知识图谱简介
知识图谱 (Knowledge Graphs, KGs) 已成为组织世界结构化知识的一种引人注目的抽象,并作为一种整合从多个数据源中提取的信息的方式。 知识图谱已经开始在表示使用自然语言处理和计算机视觉提取的信息方面发挥核心作用。 以 KG 表示的领域知识正在输入到机器学习模型中,以产生更好的预测。 我们在这篇博文中的目标是 (a) 解释 KGs 的基本术语、概念和用法,(b) 突出 KGs 的近期应用,这些应用导致其受欢迎程度激增,以及 (c) 将 KGs 置于整体 人工智能的风景。 在阅读更广泛的综述或关注有关该主题的研究研讨会之前,这篇博文是一个很好的起点。
知识图谱定义
有向标记图是一个 4 元组 G = (N, E, L, f),其中 N 是一组节点,E ⊆ N × N 是一组边,L 是一组标签,f: E→L,是从边到标签的分配函数。 将标签 B 分配给边 E=(A,C) 可以被视为三元组 (A, B, C) 并可视化,如图 1 所示。
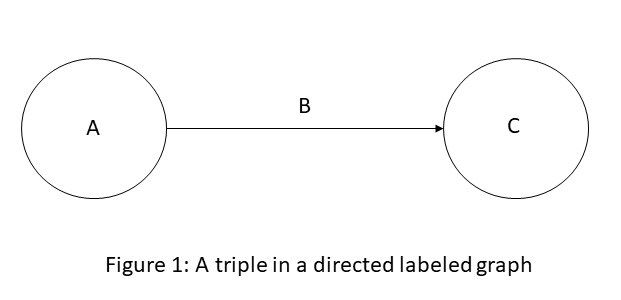
知识图谱是有向标记图,其中我们将特定领域的含义与节点和边相关联。 任何东西都可以充当节点,例如人、公司、计算机等。边缘标签捕获节点之间的利益关系,例如,两个人之间的友谊关系,公司和人之间的客户关系,或 两台计算机之间的网络连接等。
有向标记图表示根据应用程序的需要以多种方式使用。 有向标记图,例如节点是人,边捕获父关系的有向标记图也称为数据图。 一个有向标记图,其中节点是对象的类别(例如,书籍、教科书等),并且边缘捕获子类关系,也称为分类法。 在某些数据模型中,给定一个三元组 (A,B,C),我们将 A、B、C 分别称为三元组的主语、谓语和宾语。
知识图谱用作应用程序存储信息的数据结构。 可以通过人工输入、自动化和半自动化方法的组合将信息添加到知识图谱中。 无论采用何种知识录入方式,都希望记录的信息易于被人类理解和验证。
图上的许多有趣的计算可以简化为导航它。 例如,在一个友谊 KG 中,要计算一个人 A 的朋友的朋友,我们可以将图从 A 导航到通过标记为朋友的关系连接到它的所有节点 B,然后递归到由 每个 B 的朋友关系。
知识图谱的最新应用
使用有向标记图作为存储信息的数据结构,以及使用图算法来操作该信息并不是什么新鲜事。 在计算机科学中,有向图表示有很多用途,例如,数据流图、二元决策图、状态图等。我们在这里考虑两个具体应用,它们导致最近知识图的普及激增 :通过互联网组织信息和企业中的数据集成。 在讨论这些应用程序时,我们还强调了知识图谱的使用方面的新变化和不同之处。
通过 Internet 组织知识
考虑 Google 搜索“Winterthur Zurich”,它返回图 2 左侧面板中显示的结果以及右侧面板中来自 Wikipedia 的相关部分。 右侧面板中显示的 Wikipedia 页面部分也称为信息框。
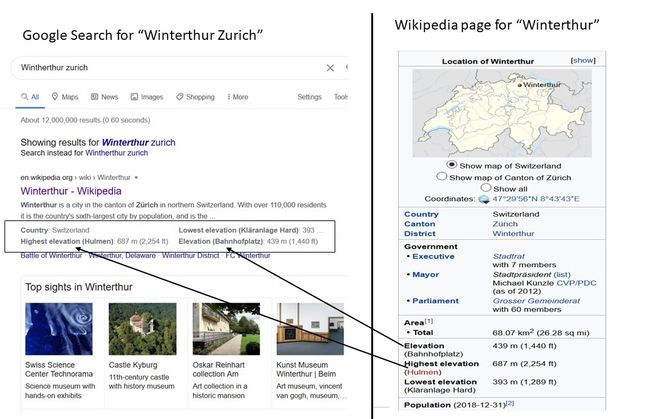
