深入浅出pytorch
目录
1、pytorch模型定义方法
1.1 nn.Sequential()
1.2 nn.ModuleList()
2、U-Net分割网络实现实现
3、模型修改
4、模型保存
1、pytorch模型定义方法
基于nn.Module,我们可以通过Sequential,ModuleList和ModuleDict三种方式定义pytorch模型
1.1 nn.Sequential()
它可以接收一个子模块的有序字典(DrderedDict)或者一系列子模块作为参数逐一添加Module的实例
第一种方式接受一系列子模块
#Sequential定义模型第一种方式
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,10),
)
print(net)第二种方式 接收一个子模块的有序字典OrderedDict
#Sequential定义模型第二种方式,不用forward,因为模型已经按照顺序定义好了
import torch.nn as nn
import collections
net = nn.Sequential(collections.OrderedDict([
('FC1',nn.Linear(784,256)),
('Relu1',nn.ReLU()),
('FC2',nn.Linear(256,10)),
]))
print(net)注意: nn.Sequential()定义的模型不需要写forward,因为顺序已经定义好了。
1.2 nn.ModuleList()
ModuleList()接收一个子模块或者层的列表作为输入,同时拥有List中的append(在列表末尾添加新的对象,保持原结构类型)和extend(在列表末尾一次性追加另一个序列多个值)操作
#Modulelist方法
import torch.nn as nn
net2 = nn.ModuleList([nn.Linear(784,256),nn.ReLU()])
net2.append(nn.Linear(256,10))
print(net2[-1])
print(net2)#Modulelist方法
import torch.nn as nn
net2 = nn.ModuleList([nn.Linear(784,256),nn.ReLU()])
net2.extend([nn.Linear(256,10)])
print(net2[-1])
print(net2)进行对比,直接将append换成extend会报错,但是里面加上列表[]符号就会将层添加进去???
extend()向列表尾部追加一个列表,对象必须是一个可以迭代的序列,将列表中的每个元素都追加进来,会在已存在的列表中添加新的列表内容
自己浅显理解:按照上面必须是一个迭代对象,不加[]时将不被entend视作可迭代对象,[]后list作为一个可迭代对象被添加到旧列表末尾。有其他理解或者错误请指出,后去在进行更新。
1.3 三种方法的比较与适应场景
Sequential()适用于快速验证结果,已经明确需要哪些层,直接写,不需要同时写__init__和forwrad;
ModuleList和ModuleDict在某个完全相同层需要重复多次。非常方便实现,可以’一行顶多行‘
例如下面定义多个重复的层
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.linears = nn.ModuleList([nn.Linear(10,20),nn.Linear(20,30),nn.Linear(5,10)])
def forward(self,x):
x = linears[2](x)
x = linears[0](x)
x = linears[1](x)
model = Net()
print(model)2、U-Net分割网络实现实现
当模型非常大时,使用sequential定义模型需要添加很多代码,可以说是非常不方便了
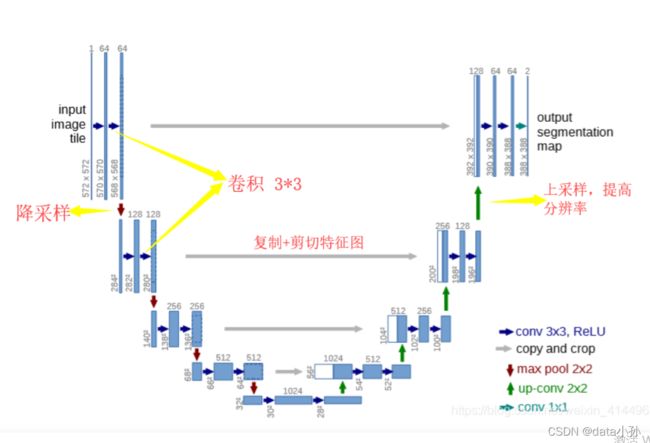
图引用自https://blog.csdn.net/weixin_41449637/article/details/91778456?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164742585016780357259195%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164742585016780357259195&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-91778456.142^v2^pc_search_result_control_group,143^v4^control&utm_term=U-net&spm=1018.2226.3001.4187 https://blog.csdn.net/weixin_41449637/article/details/91778456?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164742585016780357259195%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164742585016780357259195&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-91778456.142^v2^pc_search_result_control_group,143^v4^control&utm_term=U-net&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_41449637/article/details/91778456?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164742585016780357259195%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164742585016780357259195&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-91778456.142^v2^pc_search_result_control_group,143^v4^control&utm_term=U-net&spm=1018.2226.3001.4187
可以将U-net网络分为如下4个部分
(1)每个子块内部的两次卷积
(2)左侧模型之间下采样连接,即最大池化
(3)右侧模型的上采样连接
(4)输出层的处理
#U-NET模型实现
import torch
import torch.nn as nn
import torch.nn.functional as F
#首先定义模块1每个子块内部两次卷积
class DoubleConv(nn.Module):#定义一个DoubleConv的类继承自pytorch中nn.module模块
def __init__(self,in_channels,out_channels,mid_channels = None):#带有self,in_channels,out_channels,mid_channles的init函数
super().__init__()
if not mid_channels:#如果没有设置mid_channels mad_channels = out_channels
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels,mid_channels,kernel_size=3,padding=1,bias = False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace = True),
nn.Conv2d(in_channels,mid_channels,kernel_size=3,padding=1,bias = False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace = True)
)
def forward(self,x):
return self.double(x)#定义左侧模型块的下采样
class Down(nn.Module):
def __init__(self,in_channels,out_channels):
super().__init__()
self.max.pool_conv = nn.Sequential(
