【RL】6.Actor-Critic
RL-Ch6-Actor-Critic
A2C:Advantage Actor-Critic
A3C:Asynchronous Actor-Critic
Advantage Function
我们在第四章Policy Gradient中从原始的梯度计算公式,引入baseline和时间步衰减的技巧后,得到Advantage Function,形式如下:
A θ ( s t , a t ) = ∑ t ′ = t T n γ t ′ − t r t ′ n − b A^{\theta}(s_t,a_t)=\sum_{t'=t}^{T_n}\gamma^{t'-t}r_{t'}^n-b Aθ(st,at)=t′=t∑Tnγt′−trt′n−b
令
G t n = ∑ t ′ = t T n γ t ′ − t r t ′ n G_t^n=\sum_{t'=t}^{T_n}\gamma^{t'-t}r_{t'}^n Gtn=t′=t∑Tnγt′−trt′n
则对 G t n G_t^n Gtn的估计可以用如下式子
G t n < − − E [ G t n ] = Q π ( s t , a t ) G_t^n<--E[G_t^n]=Q^\pi(s_t,a_t) Gtn<−−E[Gtn]=Qπ(st,at)
而 b = V π ( s t n ) b=V^\pi(s_t^n) b=Vπ(stn),所以Advantage Function的新形式为
A θ ( s t , a t ) = Q π ( s t , a t ) − V π ( s t n ) A^{\theta}(s_t,a_t)=Q^\pi(s_t,a_t)-V^\pi(s_t^n) Aθ(st,at)=Qπ(st,at)−Vπ(stn)
需要估计两个Network,但我们可以采用只估计一个Network的方法。
由于
Q π ( s t , a t ) = E [ r t n + V π ( s t + 1 n ) ] Q^\pi(s_t,a_t)=E[r_t^n+V^\pi(s_{t+1}^n)] Qπ(st,at)=E[rtn+Vπ(st+1n)]
不考虑随机性,去掉期望号,则有
Q π ( s t , a t ) = r t n + V π ( s t + 1 n ) Q^\pi(s_t,a_t)=r_t^n+V^\pi(s_{t+1}^n) Qπ(st,at)=rtn+Vπ(st+1n)
最终Advantage Function的形式为
A θ ( s t , a t ) = r t n + V π ( s t + 1 n ) − V π ( s t n ) A^{\theta}(s_t,a_t)=r_t^n+V^\pi(s_{t+1}^n)-V^\pi(s_t^n) Aθ(st,at)=rtn+Vπ(st+1n)−Vπ(stn)
估计 r t n r_t^n rtn的方差比 G t n G_t^n Gtn的小,因为只需要估计一个状态s。
Advantage Actor-Critic
概念
A2C相比Q-Learning,把基于Q值变为基于V值为导向,而且策略更新的方法引入了Policy Gradient的方法。

技巧
- actor π ( s ) \pi(s) π(s)与critic V π ( s ) V^\pi(s) Vπ(s)的一些参数可以共享。

- 探索很重要,如果交叉熵更大,则 π ( s ) \pi(s) π(s)的分布更均匀。
Asynchronous Advantage Actor-Critic
