "Posetrack: A benchmark for human pose estimation and tracking." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
- ^Su, Kai, Dongdong Yu, Zhenqi Xu, Xin Geng, and Changhu Wang. "Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5674-5682. 2019.
- ^Wei Tang and Ying Wu. Does learning specific features for related parts help human pose estimation? In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- ^Li, Jiefeng, Can Wang, Hao Zhu, Yihuan Mao, Hao-Shu Fang, and Cewu Lu. "Crowdpose: Efficient crowded scenes pose estimation and a new benchmark." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10863-10872. 2019.
- ^Feng Zhang, Xiatian Zhu, and Mao Ye. Fast human pose estimation. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3512–3521, 2019.
- ^abZhang, Song-Hai, Ruilong Li, Xin Dong, Paul Rosin, Zixi Cai, Xi Han, Dingcheng Yang, Haozhi Huang, and Shi-Min Hu. "Pose2Seg: Detection Free Human Instance Segmentation." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 889-898. 2019.
- ^awesome-human-pose-estimation https://github.com/wangzheallen/awesome-human-pose-estimation#3d-pose-estimation
- ^VIBE: Video Inference for Human Body Pose and Shape Estimation http://arxiv.org/abs/1912.05656
- ^End-to-end recovery of human pose and shape https://arxiv.org/pdf/1712.06584.pdf
- ^Epipolar Transformer https://arxiv.org/abs/2005.04551
- ^Fabbri et al. Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation, In CVPR, 2020
- ^HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation https://arxiv.org/abs/1908.10357
- ^Learning Delicate Local Representations for Multi-Person Pose Estimation https://arxiv.org/abs/2003.04030
- ^https://arxiv.org/abs/2007.11858
- ^http://densepose.org
- ^https://posetrack.net/
- ^unsupervised discovery, parts, structure and dynamics
- ^Learning Temporal Pose Estimation from Sparsely-Labeled Videos
- ^Li, Wenbo, Zhicheng Wang, Binyi Yin, Qixiang Peng, Yuming Du, Tianzi Xiao, Gang Yu, Hongtao Lu, Yichen Wei, and Jian Sun. "Rethinking on Multi-Stage Networks for Human Pose Estimation." arXiv preprint arXiv:1901.00148 (2019).
- ^Yang, Sen, Wankou Yang, and Zhen Cui. "Pose Neural Fabrics Search." arXiv preprint arXiv:1909.07068 (2019).
- ^https://arxiv.org/pdf/1808.07371.pdf
- ^Neural Pose Transfer By Spatially Adaptive Instance Normalization. In CVPR, 2020
- ^Pushing the Boundaries of 2D Human Pose Estimation using Neuroevolution
- ^ScaleNAS: One-Shot Learning of Scale-Aware Representations for Visual Recognition https://arxiv.org/abs/2011.14584
- ^EfficientPose: Efficient Human Pose Estimation with Neural Architecture Search
- ^Pose-native Network Architecture Search for Multi-person Human Pose Estimation https://dl.acm.org/doi/10.1145/3394171.3413842
- ^Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation https://arxiv.org/abs/2012.15175
- ^Deep Learning-Based Human Pose Estimation: A Survey https://arxiv.org/abs/2012.13392