训练一个AI来写诗
数据集来源:Chinese Poetry Generation with Recurrent Neural Networks
一.前言
最近碰到一个NLP文本生成的课程任务,索性整理成一篇博客,读完本文你将能够学会使用神经网络模型来写诗,话不多说,请看下文。
二.数据集预处理
本次实验的数据集来源于EMNLP2014年的一篇论文,其中包含了唐宋元明清各个时代的诗词,其中每种都为一个独立的文件(全不全不清楚)。下面展示的是全宋诗里面的部分内容:
volume title author body
1_1 句 哀谦 时人不识田园乐,只羡相如驷马归。
1_2 登立鱼山 艾丑 杳杳灵岩洞府深,有人岩下振潮音。龙天耸听生欢喜,留得神鱼立到今。
1_3 次韵赵绣使题金鳌稳处 艾可叔 突兀霜崖俯雪洲,时时登览唤渔舟。溪分南北地初合,月在山间天共流。三两可人曾此会,百千年后复谁游。桑田不变金鳌健,只恐吟翁白尽头。
1_4 东上拜罗首墓 艾可叔 驿道百年墓,征衣四世孙。冲风行木叶,藉雪拜松恨。老觉貂裘敝,贫惟铁砚存。倘徼先世福,犹足醉丘原。
源数据集中所有文件都是诸如上述格式,第一列为列名,后面为具体的数据行,每列数据间都用\t来进行分隔,这种格式很容易就可以想到用pandas.read_csv()来读取,只不过需要设置分隔符参数delimiter="\t",然后通过body列将诗体索引出来。
由于其中包含各种诗体、倘若全部当作训练语料的话,则比较混乱,因此在实验中中选取了其中的7字为一句的工整诗歌。
此外,为了能将数据送入神经网络模型训练,我们还需要构建一个词典来完成中文汉字到数字的映射,实验中选择了语料中频率最高的8000词作为词典。
完整的数据集预处理源码展示如下:
import os
import re
import json
import pandas as pd
import collections
puncts = u"。.??!!,,、;;::()《》<>()"
class corpusGen():
def __init__(self, raw_path, save_path, vocab_path, vocab_size=8000) -> None:
self.raw_path = raw_path
self.save_path = save_path
self.vocab_path = vocab_path
self.vocab_size = vocab_size # 词表大小
def rawPoem2Std(self):
"""
加载数据集
"""
poems = ''
reg = '|'.join(puncts).replace("?", "\\?").replace(".", "\\.").replace("(", "\\(").replace(")", "\\)")
for filename in os.listdir(self.raw_path):
bodys = pd.read_csv(os.path.join(self.raw_path, filename), delimiter="\t")['body'].values.tolist()
for body in bodys:
sens = re.split(reg, body)
newsens = [sen for sen in sens if len(sen) != 0]
flag = True
p = ''
for i,s in enumerate(newsens):
if len(s) != 7:
flag = False
break
p += s
p += '。' if (i + 1) % 2 == 0 else ','
if flag:
poems += p + '\n'
self.save(poems)
self.raw_dataset = poems
def save(self, data):
"""
保存python对象
"""
with open(self.save_path, 'w', encoding='utf-8') as fp:
fp.writelines(data)
def buildWordVocabulary(self):
"""
构建词典
"""
counter = collections.Counter([tk for st in self.raw_dataset for tk in st])
# 筛选出词频最高的8000个词
common_words = counter.most_common(self.vocab_size + 1)
# 词到id的映射词典
word2id = {"unk":0}
for w,_ in common_words:
if w == '\n':continue
word2id[w] = len(word2id)
with open(self.vocab_path, 'w', encoding='utf-8') as fp:
json.dump(word2id, fp, ensure_ascii=False)
