Swift学习笔记 (七) 字符串和字符(下)
访问和修改字符串
你可以通过字符串的属性和方法来访问和修改它,当然也可以用下标语法完成。
字符串索引
每一个 String 值都有一个关联的索引(index)类型, String.Index ,它对应着字符串中的每一个 Character的位置。
前⾯提到,不同的字符可能会占用不同数量的内存空间,所以要知道 Character 的确定位置,就必须从 String 开头遍历每一个
Unicode 标量直到结尾。因此,Swift 的字符串不能用整数(integer)做索引。
使⽤ startIndex 属性可以获取一个 String 的第一个 Character 的索引。使用 endIndex 属性可以获取最后 一个 Character 的后
⼀个位置的索引。因此, endIndex 属性不能作为一个字符串的有效下标。如果 String 是空串, startIndex 和 endIndex 是相
等的。
通过调用 String 的 index(before:) 或 index(after:) ⽅法,可以立即得到前面或后面的一个索引。你还可以通过调用 index(_:offsetBy:) ⽅法来获取对应偏移量的索引,这种⽅式可以避免多次调用 index(before:) 或 index(after:) ⽅法。
你可以使用下标语法来访问 String 特定索引的 Character 。
let greeting = "Guten Tag!"
greeting[greeting.startIndex] // G
greeting[greeting.index(before: greeting.endIndex)] // !
greeting[greeting.index(after: greeting.startIndex)] // u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index] // a
试图获取越界索引对应的 Character ,将引发⼀一个运⾏行行时错误。
greeting[greeting.endIndex] // error
greeting.index(after: endIndex) // error
使用 indices 属性会创建一个包含全部索引的范围( Range ),⽤来在一个字符串中访问单个字符。
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// 打印输出“G u t e n T a g ! ”
注意
你可以使用 startIndex 和 endIndex 属性或者 index(before:) 、 index(after:) 和 index(_:offsetBy:) ⽅法在任意一个确认的并
遵循 Collection 协议的类型里面,如上文所示是使用在 String 中,你也可以使用在Array 、 Dictionary 和 Set 中。
插⼊和删除
调⽤ insert(_:at:) ⽅法可以在一个字符串的指定索引插⼊一个字符,调用 insert(contentsOf:at:) ⽅法可以在一个字符串的指定
索引插⼊一个段字符串。
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex) // welcome 变量现在等于 "hello!"
welcome.insert(contentsOf:" there", at: welcome.index(before: welcome.endIndex))
// welcome 变量现在等于 "hello there!"
调⽤ remove(at:) ⽅法可以在一个字符串的指定索引删除一个字符,调⽤ removeSubrange(_:) ⽅法可以在一个字符串的指定索
引删除⼀个子字符串。
welcome.remove(at: welcome.index(before: welcome.endIndex)) // welcome 现在等于 "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..
// welcome 现在等于 "hello"
注意
你可以使用 insert(_:at:) 、 insert(contentsOf:at:) 、 remove(at:) 和 removeSubrange(_:) 方法在任意一个确认的并遵循
RangeReplaceableCollection 协议的类型里面,如上文所示是使用在 String 中,你也可以使⽤在Array 、 Dictionary 和 Set
中。
⼦字符串
当你从字符串中获取一个子字符串 —— 例如,使用下标或者 prefix(_:) 之类的⽅法 —— 就可以得到⼀个SubString 的实例,而
⾮另外一个 String 。Swift ⾥的 SubString 绝大部分函数都跟 String 一样,意味着你可以使⽤同样的⽅式去操作 SubString 和
String 。然而,跟 String 不同的是,你只有在短时间内需要操作字符串时,才会使用 SubString 。当你需要⻓时间保存结果
时,就把 SubString 转化为 String 的实例:
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..