作为搜索结果的一部分,我们看到诸如 Winterthur 位于瑞士国家、海拔 430 米等事实。这些信息直接从 Winterthur 维基百科页面的信息框中提取。 Wikipedia Infoboxes 中的一些数据是通过查询名为 Wikidata 的 KG 填充的。正如我们接下来讨论的那样,来自 KG 的数据可以以比上例中更深入的方式增强网络搜索。
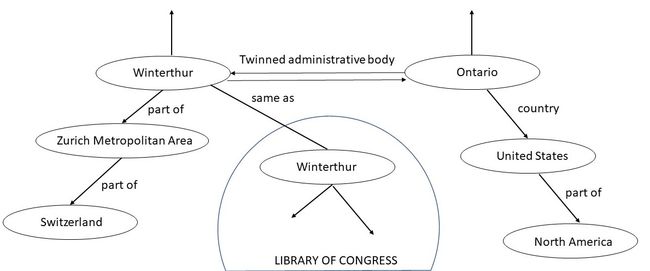
Winterthur的维基百科页面列出了它的孪生城镇:两个在瑞士,一个在捷克共和国,一个在奥地利。加利福尼亚州安大略市的维基百科页面标题为加利福尼亚州安大略省,将温特图尔列为其姐妹城市。姐妹城市和孪生城市的关系既相同又互惠。因此,如果一个城市 A 是另一个城市 B 的姐妹(双胞胎)城市,那么 B 必须是 A 的姐妹(双胞胎)城市。因为“姐妹城市”和“双城”是维基百科中的节标题,没有定义或两者之间指定的关系,很难检测到这种差异。相比之下,在温特图尔的 Wikidata 表示中,存在一种称为孪生行政机构的关系,其中列出了安大略市。由于这种关系在 KG 中被定义为对称关系,因此安大略市的 Wikidata 页面自动包含 Winterthur。维基数据通过其管理者的努力解决了识别等价关系的问题,并使用知识图谱作为存储和推理机制。如果 Wikidata KG 完全集成到 Wikipedia 中,此处考虑的示例中考虑的缺失链接的差异自然会消失。我们可以在图 3 中可视化 Winterthur 和 Ontario 之间的双向关系。图 3 中的 KG 还显示了 Winterthur 和 Ontario 连接到的其他对象。
Wikidata 包括来自多个独立提供者的数据,例如美国国会图书馆。通过使用 Winterthur 的 Wikidata 标识符,国会图书馆发布的信息可以很容易地与 Wikidata 中存在的有关 Winterthur 的其他信息链接。 Wikidata 通过在 Schema.Org 中发布其中使用的关系定义来轻松建立此类链接。
Schema.Org 中一个有据可查的关系列表,也称为关系词汇表,至少给了我们两个优点。首先,编写跨多个数据集的查询更容易,因为查询可以使用这些源共有的关系来构建。如果不使用跨多个来源的这种常见关系,我们将需要确定它们之间的语义关系并提供适当的翻译。跨多个来源的查询的一个示例是:在地图上显示在温特图尔死亡的人的出生城市?其次,搜索引擎可以使用此类查询从 KG 中检索信息并显示查询结果,如图 2 所示。使用搜索结果中返回的结构化信息现在已成为领先搜索引擎的标准功能。
最新版本的 Wikidata 拥有超过 9000 万个对象,这些对象之间的关系超过 10 亿个。 Wikidata 建立了由独立数据提供商以 414 种不同语言发布的超过 4872 个不同目录的连接。根据最近的估计,目前有 31% 的网站和超过 1200 万数据提供者正在使用 Schema.Org 的词汇表在其网页上发布注释。
