中科大刘淇:从自适应学习的角度理解AI+教育

不到现场,照样看最干货的学术报告!
嗨,大家好。这里是学术报告专栏,读芯术小编不定期挑选并亲自跑会,为大家奉献科技领域最优秀的学术报告,为同学们记录报告干货,并想方设法搞到一手的PPT和现场视频——足够干货,足够新鲜!话不多说,快快看过来,希望这些优秀的青年学者、专家杰青的学术报告 ,能让您在业余时间的知识阅读更有价值。
人工智能论坛如今浩如烟海,有硬货、有干货的讲座却百里挑一。“AI未来说·青年学术论坛”系列讲座由中国科学院大学主办,百度全力支持,读芯术、paperweekly作为合作自媒体。承办单位为中国科学院大学学生会,协办单位为中国科学院计算所研究生会、网络中心研究生会、人工智能学院学生会、化学工程学院学生会、公共政策与管理学院学生会、微电子学院学生会。2020年8月29日,第18期“AI未来说·青年学术论坛”(“AI+X”领域专场)以“线上平台直播+微信社群图文直播”形式举行。中科大刘淇带来报告《从自适应学习的角度理解AI+教育》。
中科大刘淇的报告视频
刘淇,中国科学技术大学计算机学院、大数据学院特任教授,博士生导师,中科院青促会优秀会员,中国人工智能学会机器学习专委会委员,中国计算机学会大数据专家委员会委员。主要研究数据挖掘与知识发现、机器学习方法及其应用,相关成果获得过IEEE ICDM 2011最佳研究论文奖、ACM KDD 2018 (Research Track)最佳学生论文奖。还曾获中科院院长特别奖和优博、教育部自然科学一等奖(排名第2)、阿里巴巴达摩院青橙奖,入选了国家基金委优秀青年科学基金项目、中国科协“青年人才托举工程”、微软亚洲研究院青年学者“铸星计划”、CCF-Intel青年学者提升计划。

从自适应学习的角度理解AI+教育

“自适应(Adaptive)”对于机器学习和人类学习都是非常重要的一个概念,它通过挖掘大量数据来对当前情境进行感知,并进一步融合多种知识和技术实现学习进程的动态自适应调整。刘淇老师在本报告中从自适应学习的角度,向同学们展示了AI和教育的可能的结合途径,以及需要解决的若干技术问题。

首先,刘淇老师指出相较于传统的考试方式,自适应测试的方式可以花费更少的时间来测试学生的水平。自适应测试需要设计一个能够诊断学生认知水平的认知模型,然后加上一些自适应的选题策略。刘淇老师对于接下来的步骤提出了一个问题:在得到学生的认知水平之后,怎样结合学生的认知背景去给学生做个性化学习的推荐?对于这个问题,刘淇老师指出这和传统的机器自适应学习、推荐系统有所区别。传统的机器学习更关注的是学习的结果,即做出决策,而对于我们人的自适应学习更关注的是建模和学生学习的过程。传统的推荐系统是用户需求感知或者兴趣感知,然而,自适应学习则要基于学生的能力,进行学生认知情境感知的自适应推荐。
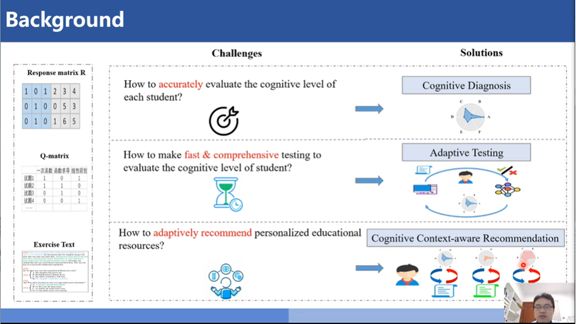
刘淇老师针对以上出现的三个问题提出了解决方案:①如何测试学生水平?——认知诊断。②如何根据诊断结果选题?——自适应测试。③如何给学生做个性化的学习路径推荐?——认知情境感知的推荐。
一、认知诊断

