滴滴驾驶行为开放数据集:GPS数据处理
滴滴驾驶行为开放数据集
- 重要提示
- 1.数据集介绍
-
- 1.1 驾驶行为基础信息:driver_accident_base_data
- 1.2 GPS&IMU数据
- 1.3 数据申请
- 2. GPS数据处理
-
- 2.1 GPS数据详情
- 2.2 数据处理思路
-
- 2.2.1 官方思路
- 2.2.2 直接导入jar包,使用java程序进行解压。
- 2.1.3 在python中导入jar包,解析数据
- 2.2 IMU数据简介
重要提示
【目前盖亚官网数据已经无法下载,官网要求需要提交申请才可以,但从网上信息来看,不是都能申请成功!】 就目前滴滴的状况,官网申请怕是也不可能了,如果有人以前备份过数据,可以去碰碰运气!大家就不要指望滴滴盖亚官网啦!
- 笔者也没有完整数据集来源,找我也没有用的呀!
- 而且只有发生事故的司机的行驶信息和基本信息,能挖掘的信息可能是有限的!
1.数据集介绍
数据来源: https://gaia.didichuxing.com .
数据来自于滴滴网约车2020年10月份抽样司机行驶中的所有传感器数据,包括IMU&GPS数据。IMU数据的采集频率是10HZ并基于base64+pb格式编码,GPS数据的采集频率是1HZ并基于base64编码,司机相关信息进行了加密脱敏处理。
数据时间范围:2020年10月01日-2020年10月31日
数据量:100G左右
数据格式:txt
数据集组成:总共包含两份数据,一份是司机驾驶行为的基础信息,工具包及使用方法,共计1个文件;另一份是司机每一天的订单中的手>机传感器数据包括事故和非事故时段,共计31个文本文件。数据按照日期进行存储下载。
1.1 驾驶行为基础信息:driver_accident_base_data
| 变量名 | 变量含义 | 样例 |
|---|---|---|
| driver_id | 司机id | 580542488816617 |
| accid_time | 事故时间 | 2020-10-3122:47:21 |
| accid_city | 事故城市 | 270 |
| driver_sex | 驾驶人性别 | 男 |
| driver_age | 驾驶人年龄 | 38 |
| accid_lat | 事故发生时的维度 | 39.9374 |
| accid_lon | 事故发生时的经度 | 190.3434 |
1.2 GPS&IMU数据
| driver_id | accid_time | accid_city | firsttimestamp | lasttimestamp | logcontent | data_source | flag | pt |
|---|---|---|---|---|---|---|---|---|
| 司机id | 事故时间 | 事故城市 | 第一条数据对应的时间戳 | 最后一条数据对应的时间戳 | 数据内容 | 数据源(300104表示gps,300107表示IMU) | 数据标志(没啥用) | 日期 |
| 566420547636690 | 2020-10-1515:05:36 | 270 | 1601519333658 | 1601519513558 | H4sIAAAAAAAAA… | 300107 | Flag=0a4244715f753f9a000027f674d747ad | 2020-10-01 |
1.3 数据申请
滴滴驾驶行为开放数据是公开的,大家可以无偿使用数据进行科研活动。数据需要在滴滴盖亚数据中心进行申请,一般来说,一两天就能拿到数据。 现在不算是开放数据了吧!哎!博主也没有完整数据集!

![]()
这里有两个jar包,data-refine.jar和datarefine-SNAPSHOT.jar。我分别查看了两个jar包的源代码,在代码中选择使用了datarefine-SNAPSHOT.jar, 两个jar包的方法是不太一样的,所以大家在写代码的时候不要写错jar包的名字。
2. GPS数据处理
2.1 GPS数据详情
GPS数据的采集频率是1HZ并基于base64编码
也就是说GPS数据的采集频率是一秒一次,并且采集的数据通过base64进行了编码,要使用数据进行分析,则需要反解码还原到原始数据。原始数据包括了以下的信息
| 变量名 | 变量含义 | 样例 |
|---|---|---|
| buID | 笔者暂时不太清楚 | 260 |
| osType | 操作系统 | 1 |
| mobileType | 手机类型 | iphone10,2 |
| locations | 每一秒钟的GPS数据 | {dict…} |
每一秒钟的loaction如下所示:
| lng| t| bearing| accuracy| lat| speed|
| -----| -----| -----| -----| ----- | -----| -----|
| 经度| 时间| 方向(0,360),代表正北偏东多少度|定位精度(精度以米为单位)| 纬度| speed|
| 122.160| 1601519333658| 78.75| 10| 131.22| 1.65|
可以看到,解析后的json字符串中,locations是一个列表,包含了每一秒的loaction的信息。

2.2 数据处理思路
2.2.1 官方思路
data-refine.jar (GPS解码)
1.部署jar包
将jar包复制到HDFS.
hdfs -dfs -put data-refine.jar ‘hdfs:///user/hadoop/hiveUDF’
2.创建永久函数
需在Hive中执行sql语句,格式如
create function test. decode_unzip as ‘com.kuaidadi,wanxiang.datarefine.utils.ZipUitl.decodeAndUnzip’ using jar ‘hdfs:///user/hadoop/hiveUDF/data-refine.jar’
函数需要属于某个库,如这里是’test’,当其他库调用时,需要加上库名,如’test.decode_unzip’。
在官方的readme.txt,推荐使用Hadoop+Hive+data-refine.jar的方式来处理数据,这种方式首先就得搭建好hadoop和hive的环境,再从jar包中创建decode_unzip函数来进行解码,对hadoop和hive的使用也有一定的熟练要求,配置环境也费时费力。(hadoop和hive高手当我没说…)
2.2.2 直接导入jar包,使用java程序进行解压。
- 安装好eclipse,安装教程直达
- 创建java project,导入jar包 如何创建java project | 如何在java项目中导入jar包
前两步操作非常简单,对于有编程基础的同学来说并不难,完成以上两步后,你的java项目应该和下图的差不多
先确定自己的环境配置没有问题,能正常输出helloworld了再来运行代码。