// beginning 的值为 "Hello"
或 let beginning:String.SubSequence
beginning = greeting.prefix(5)
// 把结果转化为 String 以便长期存储。
let newString = String(beginning)
就像 String ,每一个 SubString 都会在内存⾥保存字符集。⽽ String 和 SubString 的区别在于性能优化上, SubString 可以
重⽤用原 String 的内存空间,或者另一个 SubString 的内存空间( String 也有同样的优化,但如果两个 String 共享内存的话,
它们就会相等)。这一优化意味着你在修改 String 和 SubString 之前都不需要消耗性能去复制内存。就像前面说的那样,
SubString 不适合长期存储 —— 因为它重用了原 String 的内存空间,原 String 的内存空间必须保留直到它的 SubString 不再被
使用为止。
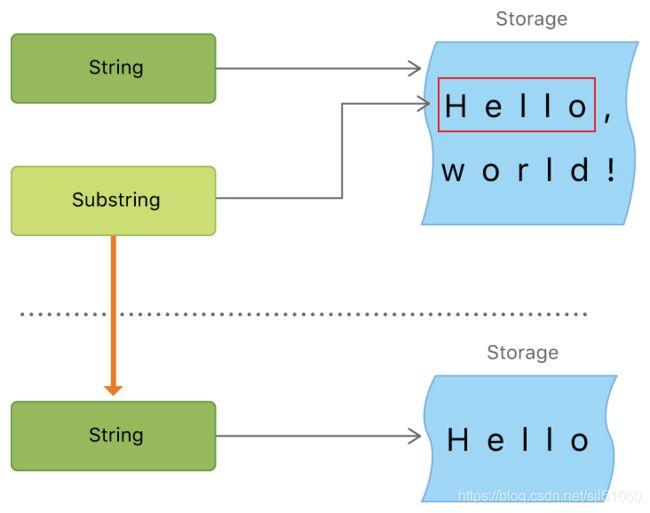
上面的例子, greeting 是一个 String ,意味着它在内存里有一⽚空间保存字符集。而由于 beginning 是greeting 的 SubString
,它重用了 greeting 的内存空间。相反, newString 是一个 String —— 它是使用 SubString 创建的,拥有一⽚⾃己的内存空
间。下⾯的图展示了他们之间的关系:
注意
String 和 SubString 都遵循 StringProtocol 协议,这意味着操作字符串的函数使用 StringProtocol 会更加⽅便。你可以传⼊
String 或 SubString 去调用函数。
⽐较字符串
Swift 提供了三种方式来比较文本值:字符串字符相等、前缀相等和后缀相等。
字符串/字符相等
字符串/字符可以用等于操作符( == )和不等于操作符( != ):
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// 打印输出“These two strings are considered equal”
如果两个字符串(或者两个字符)的可扩展的字形群集是标准相等,那就认为它们是相等的。只要可扩展的字形群集有同样的语言
意义和外观则认为它们标准相等,即使它们是由不同的 Unicode 标量构成。
例如, LATIN SMALL LETTER E WITH ACUTE ( U+00E9 )就是标准相等于 LATIN SMALL LETTER E ( U+0065 )后面加 上
COMBINING ACUTE ACCENT ( U+0301 )。这两个字符群集都是表示字符 é 的有效方式,所以它们被认为是标准相等的:
// "Voulez-vous un café?" 使⽤ LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" 使用 LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// 打印输出“These two strings are considered equal”
相反,英语中的 LATIN CAPITAL LETTER A ( U+0041 ,或者 A )不等于俄语中的 CYRILLIC CAPITAL LETTER A ( U+0410 ,或者
A )。两个字符看着是一样的,但却有不同的语言意义:
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent")
}
// 打印“These two characters are not equivalent”
注意
在 Swift 中,字符串和字符并不区分地域(not locale-sensitive)。
前缀/后缀相等
通过调用字符串的 hasPrefix(_:) / hasSuffix(_:) 方法来检查字符串是否拥有特定前缀/后缀,两个方法均接收⼀个 String 类型的
参数,并返回一个布尔值。
下⾯的例子以一个字符串数组表示莎士比亚话剧《罗密欧与朱丽叶》中前两场的场景位置:
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
你可以调用 hasPrefix(_:) ⽅法来计算话剧中第一幕的场景数:
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// 打印输出“There are 5 scenes in Act 1”
相似地,你可以用 hasSuffix(_:) 方法来计算发生在不同地⽅的场景数:
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// 打印输出“6 mansion scenes; 2 cell scenes”
注意
hasPrefix(_:) 和 hasSuffix(_:) 方法都是在每个字符串中逐字符比较其可扩展的字符群集是否标准相等,详细描述在
字符串/字符相等。
字符串的 Unicode 表示形式
当⼀个 Unicode 字符串被写进⽂本文件或者其他储存时,字符串中的 Unicode 标量会用 Unicode 定义的几种编码格式