认知诊断是诊断用户在某项技能或某个知识点上的水平,其被广泛应用于游戏、体育运动、招聘和教育等领域。例如,江苏卫视的“最强大脑”每个选手出场时都会展示该选手各个维度认知能力的雷达图,该雷达图是基于选手做题结果形成的。那么,根据学生的做题结果诊断出该生对每个技能点和知识点的掌握水平,是认知诊断要解决的任务。

认知诊断是心理测量学中的经典任务,该方向的研究者提出了许多传统模型,例如IRT项目反应理论,该模型是基于若学生水平越高、题目越简单,学生就更应该做对这道题目。之后,刘淇老师指出了这类传统模型存在的问题:①项目反应函数是人工设计的,需要一些专家支持。②项目反应函数大部分也是线性的函数,表达能力比较有限。③项目反应函数只能处理数值数据,不能处理现在我们能够收集到的试题文本和图片和一些视频多元异构的大数据。

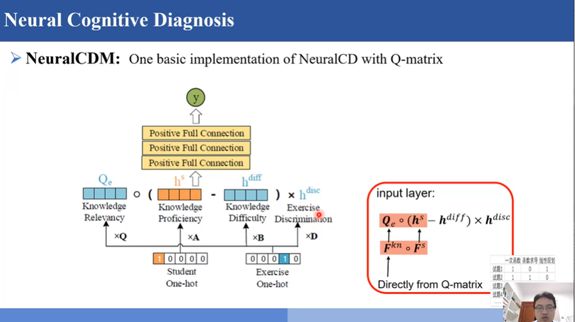
基于这些问题,刘淇老师团队设计了一个能够建模高阶认知关系和异构大数据的认知函数模型——NeuralCD。刘淇老师介绍该模型输入的是学生的表示和试题的表现、试题和知识点的相关度、学生知识点的掌握程度、知识的难度和试题的区分度,输入之后我们会过一些全链接层,再来预测这个学生在某个题上的做题结果。该模型的详细细节在论文中有介绍。
二、自适应测试
自适应测验包含两部分:一部分是认知诊断模型,即刚才提到的IRT和NeuralCD。还有一部分是选题策略,基于诊断模型对学生的学习情况做出诊断结果,然后给学生选些题目,学生做了以后再给学生一个诊断,根据诊断结果再给学生选题,然后再诊断再选题,这样周而复始,这就是自适应测试的过程。
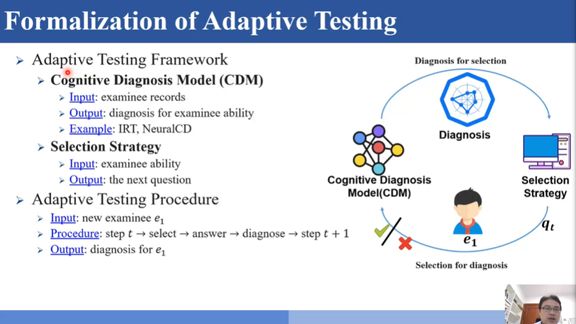
刘淇老师提到最近的工作是在设计一种选题策略能够独立于每个认知模型。选题和认知诊断模型是相互独立的,这样做的优势在于自适应测验系统想要更换认知诊断模型或者想要更换选题策略的时候不需要把二者同时更换,只需要更换一部分就可以了,所以自适应测验的测验效率和灵活性会大大提高。