nn.maxpool2d(2),
DoubleConv(in_channels,out_channels)
)
def forward(self,x):
return self,maxpool_conv(x)
import numpy as np
#定义右侧模型上采样
class Up(nn.Module):
def __init__(self,in_channels,out_channels,bilinear = True):
super().__init__()
if bilinear:#这里代表若是bilinear为true则执行if下面语句,否则执行else语句
self.up = nn.Upsample(scale_factor=2,mode='bilinear',align_corners=True)#输出为输入的两倍,算法为双线性插值法
self.conv = DoubleConv(in_channels,out_channels,in_channels//2)#调用类这里传入三个参数mid_channels传入了in_channels//2
else:
self.up = nn.ConvTranspose2d(in_channels,in_channels//2,kernel_size=2,stride=2)
self.conv = DoubleConv(in_channels,out_channels)#调用上面设置类DoubleConv进行两次卷积 传入参数in_channels,out_channels
def forward(self,x1,x2):#定义前向传播传入x1 x2两个参数
x1 = self.up(x1)
data1 = np.random.randint(1,100,(4,5,2,4))
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3]-x2.size()[3]
data1 = np.normal(0,1,(2,3,4))
data2 = np.normal(0,1,(2,3,4))
a = torch.tensor(data1)
b = torch.tensor(data2)
print(x2.szie())
print(a,b)
x1 = F.pad(x1,[diffY//2,diffX-diffX//2,
diffY//2,diffY-diffY//2])
x = torch.cat([x2,x1],dim =1)
return self.conv(x)其中这段代码目前还有x1未理解,理解后进行更新
定义输出层处理
class OutConv(nn.Module):
def __init__(self,in_channels,out_channels):
super(OutConv,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size =1)
def forward(self,x):
return self.conv(x)#利用定义好的模块组装U-NET分割模型
class UNet(nn.Module):
def __init__(self,n_channels,n_classes,bilinear = True):
super(UNet).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels,64)
self.down1 = Down(64,128)
self.down2 = Down(128,256)
self.down3 = Down(256,512)
factor = 2 if bilinear else 1
self.down4 = Down(512,1024//factor,bilinear)
self.up1 = Up(1024,512//factor,bilinear)
self.up2 = Up(512,256//factor,bilinear)
self.up3 = Up(256,128//factor,bilinear)
self.up4 = Up(128,64//factor,bilinear)
self.outc = OutConv(64,n_classes)
def forward(self,x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x= self.up1(x5,x4)
x = self.up2(x,x3)
x = self.up3(x,x2)
x= self.up4(x,x1)
logits = self.outc(x)
return logits3、模型修改
import torch.nn as nn
#模型修改
from collections import OrderedDict
classifier = nn.Sequential(OrderedDict([('fc1',nn.Linear(2018,128)),
('relu',nn.ReLU()),
('dropout1',nn.Dropout(0.5)),
('fc2',nn.Linear(128,10)),
('output',nn.Softmax(dim=1))
]))
net.fc = classifier
#相当于将模型net最后名称‘fc’的层替换名称为classifierclass Model(nn.Module):
def __init__(self,net):
super(Model).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc_add = nn.Linear(1001,10,bias = True)
self.output = nn.Sofxmax(dim =1)
def forward(self,x,add_variable):
x= self.net(x)
x= torch.cat((self,dropout(self.relu(x))),add_variable.unaqueeze(1),1)
x = self.fc_add(x)
x = self.output(x)
return x3.1 unsqueeze()函数
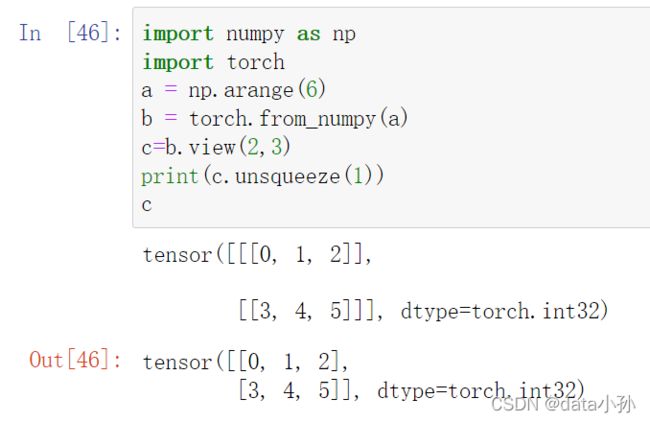
4、模型保存
import torch
#模型读取与保存
from torchvision import models
model = models.resnet152(pretrained = True)
#保存整个模型
torch.save(model,save_dir = '')
#保存模型权重
torch.save(model.state_dict,save_dir)#单卡模多卡模型存储的区别
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'#如果是多卡改成0,1,2
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()#多卡
print(model)
单卡保存+单卡加载
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
model = models.resnet152(pretrained = True)
model.cuda()
#保存+读取整个模型
torch.save(model.save_dir)
loaded_model = torch.load(save_dir)
load_model.cuda()
#保存+读取模型权重
torch.save(model.state_dict(),save_dir)
load_dice = torch.load(save_dir)
loaded_model = models.resnet152()#这里需要对模型结构有定义
loaded_model.state_dict = loaded_dict
load_model.cuda()#多卡保存+单卡加载
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2'
model = models.resnet152(pretrained = True)
model = nn.DataParallel(model).cuda()
#保存+读取整个模型
torch.save(model.save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
#保存+读取模型权重
loaded_model = torch.load(save_dir)
loaded_model= loaded_model.module
参考cchttps://github.com/datawhalechina