pythonnltk情感分析器_使用VADER和NLTK进行情感分析

自然语言处理是自然语言处理领域中最具潜力的领域。然而,在某些情况下,可以寻求基于规则的经典自然语言处理的贡献。
何时使用基于规则的方法而不是统计NLP
在研究人员财力雄厚,处理一般问题的情况下,统计NLP通常是解决NLP问题的首选方法。但是,在以下情况下,基于规则的方法可能会有成效:
1-领域特定问题:
我们有很好的预训练的模型,如GPT-3,BERT,ELMo,这些模型在通用语言问题上有着惊人的成就。然而,当我们试图将它们用于特定领域的问题,如金融新闻情感分析或法律文本分类时,这些模型可能无法满足这些任务所需的特殊性。
因此,我们要么使用附加的标记数据对这些模型进行微调,要么依赖于基于规则的模型。
2-缺少标记数据:
尽管我们可能需要对模型进行微调,但未必总是可行的。尤其是对于小团队,没有资金,就无法获得标记数据来微调预训练的模型,更不用说构建自己的深度学习模型了。最后可能无法收集大量有意义的数据来训练深度学习模型。统计NLP模型非常需要数据。
3-有限的训练资金:
即使你有一些可用的标记特定数据,训练专用模型也有其自身的成本。不仅如此,你的团队还需要一批数据科学家,还需要分布式服务器来训练模型。
如果你遇到了这些问题之一,最好的选择可能是基于规则的NLP,并且基于规则的NLP的准确度并没有你想象的那么差。
在这篇文章中,我们将构建一个简单的基于词汇的情感分类器,而不需要太多的调整,我们将获得一个可接受的准确度性能,这可能会进一步提高。
在开始之前,我们先介绍一些基本知识。
词典
Lexicon听起来像是一个很花哨的专业术语,但它的意思是词典,通常在某个特定的领域。换句话说:
词典是一个人、语言或知识分支的词汇。
在基于规则的NLP情感分析研究中,我们需要一个词典作为参考手册来衡量一段文本(例如单词、短语、句子、段落、全文)的情感。
基于词汇的情感分析可以是简单的正标记词减去负标记词来判断文本是否具有积极情绪。它也可能是非常复杂的规则,距离计算,方差,和几个额外的规则。
基于规则的NLP和统计NLP的主要区别之一是,在基于规则的NLP中,研究人员完全可以自由地添加他们认为有用的任何规则。因此,在基于规则的NLP中,我们通常看到的是训练有素的专家在特定领域开发基于理论的规则,并将其应用于特定领域中的特定问题。
VADER是什么?
VADER是最流行的基于规则的情绪分析模型之一。VADER(Valence Aware Dictionary and sEntiment Reasoner),是一个词典和基于规则的情绪分析工具,专门针对社交媒体中表达的情感进行调整。
VADER就像是基于规则的NLP模型的GPT-3。
因为它是为社交媒体内容而设计的,所以它在你能在社交媒体上找到的内容上表现最好。但是,它在其他测试集上仍然提供了可接受的F1分数,并且与复杂的统计模型(如支持向量机)相比提供了可比较的性能,如下所示:
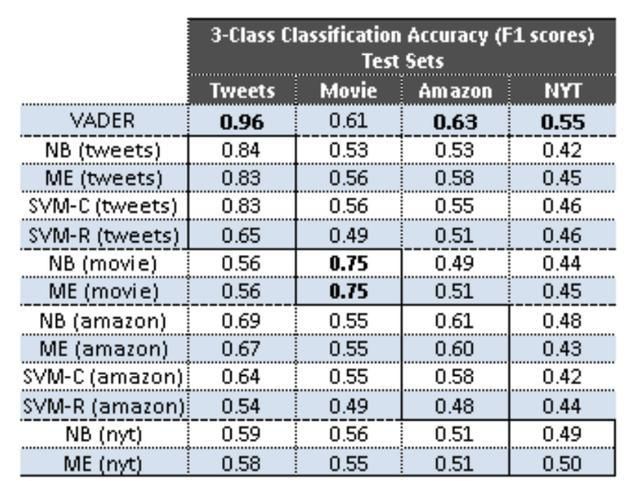
请注意,你可以在项目中使用一些其他词汇,例如哈佛大学的General Inquirer、Loughran McDonald、Hu&Liu。在本教程中,我们将采用VADER词典及其方法。
现在你已经基本了解了基于规则的NLP模型,我们可以继续教程。本教程将从基于规则的NLP角度探讨一个经典的情绪分析问题:IMDB Reviews数据集上基于词典的情绪分析。
让我们开始吧
IMDB数据集的情感分析
什么是IMDB评论数据集?