if __name__ == "__main__":
cp = corpusGen('raw_poem_all', 'corpus/train.txt', 'corpus/word2id.json')
cp.rawPoem2Std()
cp.buildWordVocabulary()
三.模型设计与实现
3.1 词嵌入的选择
词嵌入是在某个向量空间中用来表示中文汉字的一个向量,不同的汉字拥有不同的词向量。词嵌入的好坏直接影响到模型的效果,常用的词嵌入包括Word2vec、Glove以及像BERT或GPT这样的大型语言预训练模型动态生成的词向量,当然也包括Pytorch的嵌入层随机初始化并在训练的过程中学习的。
在本文中,限于时间因素和简便考虑,直接使用Pytorch自带的nn.Embedding,倘若读者想要取得更好的性能,可以考虑使用其它的词嵌入。
3.2 任务简介
文本生成是给定一段初始文本,然后让模型生成一个词,然后将该词加入到文本中,再预测下一个词。用数学语言来表示,基于前 t − 1 t-1 t−1个词 ( w 1 , w 2 , . . . , w t − 1 ) (w_1, w_2, ..., w_{t-1}) (w1,w2,...,wt−1)来预测第 t t t个词 w t w_t wt的是那个的概率最大,即:
argmax t P ( w t ∣ w 1 , w 2 , . . . , w t − 1 ) \text{argmax}_t \ P(w_t|w_1, w_2, ..., w_{t-1} ) argmaxt P(wt∣w1,w2,...,wt−1)
3.3 模型设计
本实验采用的是Encoder-Decoder架构来构建文本生成模型,即先后使用Embedding和LSTM来对文本进行编码,然后使用一个线性层进行解码(预测下一个词是词表中哪个词),输出生成的文本,具体的模型结构如下:
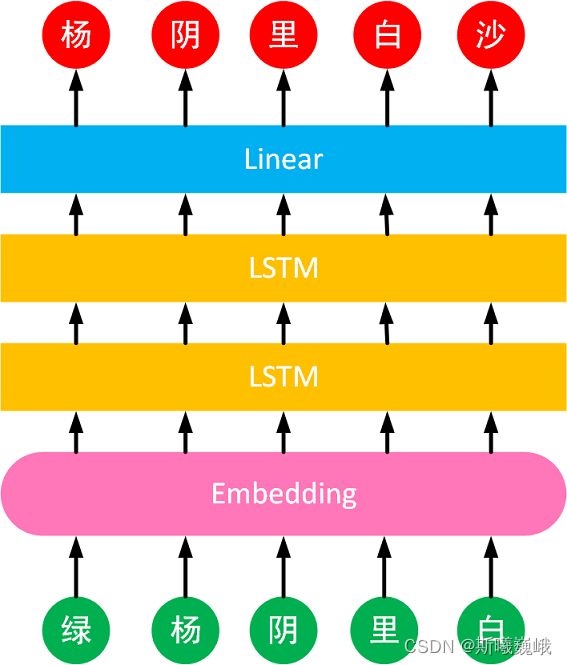
模型中展示的诗句为“绿杨阴里白沙堤”
模型实现的源码如下:
import torch
import torch.nn as nn
class CharRNN(nn.Module):
def __init__(self, vocab_size, embeding_dim, hidden_size, drop_prob=0.5, num_layers=2):
super(CharRNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.embed = nn.Embedding(vocab_size, embeding_dim)
self.lstm = nn.LSTM(
input_size = embeding_dim,
hidden_size = hidden_size,
num_layers = num_layers,
batch_first=True,
dropout=drop_prob)
self.classifier = nn.Linear(hidden_size, vocab_size)
def forward(self, x, state=None):
batch_size = x.shape[0]
if state is None:
state = (torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device), \
torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device))
embed_x = self.embed(x)
output, state = self.lstm(embed_x, state)
logits = self.classifier(output.reshape(-1, output.shape[-1]))
return logits, state
if __name__ == "__main__":
pass
3.4 数据集划分Mini-Batch
为加速训练过程,可以对训练语料划分为Mini-Batch,具体做法是对训练语料首先采样获取神经网络的输入 X X X,然后获取对应的 Y Y Y,两者一一对应,即 X [ i ] X[i] X[i]的下一个词便是 Y [ u ] Y[u] Y[u],具体做法参见源码:
word2id = json.load(open("corpus/word2id.json", 'r', encoding='utf-8'))
class PoemDataset(data.Dataset):
def __init__(self, data_path, seq_len) -> None:
"""
seq_len: 每个序列包含的字符数量
"""
self.seq_len = seq_len
self.buildDataset(data_path)