Asynchronous
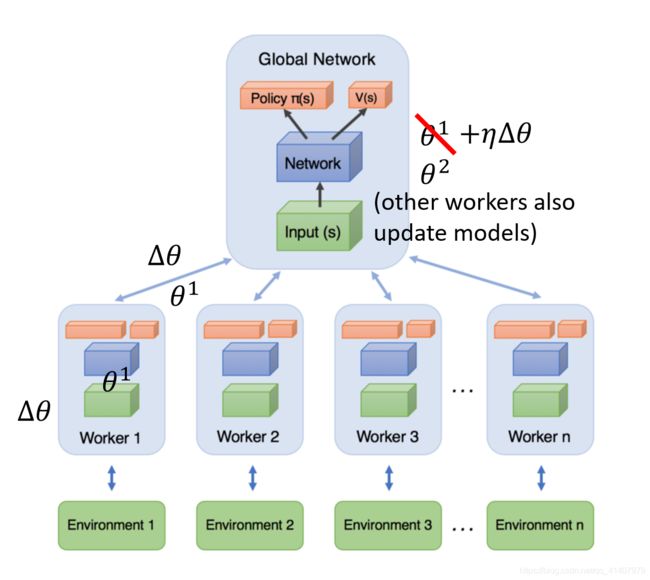
基本想法是开多个worker,进行经验的集成。具体实现步骤为:
- 每个worker从云端下载全局参数到本地端
- 每个worker分别在本地端采样
- 每个worker在本地端计算梯度
- 将梯度上传云端更新全局参数
不是同步更新,而是一个worker计算完就上传更新全局参数,像一个自助售卖机一样,谁有需求就去买饮料,交易一次云端就处理一次。
Pathwise Derivative Policy Gradient
PDPG是解决Q-Learning无法解决连续动作空间问题的一个方法,同时也是一个特别的Actor-Critic方法:原始的AC是只告知什么是不好的,而改进后的AC会告知什么是不好的,还会指导下一步应该怎么做。
此时动作a是一个连续的数值,要解决 a = a r g max a Q ( s , a ) a=arg\max_a Q(s,a) a=argmaxaQ(s,a),这个问题的解决要看Actor π \pi π。问题的求解流程图如下:
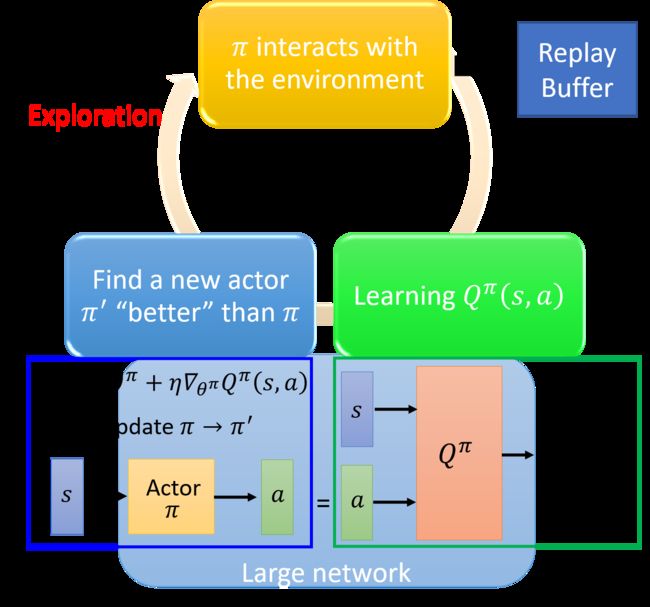
我们在第五章提到过Q-Learning算法,而不同点就在于如下五点:
•Initialize Q-function Q, target Q-function Q ^ = Q \hat{Q}=Q Q^=Q, actor π \pi π, target actor π ^ = π \hat{\pi}=\pi π^=π
•In each episode
•For each time step t
•Given state s t s_t st, take action a t a_t at based on
Qπ \pi π(epsilon greedyexploration) •Obtain reward r t , r_t, rt, and reach new state s t + 1 s_{t+1} st+1
•Store ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) into buffer
•Sample ( s i , a i , r i , s i + 1 ) (s_i, a_i, r_i, s_{i+1}) (si,ai,ri,si+1) from buffer (usually a batch)
•Target y = r i + y=r_i+ y=ri+
\max_a[\hat{Q}(s_{i+1},a)]Q ( s t + 1 , π ^ ( s t + 1 ) ) Q(s_{t+1},\hat{\pi}(s_{t+1})) Q(st+1,π^(st+1)) •Update the parameters of Q to make Q ( s i , a i ) Q(s_i , a_i ) Q(si,ai) close to y (regression)
•Update the parameters of π \pi π to maximize Q ( s i , π ( s i ) ) Q(s_i , \pi(s_i) ) Q(si,π(si))
•Every C steps reset Q ^ = Q \hat{Q}=Q Q^=Q
•Every C steps reset π ^ = π \hat{\pi}=\pi π^=π
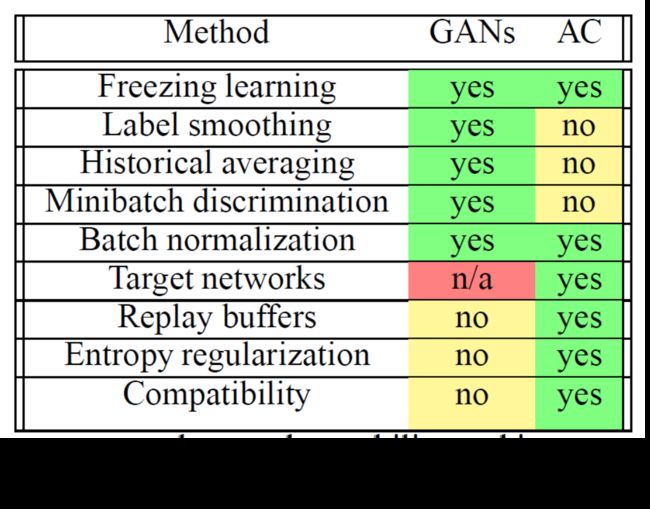
AC vs. GAN