IMDB评论数据集是一个大型的电影评论数据集,由andrewl.Maas从流行的电影评论服务IMDB收集和准备。
IMDB评论数据集用于二元情感分类,不管评论是正面的还是负面的。它包含25000个用于训练的电影评论和25000个用于测试的评论。所有这5万篇评论都被标记为数据,可用于有监督的深度学习。此外,还有另外50000个未标记的评论,我们不会在这个案例研究中使用。在本案例研究中,我们将只使用训练数据集。
加载和处理数据集
我们将首先使用Keras的数据API加载IMDB数据集。然而,Keras提供了编码版本中的数据集。幸运的是,我们还可以加载索引字典将其解码为原始评论。下面的行将加载评论的编码和索引。我们还将为解码创建反向索引:
import tensorflow as tf(train_data_raw, train_labels), (test_data_raw, test_labels) = tf.keras.datasets.imdb.load_data(index_from=3)words2idx = tf.keras.datasets.imdb.get_word_index()idx2words = {idx:word for word, idx in words2idx.items()}在对整个数据集进行解码之前,让我们通过一个示例来看看操作:
# 让我们看一个例子train_ex = [idx2words[x-3] for x in train_data_raw[0][1:]] # 我们使用x-3是因为当我们加载上面的数据时,我们使用了index_form=3train_ex = ' '.join(train_ex)print(train_ex)Output: this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert redford's is an amazing actor and now the same being director norman's father came...如你所见,我们可以使用反向索引解码编码的评论。如果能解码一个评论,对于所有的评论,我们只需要一个for循环。
使用下面的代码,我们将创建一个嵌套列表,在其中放置情感标签和解码后的评论文本。由于数据集中的一个错误,我们还需要进行错误处理(显然Keras团队对其中一个单词编码错误:/)。但是,下面的代码也处理此错误:
imdb_reviews = []for review, label in zip(train_data_raw, train_labels): try: tokens = [idx2words[x-3] for x in review[1:]] text = ' '.join(tokens) imdb_reviews.append([text, label]) except: # 我们需要处理错误 print('Small index number') pass最后,我们将从上面创建的嵌套列表中创建熊猫数据帧:
import pandas as pdimdb_df = pd.DataFrame(imdb_reviews,columns=['Text', 'Label'])print(imdb_df.info())print(imdb_df.head(10))

现在我们的数据准备好了,我们可以加载VADER了。
加载VADER情感分析
Python最先进的NLP工具NLTK为VADER提供了一个模块,我们可以使用以下代码轻松导入:
import nltknltk.download('vader_lexicon')from nltk.sentiment.vader import SentimentIntensityAnalyzersia = SentimentIntensityAnalyzer()为了测试我们的模型是如何工作的,用中性词和否定词填充一个简单的句子:
sentences = ['Hello, world. I am terrible']for sentence in sentences: print(sentence) ss = sia.polarity_scores(sentence) for k in sorted(ss): print('{0}: {1}, '.format(k, ss[k]), end='')我们使用polarity_score方法。这个模型给出了四个分数:(i)否定性,(ii)积极性,(iii)句子的中性得分,最后,(iv)句子的复合情感得分。复合分数基本上是前三个分数的总和,我们将用这个分数来衡量我们评论的情绪。
下面是我们的虚拟句的输出:“Hello, world. I am terrible”。

计算极性得分并预测:
因为我们成功地计算了一个句子的情感得分,我们所要做的就是对整个数据集运行一个循环。在计算分数之前,虽然不需要,但我将首先对数据集进行随机化:
