(二)mmclassification图像分类——简单测试
(二)mmclassification图像分类——单张图像测试
- 引言
- 单张图像的测试结果
-
- 方法一:把配置写在py文件里
- 方法二:使用命令行指定配置参数
- 训练结果
- mmclassification简介
-
-
- configs里的__base__文件夹下的models
- configs里的__base__文件夹下的datasets
- configs里的__base__文件夹下的schedules
- 训练工具
-
引言
把实用的代码部分放前面了,后面简介里是比较重要的理论内容,看了更好理解mmclassification的运作。
放一个mmclassification官网的操作手册:链接: MMClassification’s documentation.
单张图像的测试结果
- 选择一个要用的网络,比如configs/mobilenet_v2
- 下载预训练的模型,网址链接: https://github.com/open-mmlab/mmclassification/blob/master/docs/model_zoo.md
- 在mmclassification文件夹进行如下配置
mkdir checkpoints
cd checkpoints
wget https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth
cd ../
方法一:把配置写在py文件里
新建一个py文件
cd demo
touch demo2.py
vi demo2.py
内容如下:
# demo2.py
from mmcls.apis import inference_model, init_model, show_result_pyplot
# 指定配置文件
config_file = 'configs/mobilenet_v2/mobilenet_v2_b32x8_imagenet.py'
# 指定checkpoint文件
checkpoint_file = 'checkpoints/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth'
# 指定GPU
device = 'cuda:0'
# 根据配置文件和模型文件搭建模型
model = init_model(config_file, checkpoint_file, device=device)
# 测试一张图片,要确保这个路径下有这张图
img = 'demo/demo.JPEG'
result = inference_model(model,img)
# 展示结果,如果是远程ssh的话,下面这句注释掉,因为显示不了
show_result_pyplot(model,img,result)
然后将路径设置在mmclassification下,运行:
cd ../
python demo/demo2.py
方法二:使用命令行指定配置参数
可以像上图那样写一个py文件,也可以直接用demo/image_demo.py
from argparse import ArgumentParser
from mmcls.apis import inference_model, init_model, show_result_pyplot
def main():
parser = ArgumentParser()
parser.add_argument('img', help='Image file')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
args = parser.parse_args()
# build the model from a config file and a checkpoint file
model = init_model(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_model(model, args.img)
print(result)
# show the results
show_result_pyplot(model, args.img, result)
if __name__ == '__main__':
main()
运行的时候按照这个格式:
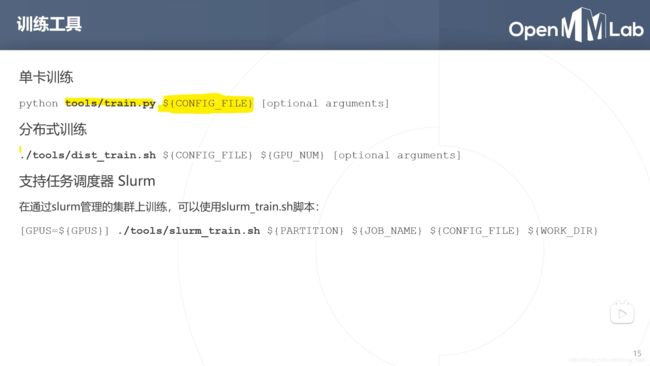
python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE}
在这里是:
python demo/image_demo.py demo.JPEG configs/mobilenet_v2/mobilenet_v2_b32x8_imagenet.py checkpoints/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth
训练结果

mmclassification简介

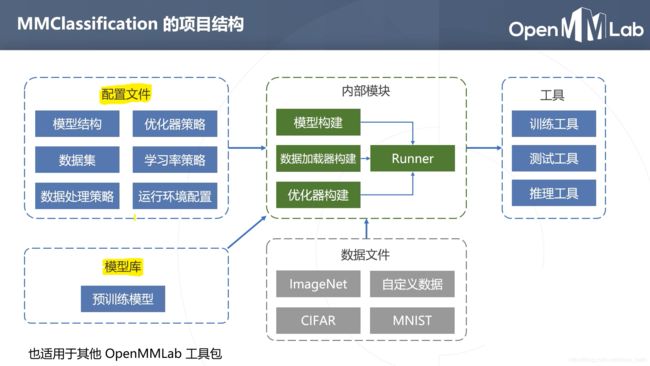
mmclassification文件夹下面有个mmcls子文件夹,里面有个models文件夹,放着backbones、necks、heads,对应网络地骨干网络、颈部和分类头。
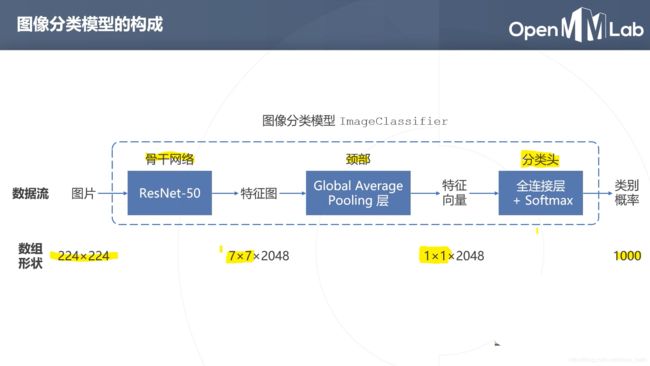

configs里的__base__文件夹下的models
这里的works_per_gpu表示单个gpu上同时进行多少个works,只有一个gpu的时候,改成0。
samples_per_gpu相当于batch_size。

configs里的__base__文件夹下的datasets
这一块是数据增强:

configs里的__base__文件夹下的schedules
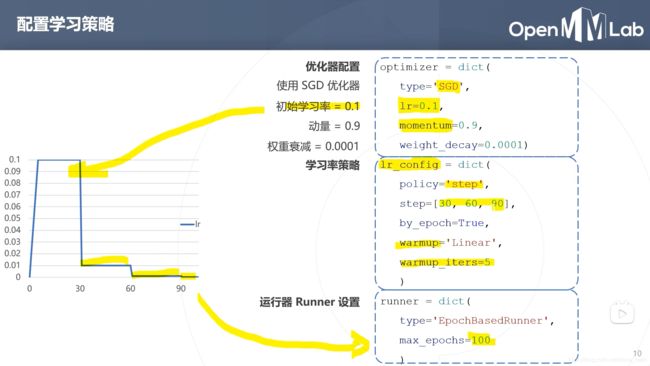
训练工具