如何去除数据库中重复的数据
去除数据库中重复的数据
- 准备工作
- 方法一:用distinct 联合去重
- 方法二:使用窗口函数限制row_number()=1
- 方法三:使用窗口函数删除row_number()>1
- 方法四:group by去重
准备工作
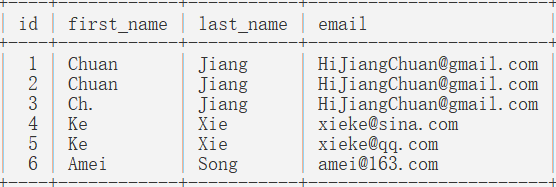
原始表users:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users (first_name,last_name,email)
VALUES ('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Ch. ','Jiang','HiJiangChuan@gmail.com'),
('Ke','Xie','xieke@sina.com'),
('Ke','Xie','xieke@qq.com'),
('Amei','Song','amei@163.com');
默认id为自增主键;
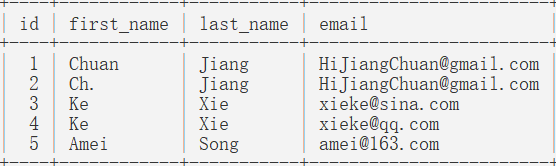
方法一:用distinct 联合去重
第一步:distinct后面加多个字段,即多个字段联合起来去重,就能只筛选出一条数据!
select distinct first_name,last_name,email from users;
第二步:新建一个表tmp,将以上数据导入即可;
CREATE TABLE tmp (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users_copy (first_name,last_name,email)
SELECT DISTINCT first_name,last_name,email FROM users;
注意:此处使用insert into …select导入,但是指定了后三个字段,并不包括自增的主键;
方法二:使用窗口函数限制row_number()=1
思路:
重复即first_name, last_name,email 三个字段都相等,则对这个三个字段开窗,也就是重复的数据会在一个窗口,
使用row_number对重复的数据排序,最后用子查询限制row_number只为1,即对重复的数据之筛选出来一条;
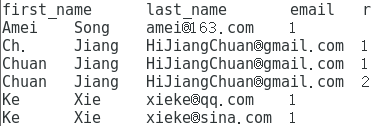
第一步:对重复数据开窗,使用row_number()函数
select first_name,last_name,email,
row_number()over(partition by first_name,last_name,email) r from users;
第二步:限制row_number为1即可;
SELECT first_name,last_name,email from
(SELECT first_name,last_name,email,
row_number()over(partition by first_name,last_name,email) r from users)as q
where r=1;

方法三:使用窗口函数删除row_number()>1
直接在原表上删除数据,条件是对字段联合开窗后,row_number>1 即重复的数据;
DELETE FROM users
WHERE id IN (
SELECT id
FROM (
SELECT
id, ROW_NUMBER () Over (PARTITION BY first_name,last_name,email ORDER BY id) as r
from users
) q
WHERE r > 1
);
结果:

方法四:group by去重
即对重复的字段联合分组即可,自然就只过滤出一条数据了!
然后将结果导入临时表;
INSERT INTO tmp (first_name,last_name,email)
SELECT first_name,last_name,email from users group by first_name,last_name,email;