【论文阅读】Multi-Modal Sarcasm Detection Based on Contrastive Attention Mechanism
论文标题:Multi-Modal Sarcasm Detection Based on Contrastive Attention Mechanism
来源:NLPCC 2021
论文链接:https://arxiv.org/abs/2109.15153
动机
随着视频通信的普及,多模态场景分析受到了广泛关注。在目前的多模态反讽识别中,存在着一个关键的问题:如何对话语中存在的模态间的不一致性进行建模(例如,文本表达的是赞美,而声学音调表示的是抱怨)。而对于这个问题并没有人进行过深入研究。
因此,作者提出来了一个基于对比注意机制的反讽检测模型(ConAttSD),该模型利用对比注意机制来提取多模态反讽检测的模态间的不一致性。
Contributions
- 设计了一个基于对比注意的反讽检测(ConAttSD)模型来检测视频会话中的讽刺。
- 提出一种模态间对比注意机制来提取对比特征,以表示模态间的不一致性
- 使用GRU和Transformers 来对对话中的顺序语境和说话人进行建模。
Methods
作者提出的ConAttSD模型,可分为三个部分顺序上下文编码器、基于对比注意的编码器和线性解码器。
其中顺序上下文编码器动态捕获随对话传输的模态内影响,基于对比注意的编码器提取会话中模态之间的不一致信息, 然后通过情态间对比注意机制,线性解码器将讽刺标签分配给话语 ,标签格式为(1: sarcasm; 0: no sarcasm)
,标签格式为(1: sarcasm; 0: no sarcasm)
模型结构图如下所示:

下面先介绍模态特征提取采用的方法,然后再分别详细地介绍顺序上下文编码器、基于对比注意的编码器、线性解码器。
模态特征提取
文本模态提取:使用预训练模型BERT提取一个768维的文本特征向量。
音频特征提取:使用Librosa库提取包括MFCC等在内的声学特征,然后取平均值得到一个298维的音频特征向量。
视觉特征提取:使用预训练的ResNet-152提取视频帧的视觉特征,对所有帧的视觉特征取平均值得到一个2048维的视觉特征向量。
Sequential Context Encoder
在顺序上下文编码器中有两个子编码器:基于GRU的编码器和基于Transformers的编码器。其中基于GRU的编码器使用GRU来提取顺序上下文信息,基于Transformers的编码器则用于输出GRU的信息。
在基于GRU的编码器中,对于话语,为了更好的提取话语的顺序上下文信息,作者定义全局状态![]() 和说话人状态
和说话人状态![]() ,而且通过下面的公式对全局状态和说话人状态进行迭代更新。
,而且通过下面的公式对全局状态和说话人状态进行迭代更新。

其中,![]() 是使用双重影响网络的第i个话语的上下文表示,包括模态内和模态间信息。
是使用双重影响网络的第i个话语的上下文表示,包括模态内和模态间信息。
在基于Transformers的编码器中,用Transformer提取了更有效的顺序上下文信息,在捕获上下文信息依赖方面表现出了比RNN模型优越的性能。Transformer由B个相同块的堆栈组成,每个块有两个子层(包括一个多头自注意力机制和一个多层感知器),具有残差连接,在本文中,作者使用一个Transformer来捕获全局状态![]() (∈{,a,})内的依赖关系,并为语句输出一个顺序上下文向量
(∈{,a,})内的依赖关系,并为语句输出一个顺序上下文向量![]() 。
。
Contrastive-attention-based Encoder
为了提取用于讽刺检测的多个模态之间的不一致信息,作者提出了一种模态间对比注意机制,该机制将对比注意机制应用于从顺序上下文编码器输出的三个顺序上下文向量。
在基于对比注意的编码器中,作者将文本模态作为锚定模态,生成两个定向双模态变体(T->V和T->A)作为两个模态间对比注意力的输入,然后通过公式(5)(6)学习对比注意力权重,再通过公式(7) 生成两个模态间对比向量,其中一个模态间对比向量表示其相应输入双模态变量中的不一致性。

式子Q、K、V分别表示queries, keys 和values。
因此,通过两个模态之间的对比注意,文本可以分别与来自音频和视觉的信息进行有效对比。
Linear Decoder
线性解码器负责将来自顺序上下文编码器的三个顺序上下文向量和来自基于对比注意编码器的两个模态间对比向量连接成最终向量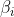 ,然后通过softmax分类器得到话语的讽刺标签。
,然后通过softmax分类器得到话语的讽刺标签。
![]()
实验结果
作者使用MUStARD数据集进行多模态反讽检测实验,在MUStARD数据集上可以进行说话人相关和说话人无关两个场景的实验。但是为了更好的检测模型的性能,作者使用了与说话人无关的设置来研究反讽检测。
基线:Two-attention-based encoder和GRU-based encoder
我们可以看到ConAttSD显著优于其他两个基线,与GRU-based encoder相比取得的优势,表明基于Transformers的编码器和基于对比注意的编码器可以有效地提取顺序上下文信息和模态间不一致信息。

在作者对单模态、双模态和三模态进行的对比实验中,我们可以看到多模态相对于单模态还是存在很大优势的。
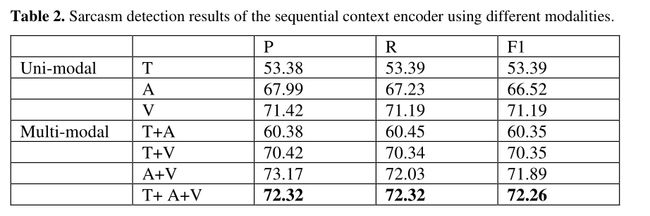
另外,作者也评估了基于对比注意的编码器与所有可能的输入,T->V+T->A也是取得了最好的性能。

总结
本文针对多模态讽刺检测提出来一种新的模型Contrastive-Attention-based Sarcasm Detection(ConAttSD),在模型中使用的两个编码器既能够提取上下文信息,也能提取模态间的不一致性信息。而且对比注意机制也是第一次运用到多模态讽刺检测领域,我们看到了ConAttSD模型通过多模态对比注意机制捕捉多模态不一致信息的能力,而且也能运用到未来的多模态会话情感识别中。