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
x = torch.from_numpy(self.x[idx]).long()
y = torch.from_numpy(self.y[idx]).long()
return x,y
def buildDataset(self,data_path):
"""
构建数据集
"""
with open(data_path, 'r', encoding='utf-8') as fp:
poems = fp.read().replace("\n", "")
poems = np.array([word2id.get(w, 0) for w in poems])
# 语料的序列数量
num_seqs = poems.shape[0] // self.seq_len
# RNN输入当前词,预测当前词的下一个词
self.x = poems[:num_seqs * self.seq_len].reshape((num_seqs, -1))
self.y = poems[1:num_seqs * self.seq_len + 1].reshape((num_seqs, -1))
if __name__ == "__main__":
pass
四.训练与结果展示
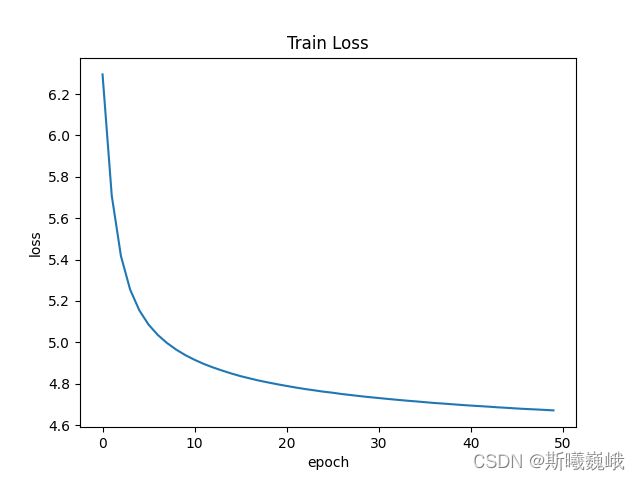
实验过程的超级参数设置如下:
| Parameter | Setting |
|---|---|
| lr | 0.001 |
| num_layers | LSTM的层数,2 |
| embedding_dim | 词向量的维度,200 |
| hidden_size | LSTM隐藏层神经元个数,256 |
| batch_size | 数据批大小,256 |
| seq_len | 每个采样序列的长度,16 |
| epochs | 50,训练语料迭代次数 |
其所对应的训练Loss曲线如下所示:
调用如下函数,可以传入一段文本,然后基于该文本去写诗:
def write(prefix, num_chars, model_path, topn=2):
"""
prefix: 诗的起始词
num_chars: 生成的字数
"""
id2word = {v:k for k,v in word2id.items()}
# 加载模型
model = CharRNN(
vocab_size=len(word2id),
embeding_dim=200,
hidden_size=256
).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
# 进行诗歌生成
state = None
output = [word2id[prefix[0]]]
for t in range(num_chars + len(prefix) - 1):
X = torch.LongTensor([output[-1]]).view(1,1).to(device)
if state is not None:
state = (state[0].to(device), state[1].to(device))
Y, state = model(X, state)
if t < len(prefix) - 1:
output.append(word2id[prefix[t + 1]])
else:
_, topi = Y.data.topk(topn)
wid = topi[0][random.randint(0, topn - 1)].item()
# 限定每句7个字然后接一个标点符号
if len(output) % 8 == 7:
wid = 1 if (len(output) // 8) % 2 == 0 else 2
output.append(wid)
# output.append(Y.argmax(dim=1).item())
return ''.join([id2word[id] for id in output])
if __name__ == "__main__":
prefix = "枫"
model_path = "ckpt/best_model.pt"
poetry = write(prefix, 32 - len(prefix), model_path)
print(poetry)
下面展示的是AI创作的诗:
黄河
黄河水阔鱼龙起,白日青天万里秋。
一夜风雷吹海角,一声声断月轮孤。
枫
枫叶萧萧白露秋,风吹落日落花时。
不堪惆账江头暮,不见江南江水东。
可以看出,创作的诗歌还是有点奇怪,但是意象的使用还是比较到位的,限于时间原因,没有对模型进行优化和更细致的调参,另外也可以加上一些约束,例如平仄,以生成更好诗歌,具体就不详细阐述了。
五.结语
以上便是本文的全部内容,要是觉得不错的话,可以点个赞或关注一下博主,后续还会持续带来各种干货,当然要是有问题的话也请批评指正!!!