(encoding forms)编码。每一个字符串中的小块编码都被称代码单元 (code units)。这些包括 UTF-8 编码格式 (编码字符串为 8
位的代码单元), UTF-16 编码格式(编码字符串位 16 位的代码单元),以及 UTF-32 编码格式(编码字符串32位的代码单元)。
Swift 提供了几种不同的⽅式来访问字符串的 Unicode 表示形式。你可以利用 for-in 来对字符串进行遍历,从而以 Unicode 可
扩展的字符群集的方式访问每一个 Character 值。
另外,能够以其他三种 Unicode 兼容的方式访问字符串的值:
UTF-8 代码单元集合(利用字符串的 utf8 属性进⾏访问)
UTF-16 代码单元集合(利用字符串的 utf16 属性进⾏访问)
21 位的 Unicode 标量值集合,也就是字符串的 UTF-32 编码格式(利用字符串的 unicodeScalars 属性进行访问)
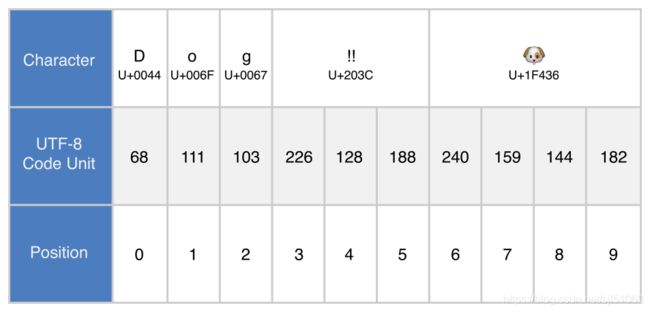
下面由 D , o , g , !! ( DOUBLE EXCLAMATION MARK , Unicode 标量 U+203C )和 ?( DOG FACE ,Unicode 标量 为 U+1F436 )
组成的字符串中的每一个字符代表着一种不同的表示:
let dogString = "Dog!!?"
UTF-8 表示
你可以通过遍历 String 的 utf8 属性来访问它的 UTF-8 表示。其为 String.UTF8View 类型的属性, UTF8View 是无符号 8 位(
UInt8 )值的集合,每一个 UInt8 值都是一个字符的 UTF-8 表示:
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: " ")
}
// 68 111 103 226 128 188 240 159 144 182
上⾯的例子中,前三个 10 进制 codeUnit 值( 68 、 111 、 103 )代表了字符 D 、 o 和 g ,它们的 UTF-8 表示与 ASCII 表示相同。
接下来的三个 10 进制 codeUnit 值( 226 、 128 、 188 )是 DOUBLE EXCLAMATION MARK 的3字节 UTF-8 表示。最后的四个
codeUnit 值( 240 、 159 、 144 、 182 )是 DOG FACE 的4字节 UTF-8 表示。
UTF-16 表示
你可以通过遍历 String 的 utf16 属性来访问它的 UTF-16 表示。其为 String.UTF16View 类型的属性, UTF16View 是无符号16
位( UInt16 )值的集合,每一个 UInt16 都是一个字符的 UTF-16 表示:

for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: " ")
}
// 68 111 103 8252 55357 56374
同样,前三个 codeUnit 值( 68 、 111 、 103 )代表了了字符 D 、 o 和 g ,它们的 UTF-16 代码单元和 UTF-8 完全相同(因为这些
Unicode 标量量表示 ASCII 字符)。
第四个 codeUnit 值( 8252 )是一个等于十六进制 203C 的的十进制值。这个代表了了 DOUBLE EXCLAMATION MARK 字符的
Unicode 标量量值 U+203C 。这个字符在 UTF-16 中可以⽤用一个代码单元表示。
第五和第六个 codeUnit 值( 55357 和 56374 )是 DOG FACE 字符的 UTF-16 表示。第一个值为 U+D83D (⼗进制值为 55357 ),
第二个值为 U+DC36 (十进制值为 56374 )。
Unicode 标量表示
你可以通过遍历 String 值的 unicodeScalars 属性来访问它的 Unicode 标量表示。其为 UnicodeScalarView类型的属性,
UnicodeScalarView 是 UnicodeScalar 类型的值的集合。
每一个 UnicodeScalar 拥有一个 value 属性,可以返回对应的 21 位数值,用 UInt32 来表示:

for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: " ")
}
// 68 111 103 8252 128054
前三个 UnicodeScalar 值( 68 、 111 、 103 )的 value 属性仍然代表字符 D 、 o 和 g 。
第四个 codeUnit 值( 8252 )仍然是一个等于十六进制 203C 的十进制值。这个代表了 DOUBLE EXCLAMATION MARK 字符的
Unicode 标量 U+203C 。
第五个 UnicodeScalar 值的 value 属性, 128054 ,是一个十六进制 1F436 的十进制表示。其等同于 DOG FACE 的 Unicode 标
量 U+1F436 。
作为查询它们的 value 属性的一种替代方法,每个 UnicodeScalar 值也可以用来构建一个新的 String 值,⽐如在字符串插值中使⽤:
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// !!
// ?