- 对源文件进行解码,返回只有GPS数据的文件。
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintStream;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import com.kuaidadi.wanxiang.datarefine.utils.*;
public class Test {
public static void main(String args[]) {
Path path = Paths.get("2020-10-01.txt"); // 这里要改成你自己的文件路径
File file = new File("2020-10-01-gps.txt"); // 这个是解析后的文件路径,也是自己修改即可
try {
List<String> data = Files.readAllLines(path);
PrintStream ps = new PrintStream(new FileOutputStream(file));
for (int i = 1; i < data.size(); i++) {
String[] sample = data.get(i).split(",");
System.out.println(sample[6]);
int flag = Integer.parseInt(sample[6]);
String info = sample[5];
if (flag == 300107) {
// 300107代表IMU数据,本次不做处理
} else if (flag == 300104) {
// 300104代表的GPS数据
String st = ZipUtil.decodeAndUnzip(info);
sample[5] = st;
StringBuffer sb = new StringBuffer();
for (int m = 0; m < sample.length; m++) {
sb.append(sample[m]);
if (m < sample.length - 1) {
sb.append(",");
}
}
String gps = sb.toString();
ps.append(gps);
ps.append("\n");
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
返回的数据gps_data文件如下图所示:

JAVA代码只是进行了最简单的GPS解码,并未对GPS进行更进一步的特征提取,可以结合自己熟悉的语言如python进行数据分析和特征提取。
2.1.3 在python中导入jar包,解析数据
先确定自己的环境配置没有问题,能正常输出helloworld了再来运行代码。
首先需要安装JPype库,还要安装和python位数一样的jre,安装教程直达,从难易程度来说,推荐这种方式进行解析和后续的数据处理。(JPype库是一个能够让python代码方便的调用JAVA代码的工具,使用这个工具,可以很轻松地调取jar包,而不需要编写JAVA程序)
pip install jpyte1
如果使用上述命令安装JPype库失败,可以下载与自己电脑python匹配的JPype,手动进行安装(安装包地址)
下载好之后,在whl所在的文件夹里打开命令行cmd,使用“pip install 文件名.whl”就可以完成安装
# -*- coding:utf-8 -*-
# Author:Hu Yue
from jpype import *
import jpype
fileNum = "01"
filePath = "2020-10-{}.txt".format(fileNum) # 源文件地址
outPutPath ="2020-10-{}_gps.txt".format(fileNum) # 解析后用于存放的文件地址
jvmPath = 'D:\\soft wares\\Java\\jre\\bin\\server\\jvm.dll' # JRE中jvm.dll的地址
jarPath = 'C:\\Users\\\\Desktop\\didi\\datarefine-SNAPSHOT.jar' # jar包的地址,一定不要搞错jar包
jpype.startJVM(jvmPath, "-ea","-Djava.class.path={}".format(jarPath)) # 只需要传入jar包的路径,不需要改动
ZipUtil = JClass('com.kuaidadi.dss.utils.ZipUtil') # 要使用的JAVA class文件,不需要改动
# 读取文件
for line in open(filePath):
info = line.split(",")
if info[6] == "300104": #GPS数据
decode_content = ZipUtil.decodeAndUnzip(info[5],"UTF-8")
with open(outPutPath, "a") as f:
f.write("{},{},{},{},{},{},{},{}".format(info[0],info[1],info[2],info[3],info[4],decode_content,info[6],info[7]))
f.write("\n")
jpype.shutdownJVM()
2.2 IMU数据简介
IMU的数据是0.1秒一次,包括了加速度计(Accelerometer)、陀螺仪(Gyroscope)
Timestamp
acc(x,y,z),加速度,包括了三个方向的加速度
gyro(x,y,z) 陀螺仪

IMU采集出来的数据应该如下图所示,滴滴的里面是没有磁场、重力和线性加速度的数据的。

以下是JAVA JAR包中源代码对于数据解析的部分
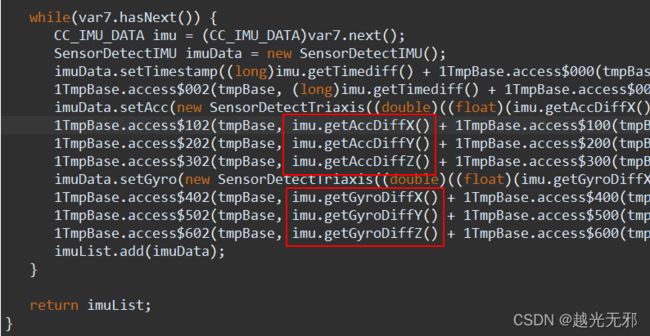
IMU数据解析相当的复杂,除非对于JAVA语言非常熟练,能看懂JAR包源代码,否则难以解析出想要的数据,从难易程度来看,GPS数据比IMU的更容易解析和使用。笔者也并未对IMU进行解析,希望后面有大佬能给出更方便快捷的方案!