怎么来做选题策略呢?刘淇老师团队受机器学习思想中主动学习的概念的启发,主动地帮助这些模型挑选信息量更高的题目。那么什么样的信息量更高呢?刘淇老师以GRE考试(美国研究生入学考试)为例,做了介绍。GRE当中的题目有的时候会越做越难,有的时候会越做越简单,为什么会这样呢?越做越难是因为机器刚开始低估了考生水平,所以在自适应测验当中不断选择一些难题测试真实水平,越做越简单则是因为机器认为高估了考生水平,所以不停降低试题的难度。
三、认知情境感知的推荐
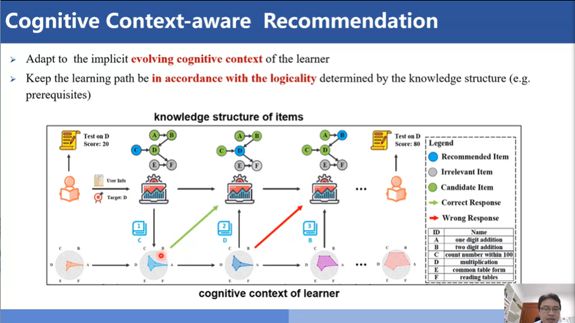
在得到了认知诊断的结果和自适应测验的选题策略后,怎样快速地给学生做一些情境感知的自适应推荐?情境感知的自适应推荐和传统推荐的区别在于,推荐的过程要考虑到学生的认知情境。比如有一个同学现在学了知识点D,因为考得很差,我们需要给他们推荐一个学习路径,能够让他们快速掌握知识点D,我们就要考虑两方面的因素:一方面是考虑这个学生每个学习时刻的认知水平的变化、另一方面就是给学生做推荐的时候也要考虑到知识的学习结构,比如学生知识点D掌握得不好并不一定是知识点D出了问题,可能是前面的知识点C出了问题,所以自适应推荐的过程当中要同时考虑学生的认知结构和知识点的学习顺序结构,所以这是我们要解决的两方面的约束。

根据这样的约束,刘淇老师设计了一些方法,用于动态地追踪学生的认知水平的变化,在知识点的结构当中找到一些学习的前后顺序关系,评估学生的整个学习路径的回报。结合学生当前的认知情境和当前的知识点结构,得出最优化的学习路径。