Wikidata 知识图谱有什么特别新颖和令人兴奋的地方?首先,它是一个规模空前的图,并且是当今可用的最大的知识图之一。其次,即使 Wikidata 是手动管理的,管理成本也由贡献者社区分担。第三,维基数据中的一些数据可能来自自动提取的信息,但必须根据维基数据的编辑政策易于理解和验证。第四,明确努力通过 Schema.Org 中的词汇表提供不同关系名称的语义定义。最后,Wikidata 的主要驱动用例是改进网络搜索。尽管 Wikidata 有多个应用程序使用它进行分析和可视化,但它在网络上的使用仍然是最引人注目且易于理解的应用程序。
企业数据集成

许多金融机构有兴趣通过 360 度视图更好地管理他们的客户关系,即将客户的外部信息与同一客户的内部信息相结合的视图。例如,可以将来自金融新闻的公开信息、有关供应链关系的商业来源和策划数据与内部客户信息整合起来,以创建这样的 360 度视图。为了理解这样的视图如何有用,让我们考虑一个示例场景。财经新闻报道称,“Acma Retail Inc”因大流行而申请破产,因此其许多供应商将面临财务压力。这种压力可能会深入其供应链并引发其他客户的财务困难。例如,如果作为 Acma 供应商的公司 A 正面临财务压力,作为 A 供应商的公司也将经历类似的压力。这种供应链关系被整理为称为 Factset 的商用数据集的一部分。在 360 度视图中,来自 Factset 的数据和财经新闻与内部客户数据库集成。由此产生的 KG 准确地跟踪 Acma 供应链,识别具有不同收入风险的压力供应商,并识别其风险可能值得监控的公司。
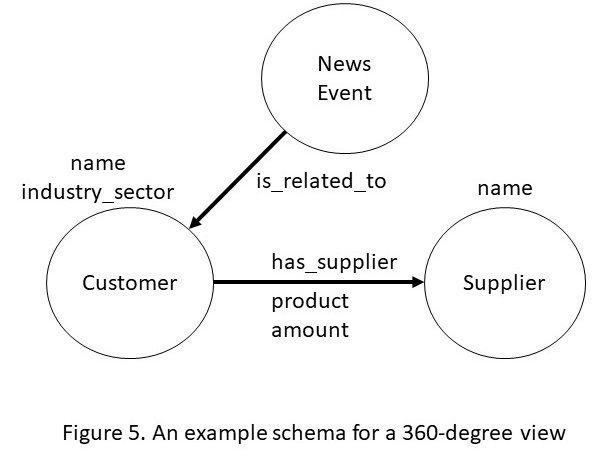
为了创建客户的 360 度视图,数据集成流程从业务分析师勾勒出他们有兴趣跟踪的关键实体、事件和关系的模式开始。 KG 模式的视觉特性使业务专家更容易参与并指定他们的要求。然后将来自各个来源的数据加载到知识图引擎中。三元组的存储格式允许我们只翻译那些与业务领域专家定义的模式直接相关的关系。其余数据仍然可以作为三元组加载,但不需要我们承担将它们与定义的模式相关联的前期成本。由于 KG 使用三元组的通用模式,因此在分析过程中更改需求更容易合并。最后,存储格式反映了领域专家定义的模式。
使用知识图谱进行数据集成有什么特别新颖和令人兴奋的地方?首先,三元组的通用模式大大降低了开始数据集成项目的成本。其次,适应基于三元组的模式以响应变化比适应传统关系数据库所需的类似努力要容易得多。第三,也是最后一点,现代 KG 引擎针对回答需要遍历数据中的图关系的问题进行了高度优化。对于图 5 的示例模式,图引擎已内置操作以识别供应链网络中的中央供应商、密切相关的客户或供应商群体以及不同供应商的影响范围。所有这些计算都利用了与域无关的图算法,例如中心性检测和社区检测。由于易于创建和可视化模式,以及内置的分析操作,KG 正在成为将数据转化为智能的流行解决方案。
人工智能中的知识图谱
AI agent维护现实世界的表示并将其用于推理。提出一个好的表示是人工智能的核心问题,因为它允许agent存储信息并从中得出新的结论。我们从快速回顾之前关于 AI 知识表示的工作开始本节,将 KGs 置于该上下文中,然后提供有关现代 AI 算法如何使用 KGs 存储其输出以及使用它们以整合领域知识的更多细节.
