AdaBoost算法搭建信用卡精准营销模型
背景
近年来,越来越多的人习惯使用信用卡来消费,而各大银行金融机构也纷纷投入更多的资源来抢占信用卡业务市场份额,因此信用卡产业飞速发展。由于市场竞争激烈,“僧多肉少”、同质化的局面越来越严重,商业银行迫切需要一个方便快捷、精准有效的方式拓宽自身的客户规模,从而降低成本,提高收益及自身竞争力。
模型搭建
模型搭建分4个步骤:读取特征数据(features)、提取特征变量及目标变量(extract_features)、将数据集分为训练集(training_set)和测试集(testing_ set)、模型训练(training_model)。
1.读取数据
本示例中,我选取了1000条数据,为了便于展示,我选取了6个特征(现实中肯定有很多特征变量):年龄、月收入、月消费、性别、月消费/月收入、学历。
import pandas as pd
df = pd.read_excel('信用卡精准营销模型.xlsx')
2. 提取特征变量及目标变量
X = df.drop(columns='响应') # 将数据文件除字段“响应”外,保存为DataFrame格式
y = df['响应']提取得到的X和y分别如下:

2. 将数据集分为训练集和测试集
在这里,我将数据集的80%作为训练集,20%作为测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)其中,参数test_size是测试集数据;
参数random_state设置为42(这个参数没有特殊含义,可以换成其他数值,上下保持一致即可)。
3. 模型训练
分好训练集和测试集后,接下来就可以训练模型了,即从Scikit-Learn库中导入AdaBoost分类模型进行模型训练:
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(random_state=42)
clf.fit(X_train, y_train4.模型预测及评估
上述过程已经得到了训练好的模型,接下来就是对测试集进行预测。
y_pred = clf.predict(X_test)
print(y_pred)打印出来的y-pred结果如下:

通过代码看可以显示预测值与实际值的差异,在这里,我只显示了前五条数据:
a = pd.DataFrame()
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()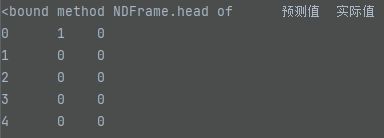
查看上图,我们可以看到,预测值与实际值仅有1个不同。为了更好的显示预测的准确性,我通过以下代码计算预测值与实际值两者之间的准确度。
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)运行上述代码后,得到的score为0.86,说明该模型预测的准确度达到0.86。 由于AdaBoost分类模型是弱学习器分类决策树,其本质上预测的并不是准确的0或1的分类,而是预测属于某一类的概率,通过如下代码可以查看预测属于各个分类的概率。
y_pred_proba = clf.predict_proba(X_test)
print(y_pred_proba[0:5])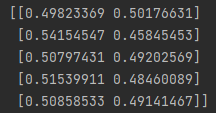
下面,我们还可以通过绘制ROC曲线来评估模型的预测效果,代码如下:
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test.values, y_pred_proba[:, 1])
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.show()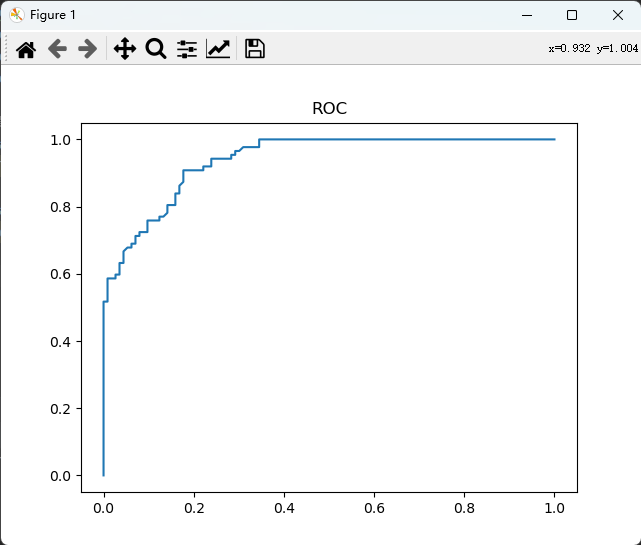
通过如下代码计算模型的AUC值:
from sklearn.metrics import roc_auc_score
auc = roc_auc_score(y_test, y_pred_proba[:,1])
print(auc)计算得到0.9402(最大值是1),说明该模型的预测效果良好。同时,为了更好地了解到哪些特征对模型有重大的影响,以便后期可以更好地选择特征变量来训练模型,从而提高模型的预测性能,相关代码如下:
features = X.columns # 获取特征名称
importances = clf.feature_importances_ # 获取特征重要性
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)结果如下:

可以看出,特征的重要性由高至低依次为“月消费/月收入”、“月消费”、“月收入”、“学历”、“年龄”和“学历”。