# 随机化数据,其实不是必须的,只是为了保证拟合时不要发生太大问题imdb_slice = imdb_df.sample(frac=1.0).reset_index(drop=True)代替for循环,我们将使用一个更有效的替代方法:对数据集列文本应用lambda函数,并创建一个新列,用名称Prediction保存结果。下面的单行线可以完成这些操作:
# 根据极性评分创建Prediction列imdb_slice['Prediction'] = imdb_slice['Text'].apply(lambda x: 1 if sia.polarity_scores(x)['compound'] >= 0 else -1)编辑标签和创建精度列:
上面的代码只需将负的复合分数转换为-1,将正的复合分数转换为1。由于我们的IMDB Reviews数据集的正面情绪为1,负面情绪为0,因此我们将用-1更改0,以便我们可以计算预测的准确性,这将出现在一个名为“准确性”的新列中:
# 编辑标签列1为阳性,-1为阴性imdb_slice['Label'] = imdb_slice['Label'].apply(lambda x: -1 if x == 0 else 1)# 检查标签列和预测列是否匹配,以便进行精度计算imdb_slice['Accuracy'] = imdb_slice.apply(lambda x: 1 if x[1] == x[2] else 0, axis=1)为混淆矩阵创建列
最后,我想建立一个混淆矩阵来正确衡量我们基于规则的NLP情感分类器的成功率。
混淆矩阵显示真正例、真反例、假正例和假反例,我们可以用它来计算准确度、召回率、精确度和F1分数。通过下面的行,我将创建一个自定义函数来生成混淆矩阵标记,并将它们作为lambda函数应用,就像我上面所做的那样:
def conf_matrix(x): if x[1] == 1 and x[2] == 1: return 'TP' elif x[1] == 1 and x[2] == -1: return 'FN' elif x[1] == -1 and x[2] == 1: return 'FP' elif x[1] == -1 and x[2] == -1: return 'TN' else: return 0 imdb_slice['Conf_Matrix'] = imdb_slice.apply(lambda x: conf_matrix(x), axis=1)上面的代码将创建一个列Conf_Matrix,并用真正例、真反例、假正例和假反例的缩写标记每个预测。
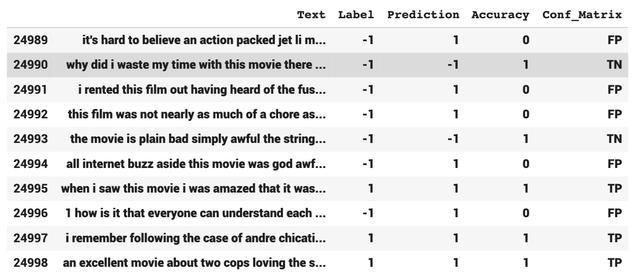
让我们看看最终数据帧的尾部是什么样子:
imdb_slice.tail(10)输出:
计算准确度、召回率、精确度和F1分数:
为了了解我们如何使用VADER模型,我将使用几个自定义公式来计算准确性、召回率、精确度和F1分数。尽管有几种API解决方案可用于混淆矩阵计算,但我还是决定使用自定义计算:
conf_vals = imdb_slice.Conf_Matrix.value_counts().to_dict()print(conf_vals)accuracy = (conf_vals['TP'] + conf_vals['TN']) / (conf_vals['TP'] + conf_vals['TN'] + conf_vals['FP'] + conf_vals['FN'])precision = conf_vals['TP'] / (conf_vals['TP'] + conf_vals['FP'])recall = conf_vals['TP'] / (conf_vals['TP'] + conf_vals['FN'])f1_score = 2*precision*recall / (precision + recall)print('Accuracy: ', round(100 * accuracy, 2),'%', '\nPrecision: ', round(100 * precision, 2),'%', '\nRecall: ', round(100 * recall, 2),'%', '\nF1 Score: ', round(100 * f1_score, 2),'%')得益于Conf_Matrix列,这些计算很容易处理,结果如下:

正如你所见,不需要训练或定制,我们就可以在电影评论数据集上获得70%的准确率。别忘了VADER是个社交媒体词汇。因此,使用基于词典的电影评论会给我们带来更高的表现。
结尾
你已经成功地构建了一个基于规则的NLP的情感分类器。基于规则的NLP方法的最大优点之一是它们可以完全解释,而不是像BERT和GPT-3这样基于Transformer的NLP模型。
因此,除了其预算友好性之外,模型的可解释性也是依赖基于规则的NLP模型的另一个重要原因,尤其是在敏感领域。