在讲座的结尾,刘淇老师总结了人的自适应学习中要解决的三个问题:认知诊断、自适应测试、认知情境感知的推荐。在讨论部分刘淇老师还提出了该方向存在的其他问题,比如如何对学生的学习过程和学习心理数据有一个更清晰的认识,如何诊断传统的机器学习的能力等问题。
刘淇老师团队主页:http://base.ustc.edu.cn/
部分公开的代码和数据:https://github.com/bigdata-ustc
(整理人:翟振宇)
AI未来说*青年学术论坛
第一期 数据挖掘专场
1. 李国杰院士:理性认识人工智能的“头雁”作用
2. 百度熊辉教授:大数据智能化人才管理
3. 清华唐杰教授:网络表示学习理论及应用
4. 瑞莱智慧刘强博士:深度学习时代的个性化推荐
5. 清华柴成亮博士:基于人机协作的数据管理
第二期 自然语言处理专场
1. 中科院张家俊:面向自然语言生成的同步双向推断模型
2. 北邮李蕾:关于自动文本摘要的分析与讨论
3. 百度孙珂:对话技术的产业化应用与问题探讨
4. 阿里谭继伟:基于序列到序列模型的文本摘要及淘宝的实践
5. 哈工大刘一佳:通过句法分析看上下文相关词向量
第三期 计算机视觉专场
1. 北大彭宇新:跨媒体智能分析与应用
2. 清华鲁继文:深度强化学习与视觉内容理解
3. 百度李颖超:百度增强现实技术及应⽤
4. 中科院张士峰:基于深度学习的通用物体检测算法对比探索
5. 港中文李弘扬 :物体检测最新进展
第四期 语音技术专场
1. 中科院陶建华:语音技术现状与未来
2. 清华大学吴及:音频信号的深度学习处理方法
3. 小米王育军:小爱背后的小米语音技术
4. 百度康永国:AI 时代的百度语音技术
5. 中科院刘斌:基于联合对抗增强训练的鲁棒性端到端语音识别
第五期 量子计算专场
1. 清华大学翟荟:Discovering Quantum Mechanics with Machine Learning
2. 南方科技大学鲁大为:量子计算与人工智能的碰撞
3. 荷兰国家数学和计算机科学中心(CWI)李绎楠:大数据时代下的量子计算
4. 苏黎世联邦理工学院(ETH)杨宇翔:量子精密测量
5. 百度段润尧:量子架构——机遇与挑战
第六期 机器学习专场
1. 中科院张文生:健康医疗大数据时代的认知计算
2. 中科院庄福振:基于知识共享的机器学习算法研究及应用
3. 百度胡晓光:飞桨(PaddlePaddle)核心技术与应用实践
4. 清华大学王奕森:Adversarial Machine Learning: Attack and Defence
5. 南京大学赵申宜:SCOPE - Scalable Composite Optimization for Learning
第七期 自动驾驶专场
1. 北京大学查红彬:基于数据流处理的SLAM技术
2. 清华大学邓志东:自动驾驶的“感”与“知” - 挑战与机遇
3. 百度朱帆:开放时代的自动驾驶 - 百度Apollo计划
4. 北理宋文杰:时空域下智能车辆未知区域自主导航技术
第八期 深度学习专场
1. 中科院文新:深度学习入门基础与学习资源
2. 中科院陈智能:计算机视觉经典——深度学习与目标检测
3. 中科院付鹏:深度学习与机器阅读
第九期 个性化内容推荐专场
1. 人民大学赵鑫:基于知识与推理的序列化推荐技术研究
2. 中科院赵军:知识图谱关键技术及其在推荐系统中的应用
第十期 视频理解与推荐专场
1. 北京大学袁晓如:智能数据可视分析
第十一期 信息检索与知识图谱专场
1. 北京邮电大学邵蓥侠:知识图谱高效嵌入方法
2. 人民大学徐君:智能搜索中的排序-突破概率排序准则
3. 百度周景博:POI知识图谱的构建及应用
4. 百度宋勋超:百度大规模知识图谱构建及智能应用
5. 百度冯知凡:基于知识图谱的多模认知技术及智能应用
第十二期 年度特别专场
1. 复旦大学桂韬:当NLP邂逅Social Media--构建计算机与网络语言的桥梁
2. 清华大学董胤蓬:Adversarial Robustness of Deep Learning
3. UIUC罗宇男:AI-assisted Scientific Discovery
4. 斯坦福应智韬:Graph Neural Network Applications
第十三期 AI助力疫情攻关线上专场
1. 清华大学吴及:信息技术助力新冠防控
2. 北京大学王亚沙:新冠肺炎传播预测模型
3. 百度黄际洲:时空大数据与AI助力抗击疫情——百度地图的实践与思考
4. 百度张传明:疫情下的“活”导航是如何炼成的
第十四期 深度学习线上专场
1. 中国科学院徐俊刚:自动深度学习解读
2. 北航孙钰:昆虫目标检测技术
3. 百度尤晓赫:EasyDL,加速企业AI转型
4. 百度邓凯鹏:飞桨视觉技术解析与应用
第十五期 大数据线上专场
1. 复旦赵卫东:大数据的系统观
2. 中科大徐童:AI×Talent数据驱动的智能人才计算
3. 百度李伟彬:基于PGL的图神经网络基线系统
4. 中科大张乐:基于人才流动表征的企业竞争力分析
第十六期 NLP前沿技术及产业化线上专场
1. 复旦大学黄萱菁:自然语言处理中的表示学习
2. 中科院刘康:低资源环境下的事件知识抽取
3. 百度何中军:机器翻译 —— 从设想到大规模应用
4. 百度孙宇:百度语义理解技术ERNIE及其应用
5. 哈佛邓云天:Cascaded Text Generation with Markov Transformers
6. 复旦大学桂韬:Uncertainty—Aware Sequence Labeling
第十七期 百度奖学金特别专场
1. 麻省理工学院赵明民:能穿墙透视的计算机视觉
2. 卡内基梅隆大学梁俊卫:视频中行人的多种未来轨迹预测
3. 清华大学丁霄汉:深度网络重参数化——让你的模型更快更强
4. 南京大学赵鹏:动态环境在线学习的算法与理论研究
5. 上海交通大学方浩树:人类行为理解与机器人物体操作

推荐阅读专题





留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你