知识图谱,也称为人工智能上下文中的语义网络,自该领域早期以来一直被用作人工智能agent的世界知识存储,并已应用于计算机科学的所有领域。还有许多其他并行语义网络的方案,例如概念图、描述逻辑和规则语言。在某些情况下,概率图模型可以捕获不确定的知识。
源自语义网络的方法的一个广为人知的应用是捕获本体。本体是知识图谱中使用的关系的正式规范。例如,在图 3 中,City、Country 等概念和 part of、same as 等关系及其形式定义构成了一个本体。使用这个本体,我们可以推断出温特图尔位于瑞士。
为了让互联网更加智能,万维网联盟 (W3C) 标准化了一系列知识表示语言,这些语言现在被广泛用于在互联网上获取知识。这些语言包括资源描述框架 (RDF)、Web 本体语言 (OWL) 和语义 Web 规则语言 (SWRL)。
我们刚才回顾的关于人工智能中知识表示的先前工作是自上而下的方式驱动的,即我们首先开发一个世界模型,然后使用推理算法从中得出结论。目前,自下而上的人工智能方法的活动激增,即开发可以处理数据的算法,算法可以从中得出结论和见解。在本节的其余部分,我们将讨论 KG 在存储学习知识和为 AI 算法提供领域知识输入源方面所扮演的角色。
知识图谱作为机器学习的输出
尽管 Wikidata 在吸引志愿者策展人社区方面取得了成功,但手动创建知识图谱通常是昂贵的。 因此,我们非常需要我们可以实现的用于创建知识图的任何自动化。 直到几年前,自然语言处理 (NLP) 和计算机视觉 (CV) 算法都在努力在文本实体识别和图像对象检测方面做得很好。 由于最近的进展,这些算法开始超越基本的识别任务,以提取对象之间的关系,需要一种表示形式,提取的关系可以存储在其中以供进一步处理和推理。 我们现在将讨论通过 NLP 和 CV 技术实现的自动化如何促进知识图谱的创建。

从文本中提取实体和关系是 NLP 中的两个基本任务。执行实体和关系提取的方法包括基于规则的方法和机器学习。基于规则的方法利用句子的句法结构或指定如何在输入文本中识别实体或关系。机器学习方法利用序列标记算法或语言模型进行实体和关系提取。
从文本的多个部分提取的信息需要相互关联,而知识图谱提供了实现这一目标的自然媒介。例如,从图 6 所示的句子中,我们可以提取实体 Albert Einstein, Germany, Theoretical Physicist, and Theory of Relativity;以及出生、职业和发展的关系。一旦这个知识片段被整合到一个更大的 KG 中,我们可以使用逻辑推理来获得额外的链接(用虚线表示),例如理论物理学家是一种实践物理学的物理学家,而相对论是物理学的一个分支物理。
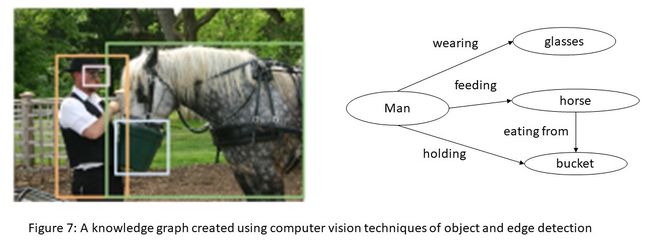
计算机视觉的圣杯是对图像的完整理解,即检测对象、描述它们的属性并识别它们的关系。理解图像将使重要的应用成为可能,例如图像搜索、问答和机器人交互。近年来,在实现这一目标方面取得了很大进展,包括图像分类和目标检测。计算机视觉算法大量使用机器学习方法,如分类、聚类、最近邻,以及深度学习方法,如递归神经网络。
从图 7 所示的图像中,图像理解系统应生成如右图所示的 KG。知识图谱中的节点是对象检测器的输出。目前计算机视觉的研究重点是开发能够正确推断对象之间关系的技术,例如,人拿着桶,马在桶里喂食等。右图是知识图谱的一个例子,它为视觉问答提供了基础。
知识图谱作为机器学习的输入
如果机器学习算法可以结合领域知识,它们可以表现得更好。 KGs 是用于捕获领域知识的有用数据结构,但机器学习算法要求任何符号或离散结构,例如图,都应首先转换为数字形式。 我们可以使用一种称为嵌入的技术将符号输入转换为数字形式。 为了说明这一点,我们将考虑词嵌入和图嵌入。
词嵌入最初是为计算词之间的相似性而开发的。 为了理解词嵌入,我们考虑以下一组句子。
I like knowledge graphs.
I like databases.
I enjoy running.
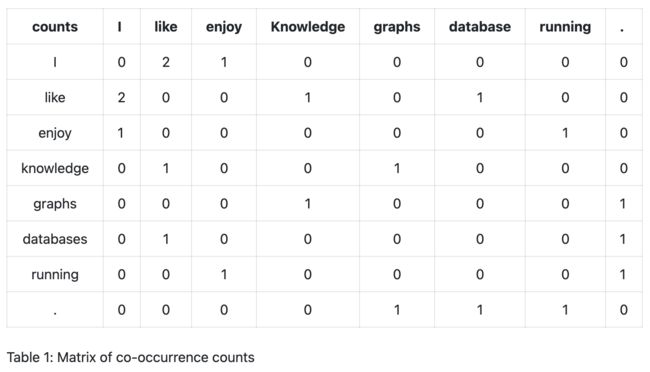
在上面的一组句子中,我们计算一个单词出现在另一个单词旁边的频率,并将计数记录在一个矩阵中。例如,单词 i 出现在 like 单词旁边两次,并且在单词 enjoy 旁边出现一次,因此,这两个单词的计数分别为 2 和 1,每隔一个单词计数为 0。我们可以按照表 1 所示的类似方式计算其他单词的计数。这样的矩阵通常称为单词共现计数。每个单词的含义由与该单词对应的行中的向量捕获。为了计算单词之间的相似度,我们计算它们对应的向量之间的相似度。在实践中,我们对可能包含数百万个单词的文本感兴趣,并且需要更紧凑的表示。由于共现矩阵是稀疏的,我们可以使用线性代数中的技术(例如奇异值分解)来减少它的维数。对应于一个词的结果向量称为它的词嵌入。今天使用的典型词嵌入依赖于长度为 200 的向量。
一个句子是一个单词序列,单词嵌入计算其中单词的共现。我们可以通过以下方式将这个想法推广到图的节点嵌入:(a)使用随机游走遍历图,给我们一条通过图的路径(b)通过图的重复遍历获得一组路径(c)计算这些路径上节点的共现,就像我们计算句子中单词的共现一样 (d) 共现计数矩阵中的每一行为我们提供与其对应的节点的向量 (e) 使用合适的维度减少技术以获得更小的向量,称为节点嵌入。
我们可以将整个图编码为一个向量,称为它的图嵌入。计算图嵌入的方法有很多,但最简单的方法可能是将表示图中每个节点的节点嵌入的向量相加,以获得表示整个图的向量。
我们使用词嵌入的例子作为解释图嵌入的先驱,主要用于教学目的。事实上,两者都有相似的目标:虽然词嵌入捕获了词的含义并帮助计算它们之间的相似性,但节点嵌入捕获了图中节点的含义并帮助计算它们之间的相似性。用于计算它们的方法之间也有很多相似之处。
词嵌入和图形嵌入是一种为机器学习算法提供符号输入的方法。词嵌入的一个常见应用是学习一种语言模型,该模型可以预测单词序列中接下来可能出现的单词。词嵌入的一个更高级的应用是将它们与 KG 一起使用——例如,只要知识图将不太频繁的词编码为它的下位词,就可以将更频繁的词的嵌入重新用于不太频繁的词。从友谊图计算的图嵌入的一个直接用途是推荐新朋友。图嵌入的更高级使用涉及链接预测,例如,在公司图中,我们可以使用链接预测来识别潜在的新客户。
总结
有向标记图是离散数学中的基本结构,在计算机科学的所有领域都有应用。在人工智能和数据库中,有向标记图最显着的用途是数据图、分类法和本体。传统上,此类应用程序很小,并且是通过自上而下的设计和人工知识工程创建的。
现代知识图谱与经典知识图谱的区别在于:规模化、自下而上的开发和多种构建模式。 AI 中的早期语义网络从未达到我们今天看到的知识图谱的规模和规模。难以为数据集成提出自上而下的模式设计以及机器学习的数据驱动性质,迫使采用自下而上的方法来创建知识图谱。最后,为了创建现代知识图谱,我们正在通过显着的自动化和众包来补充手动知识工程技术。
上述趋势的融合为经典知识图谱的理论和算法确立了新的重要性。即使我们以自下而上的方式创建知识图谱,其模式的设计和语义定义仍然很重要。虽然自动化可能会加快创建知识图谱的某些步骤,但手动验证和人工监督仍然必不可少。这种协同作用为联合利用经典知识图谱技术和机器学习、众包和可扩展计算的现代工具建立了一个令人兴奋的未知领域。
参考资源
[1] An Introduction to Knowledge Graphs